基础数学课25 文本聚类算法
我们这一张看下向量空间如何在实际中落地的。
在概率统计模块中,我们介绍了分类和回归两种监督式学习,监督式学习主要目的是通过训练学习资料并建立一个模型,根据模型来进行预测。
除此外还有着非监督学习这种应用场景。需要由机器自己对训练样本进行归类,然后进行自我训练,那么如何进行归类,就是非监督学习首先要考虑的。对于分类,这里可以考虑使用我们之前应用的向量空间,并加上其中的距离和相似性两种概念,从而进行划分。
这里我们看一个具体的聚类算法,K-Means算法。这个算法可以让我们在一个任意多的数据集之中,获取到K个聚集。
这种算法的核心思想是 尽可能最大化群组内的相似度,同时最小化群组之间的相似度。从而进行划分。
其核心流程大致总结如下
- 从N个数据对象中随机选取K个对象作为质心
- 对于剩余的对象,测量其和每个质心的相似度,然后进行归类。
- 之后重新计算各个群组的质心,这里的质心的计算是关键,如果使用特征向量表示的数据对象,那么就是获取群组中的成员的特征向量,并使用平均值来作为质心表示。
- 然后不断的迭代2,3步骤,直到新的质心和原本质心相等或者相差之值小于指定阈值。
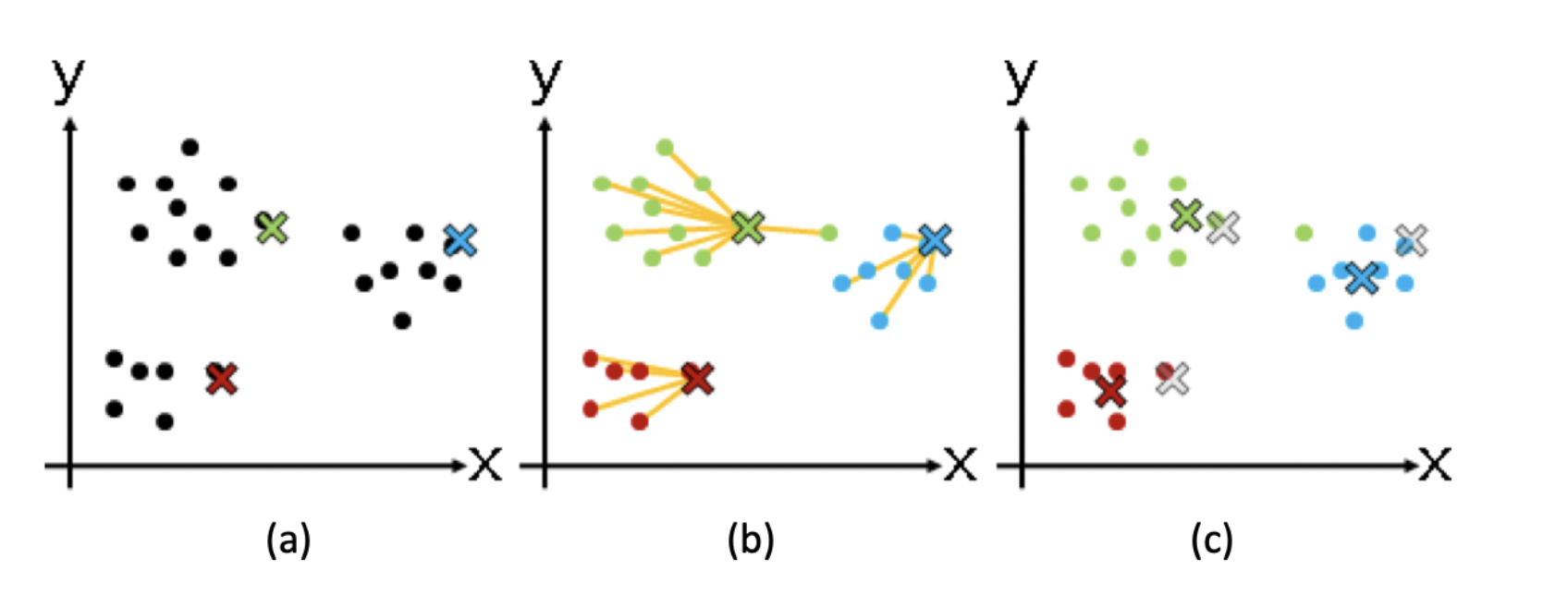
A 表示标记质心
B 表示开始进行聚类
C 表示计算新的质心
那么我们以一个实际的新闻分类来看下整体的流程
首先是将所有的文档集合转换为向量的方式
然后使用K均值算法进行聚类,确定数据对象和分组质心之间的相似度。其主要就利用了距离和夹角余弦度量进行获取的。
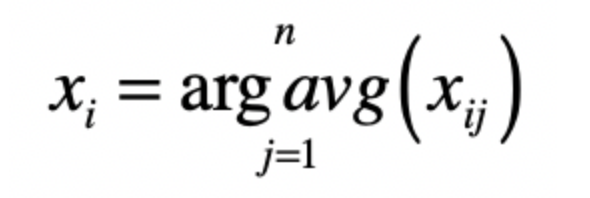
最后选择和质心相似的几篇文章作为代表,其他进行过滤。
这里进行下演示
这里利用Python中的scikit-learn,进行测试
利用sklearn中的CountVectorizer,进行集合上的特征构建。也就是词典。

以及利用词典构建的tf-idf

然后就可以进行K均值聚类,比如设置K为3,这时候就可以如下设置

从而获取到三个群组中包含的句子。
那么总结一下,我们查看了聚类算法中的K-Means算法,其将向量空间的实际使用。
通过将样本转换为向量,然后使用向量空间中的距离或者夹角余弦,从而获取到不同群组中的结果。