基础数学课24-向量空间模型和文本搜索
我们看下在信息检索领域,如何使用向量空间模型。
信息检索是根据用户的输入,在大规模的,非结构化中的数据中,找到合适的资料返回。
那么就需要考虑一件事,怎么把用户的输入和文章内容联系起来呢?比如一个文章是不是和体育有关,用户是不是输入了体育相关的内容。
最为简单的模型是布尔模型,借助了逻辑的基本思想,其核心思想是匹配文章之中是不是包含体育相关的关键词。如果包含了足球 NBA 奥运会等,那么就返回值为真,如果没有就返回为 假。
其核心逻辑大致为
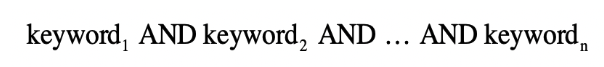
在基础上,我们延伸出了向量空间模型。这个模型需要将文档转换为向量。然后比较向量的距离或者相似的程度。这里我们词包来忽略单词的出现顺序,简化复杂度。但核心的内容,就是计算不同单词的向量。
其主要的步骤分为四个部分。
- 文档集合映射为向量形式
- 用户输入转换为向量。然后进行比较,算出各自的距离和夹角余弦的相似度。
- 评估和每个文档的相似度,找到相似度最高的文档。
- 评估查询结果相关性。
那么我们就说下详细步骤
- 文档转换为向量。
向量主要包含两个要素 维度和取值,维度表示有多少维向量,每个分量的含义是什么,取值表示每个分量的数值是多少。
那么首先,需要将文档中的文本处理为单词,利用中文词系的分词,或者英文的归一化处理等进行处理,获得出现的单词或者词组。最终形成一次字典。将字典中每一个词条作为向量的一个维度。
之后就是取值,最简单就是取0和1, 但这种情况没有考虑词的权重,有些关键词,其重要性就出现了,就能表达这个文章的核心思想。所以我们需要给单词赋予权重。
因此引入了改进方法,就是词频和词频*逆文档频率来实现的。
如果是基于词频的方法,就是假设我们有一个文档集合c,d表示c中的一个文档,然后t是文档中的单词。利用tf表示单词在文档中的出现次数。如果tf越高,会说明文档越重要。
除此外,还有idf,也就是逆文档频率。这里如果一个词出现在越多的文档之中,那么其重要性就越低。因为不好区分。
那么idf的计算方法为
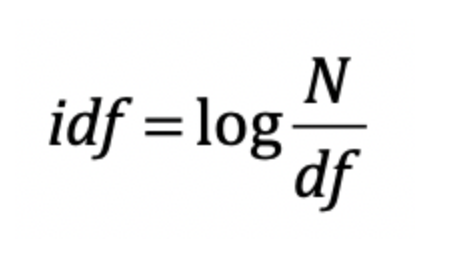
其中N是集合中的文章数量,df是词频,log是确保idf分不要太高于tf。
这样df越低,idf越高
从而引入了idf。
最后就可以接受用户的查询了,
查询和文档的匹配,我们可以查询转换为向量。由于用户的查询由自然语言组成,并且相对较短。所以需要注意一些事项。
查询和文档长度不一致,人们输入的查询短,甚至只是几个关键词,所以可以使用文档中所有词条来建立向量,如果某个维度的分量出现在文档或者出查询汇总,那么就去取1 tf 或者idf的值,如果没有就去取0,从而保证维度相同。
其次是查询中出现了文档集合中没有的词,这种情况下就可以去掉这部分分量。保证一个平滑。
最后对于这个词比较少的输入,idf如何计算,因为查询不存在文档集合的概念,可以考虑借用文档集合中对应词条的idf。
最后我们就可以得到一个查询的向量,然后将其和文档中的向量依次对比。看看查询和哪个文档相似。也就是利用计算向量之间的距离和夹角余弦。
最后是采用一些方式对结果进行排序,虽然我们可以获取到文档的相似度,但可能不是最符合用户需求的,所以还可以设计一些离线的评估方式,来获取查询的效果。
总结一下,我们从文档的信息检索出发,介绍如何使用向量空间模型。说了处理的整体步骤。如果是其他类型的数据,我们需要考虑提取特征,然后构建向量。并将查询也同样转换为向量。最后进行排序返回。