6. 模型微调
这里我们看下微调的原理,以及微调的过程。
首先是微调的原理,什么是模型微调
在一个初始的模型当中,我们可以假设模型主要是根据公式和输入得到输出
即
Y = W * X
那么我们想要得到合适的Y,就需要确定合适的W
比如我们希望,当输入X为2的时候,输出为1,那么W就应该为0.5
那么我们就需要对W进行初始化,
而模型在训练的时候,会不断的测试W的设置,比如从0.1开始,一直实验到0.5
反之如果有一个预训练的模型,一开始W就设置在了0.47的附近,那么训练到0.5就会很快了。
因此模型微调相较于从头开始训练,微调可以省去大量计算资源和时间,提高精准度。
那么现在主流的大模型微调是基于GPT-3之后进行的指令微调
Supervised fine-tuning 简称SFT模型。
那么各个云厂商都提供了自己的LLM 微调训练工具
除此外还有HuggingFace提供的Transformers训练工具
https://huggingface.co/docs/transformers/main/zh/tr aining#%E8%AE%AD%E7%BB%83
那么SFT训练过程为
- 准备训练数据和评测数据
并组装为合适的数据结构,同时要求数据具有上一节说的高质量,真实性,针对性,多样性。
同时确保数据量足够多。
- 选择合适的基础模型
根据目标选择合适的基础模型
同时确认模型训练中使用的参数多少
- Loss 曲线分析
根据Loss曲线来评测训练结果。
除此外还有LoRA方式进行微调
LoRA的核心思想是在原本训练好的模型中,冻结预训练好的模型权重参数,在冻结原模型参数情况下,通过模型中增加额外的网络层,并训练这些网络层参数。
比如原本的模型参数W
为d * k
如果我们引入一层,进行解耦
变为 d * r + r * k
通过这种方式,LoRA的训练量将会小于全量参数微调
通过显存占用将小于全量参数微调
对应的工具也是可以使用HuggingFace提供的基于PERT进行训练
https://huggingface.co/docs/peft/main/en/task_guides/semantic_segme ntation_lora#wrap-the-base-model-as-a-peftmodel-for-lora-training
在微调的过程中,比较重要的参数即r
LoRA中r的大小,可以根据应用场景调整,一般越大,微调数据对模型起到的作用更大,一般取 8/32/128等
而且相较于全量参数微调
LoRA表现不好,所以初次实验考虑使用全量微调,后续可以用LoRA迭代
且LoRA记忆能力不如全量参数微调。
最后是模型训练中的Post-Pretrain
这里指的Post-Pretrain,主要是用于针对特定领域,进行专业的训练。
比如一个在中文金融方向进行过Post-Pretrain调整后的大模型在特定领域的效果是优于其他的模型的。
这里举一个例子
比如Code-LLAMA代码大模型
在代码领域,CODE-LLAMA-7B的效果优于LLAMA2-70B的
对于CODE-LLAMA的代码大模型,其训练过程中就使用了Post-Pretrain来进行了增强训练。
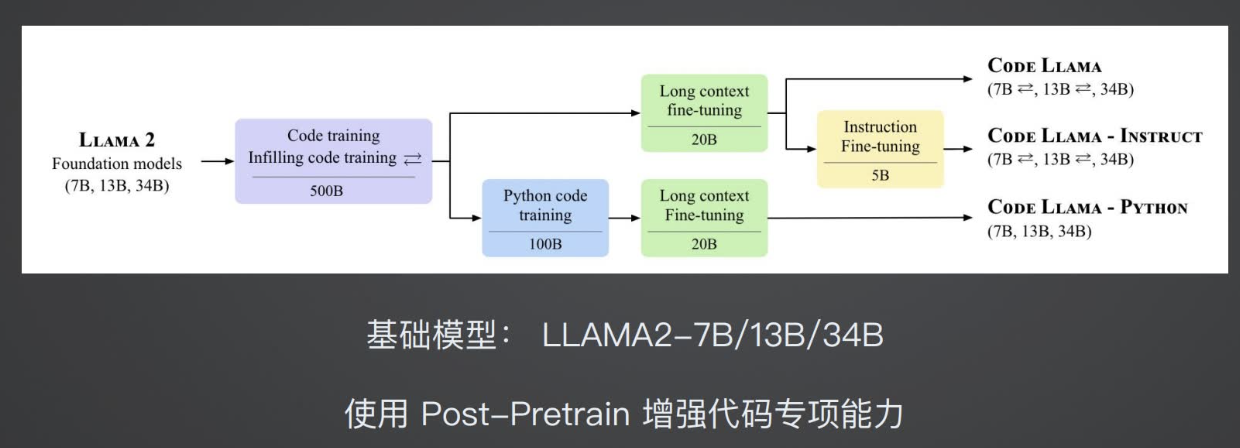
那么对于这样的一个训练模式,该如何操作呢?
一般来说,这样Post-Pretrain的模式是和SFT模式相结合的
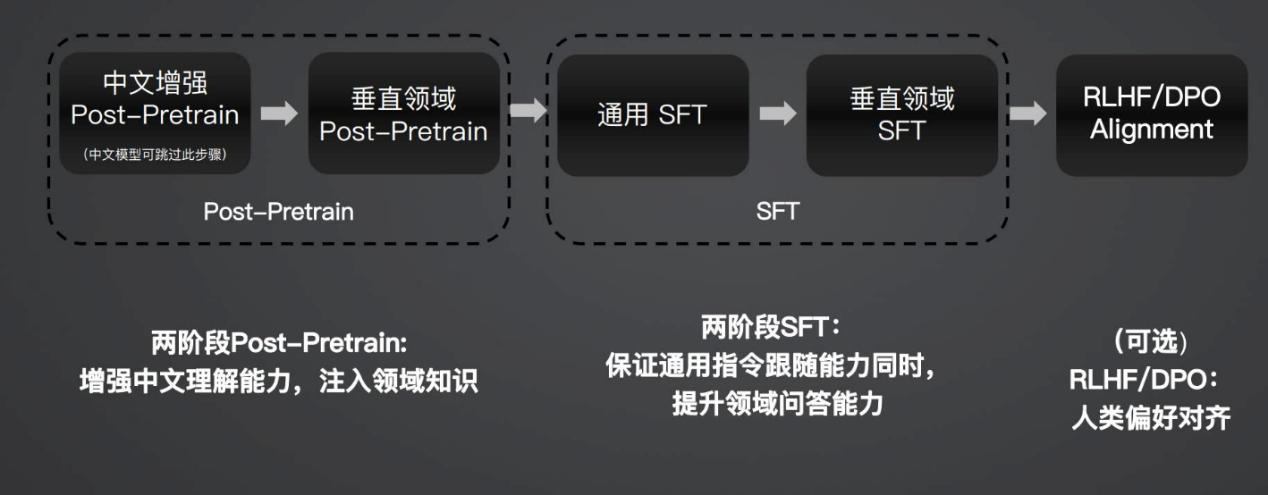
先进行Post-Pretrain之后进行通用SFT进行训练,最后进行对齐
之后是Post-Pretrain和SFT的对比
Post-Pretrain 的数据集更加贴合原生的文档内容

而SFT的语料格式更加贴近问答对的形式

而Post-Pretrain的语料,则也需要经过,
文本抽取 数据清洗 去重和校验的过程去获取到语料
从而进行输入。
而且为了保证模型的通用能力,我们还需要确保中文语料和英文语料的合理配比
以及专业领域语料和通用领域语料的合理配比。