5. 如何准备微调数据
这里我们先看下在模型微调的时候,数据是一个什么样的结构
正常来说,我们的对话分为三个角色及对应部分 system user assistant
如果是在微调的时候,对于单轮来说
应该为
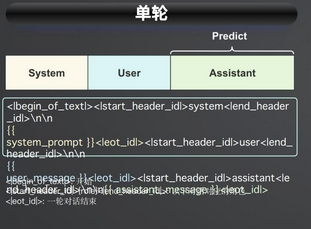
遵循利用不同的分隔符的方式,将我们的system user assistant拼接进去。
其次是对于拼接的system user和assistant三个角色数据,应该做什么样的要求?
应该遵循 高质量,真实性 针对性 多样性这四个原则
高质量不必说,是准备的微调数据最重要的部分
真实性则是要贴合真正的使用场景
针对性则是需要针对质量差的数据进行专门的改写
多样性则是做到数据的多样,避免过拟合的问题。
然后是对于准备的微调数据,应该准备多少的数量
这里建议至少是100条,建议达到5000条。
最后就是微调数据的获取方式
最为常见的就是格式化的NLP任务数据
采用QA的方式进行存储。
其次是日常对话数据
利用人工加上AI的方式,将日常对话的数据进行提炼。
转换为QA对进行训练。
最后则是合成数据
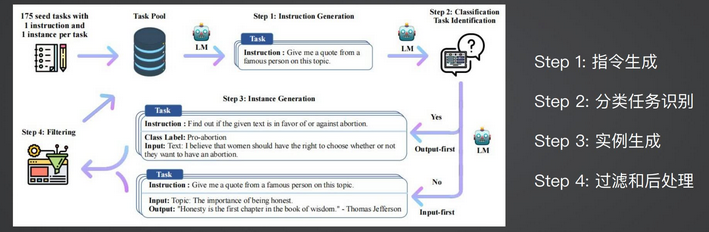
对于合成数据,最为常见的是 self-instruct
划分为四个步骤
指令生成 分类任务识别 实例生成 过滤和后处理
除此外还有一种Evol-Instruct的生成方式
其分为了深度进化和广度进化
广度进化则是增加主题和技能的广度
深度进化这是增加约束 深化 广度,输出复杂度。
比如下面是一个符合Evol-Instruct的生成Prompt
