Dify中的知识库
本次我们进行知识库的介绍
从创建到管理再到使用,并介绍一些知识库的其他概念
首先我们说下知识库的基本概念
知识库主要是将企业的一些内部文档,FAQ等信息,上传到知识库中进行结构化处理,方便LLM查询并返回,最终形成一个AI客服助手对外暴露
这里的文档格式可以有TXT Markdown DOC HTML JSON或者PDF CSV Excel等
也可以直接从网页爬下来。
而在知识库中,往往包含多个上面说的文档,每个文档内部又进行了多组内容的组合。而LLM最终使用的,则是文档中的子组内容。
首先是如何创建知识库
- 需要导入文本数据
- 确定分段的方式
- 设定索引方法和检索设置
对于导入文本数据,主要的方式有上传本地文件,导入在线数据库,从网页爬虫。
对于一般企业来说,主要的方式是上传本地文件,可以进行批量上传,需要注意的是上传的单文件大小是15MB。
其次是确定分段方式,
这里主要的作用是数据的预处理和数据结构化处理。将文本进行合理化划分,划分为多个子分段。
之所以划分为子分段,是因为上下文窗口有限,且长文本对大模型检索反而没那么友好。
所以进行分段,由数据库基于用户问题,进行分段Top召回,从而进行问题回答。
而在分段的模式中,分为了通用分段模式和父子模式
这里我们着重讲一下
- 通用模式是将用户自定义的规则拆分为独立的子分段,当用户输入问题的时候,系统自动分析关键词,进行排序返回。
对于这种模式,每一段和段之间关系不大。因此需要我们合理的设置分段标识符
默认是\n
可以通过正则表达式来设置。
或者通过设置分段最大长度来进行分段,比如一段最大的字符数是4000Tokens
或者设置分段重叠长度。
设置分段的时候,段和段之间具有一定的重叠。一般设置为分段数量的10%-25%
除此外,还可以设置一些文本预处理规则,比如替换连续的空格 换行符 制表符为null
删除URL或者电子邮件。
之后可以预览分段之后的效果。
- 父子模式则是利用双层分段结构来平衡,其中父分段是保持着较大的文本单位,提供详细上下文信息,子分段则是较小的文本单位,用于精准检索。检索的时候匹配到子区块,然后根据对应的父区块获取到上下文信息。最后确保返回的详细。
那么分段的时候需要分别设置父子分段的分段规则
父分段提供的分段选项有进行分段和提供全文
进行分段可以设置为段落区分,分别为分段标识符或者设置分段最大长度
提供全文则是直接保留全文内容。
子分段则是必须要提供分段标识符和分段最大长度。
两种分段方式中,父子检索提供的信息更多,精准度也更高。
之后是设置索引方法和检索设置
- 索引方法是用于方便LLM对知识库内容的检索,提高返回上下文准确性并最终提高回答的准确性。
对于索引方法,提供了经济型和高质量型两种。
经济型则是对于每个区域,提供10个关键词来进行检索,利用的是倒排索引,效果往往不佳。
对于高质量型,则是利用Embedding嵌入模型来将分段的文本快转换为数字向量,使得用户问题和文本之间匹配更加精准。
需要设置一个Embedding的Model 来进行处理,在处理之后,后续的检索的时候可以设置向量检索 全文检索 混合检索三种方式。
除此外还有着Q&A的模式作为索引方法
启用这个模型,会对分段后的文本生成Q&A的匹配对
通过提前生成问题来进行匹配,从而提高后续索引时的精准度。
- 其次是检索设置
也对应着高质量索引和经济索引
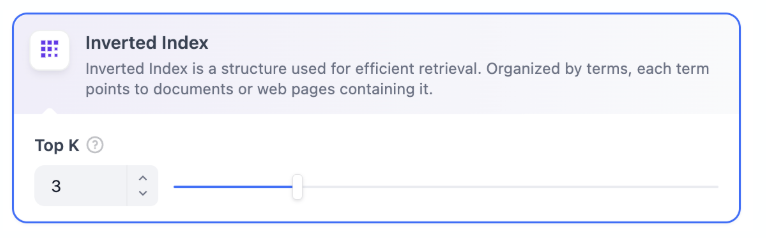
经济索引只是基于了倒排索引的方法,基于倒排索引返回TopK个片段。这个TopK可以进行设置
在之后是高质量索引
Dify支持向量检索,全文检索和混合检索设置。
向量检索就是最为基本的,将查询转换为文本向量,进行获取
其中可以设置TopK和Score,Rerank模型
TopK则是相似度排序,Score则是相似度阈值。超过阈值的片段才会被返回。
ReRank模型是通过第三方的Rerank模型进行重排序来优化结果。
全文检索,则是通过关键词进行匹配
也支持设置TopK和Score
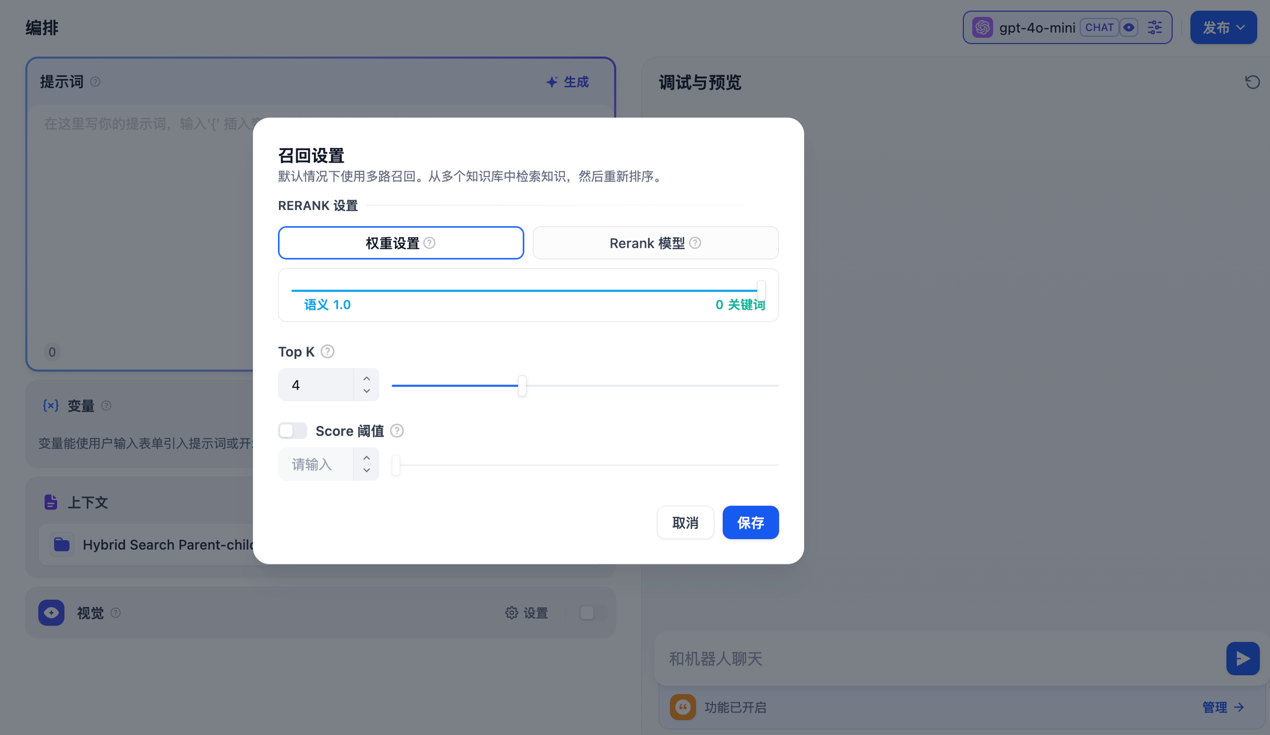
最后则是混合检索,同时执行全文检索和向量检索,然后进行混合返回。至于具体返回哪一个搜索结果,则是由用户设置。用户可以设置权重设置或者Rerank模型
权重设置是让用户给予一个搜索的权重,是更倾向于使用向量检索还是全文检索
Rerank模型则是由第三方模型来进行决定。
两者都可以设置TopK和Score阈值。
接下来是使用知识库
一般来说在LLM中设置上下文,添加已经创建好的知识库即可使用。
这里主要是说在设置知识库的一些可选项
诸如如果设置了多个知识库
那么可以利用Rerank策略或权重策略找到最合适的内容来返回。这种检索方式更加科学。
同时我们还可以对文档库进行修改,诸如点击进入文档库
启用/禁用/归档/删除文档
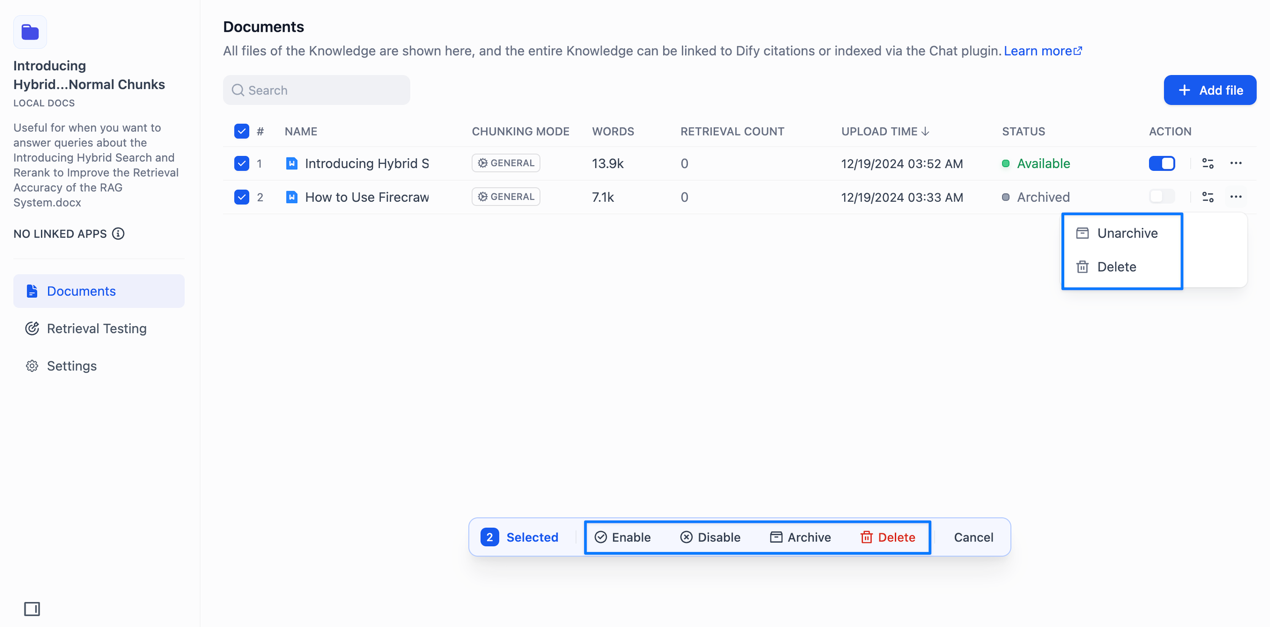
其中归档就是只能查看和删除,无法重新编辑。
编辑文本文档中内容
包括 添加文档分段 编辑文档分段
其中父子文档比较特殊,支持编辑父文档然后自动同步以及单独编辑子文档。
除了最为基础的,创建 使用流程外。知识库中还有着元数据 召回测试 知识库API的三个概念。
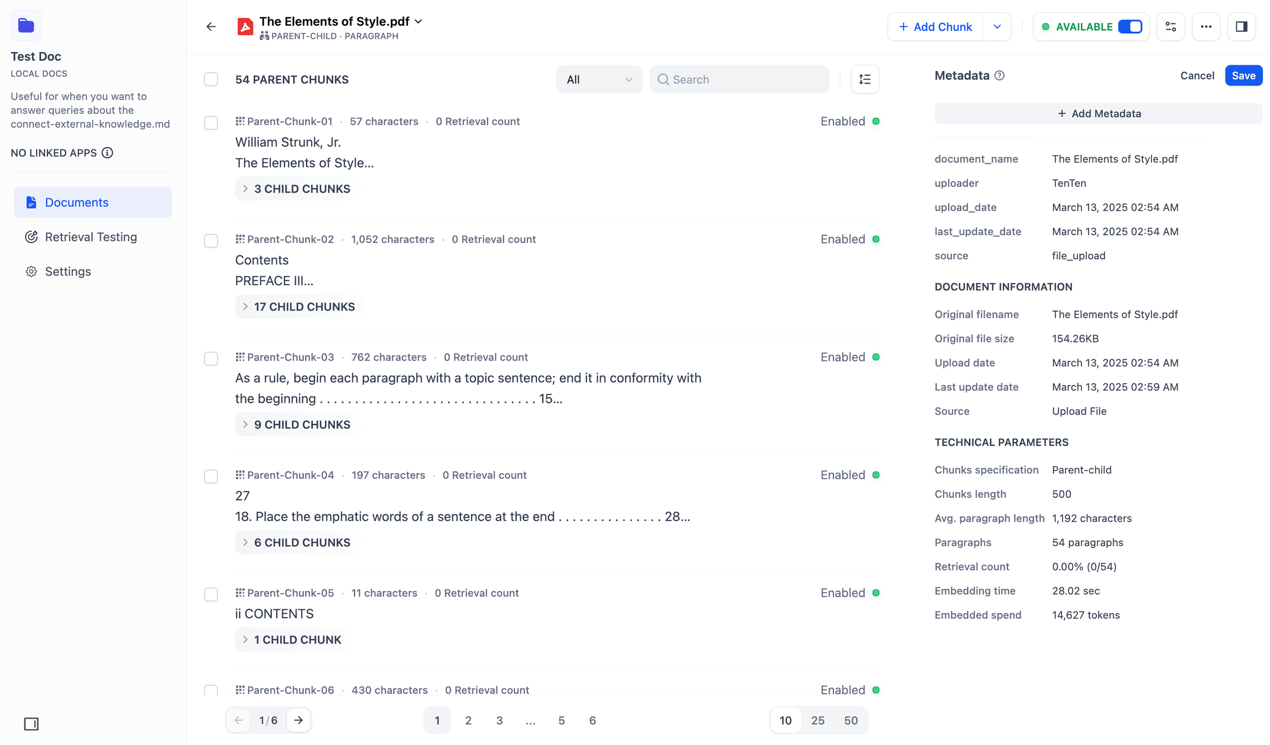
- 元数据则是我们可以给知识库中的文档增加元数据,诸如作者 语言这类元数据。
其支持设置字符串 数字 时间三种类型的元数据。
想要进行设置和管理,需要在知识库管理界面,点击元数据进行管理
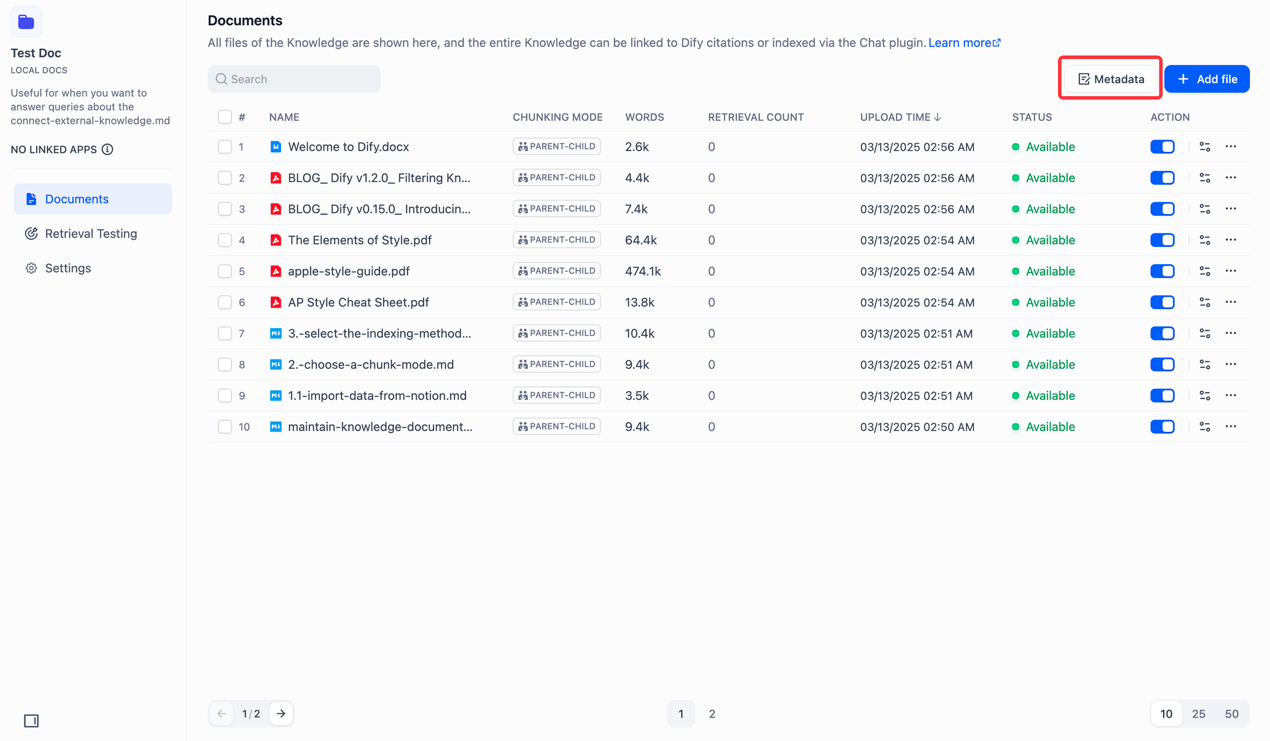
其中支持增删改查元数据
如果我们想要对文档进行元数据赋值,则可以通过批量操作,以及最下方的元数据进行管理
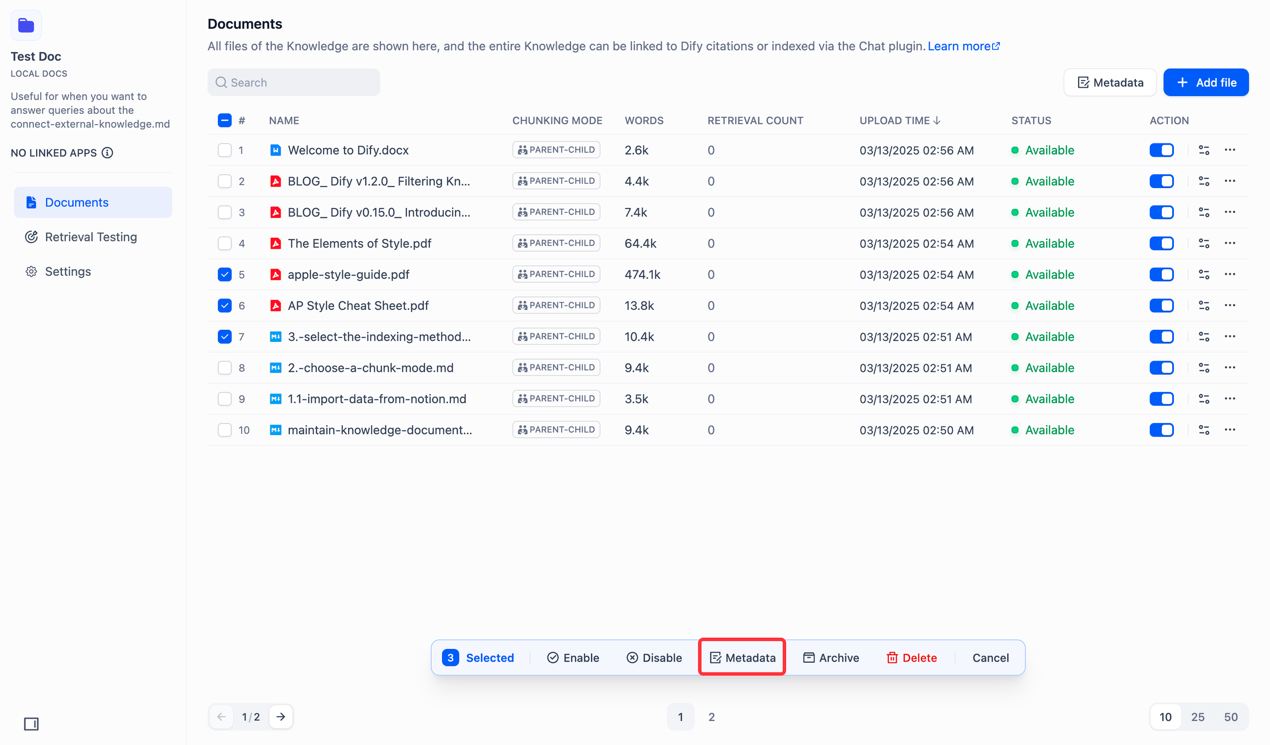
同时可以进入到文档详情中,点击右上角的开始标记来管理元数据信息
而这些元数据可以帮助我们使用知识库
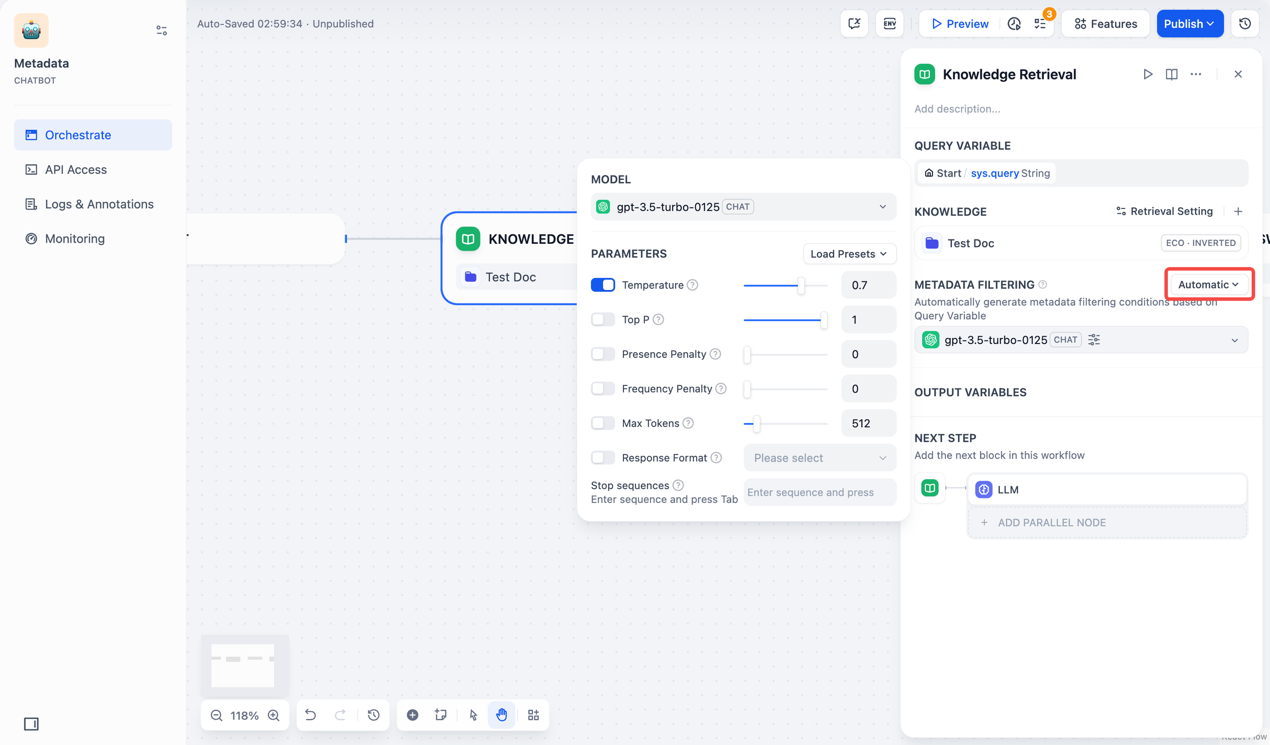
默认不开启元数据筛选,但支持自动选择元数据和手动模式选择元数据。
自动模式需要一个大模型来进行操作
手动模式则是需要进行配置条件,比如and/or 某些元数据标签。
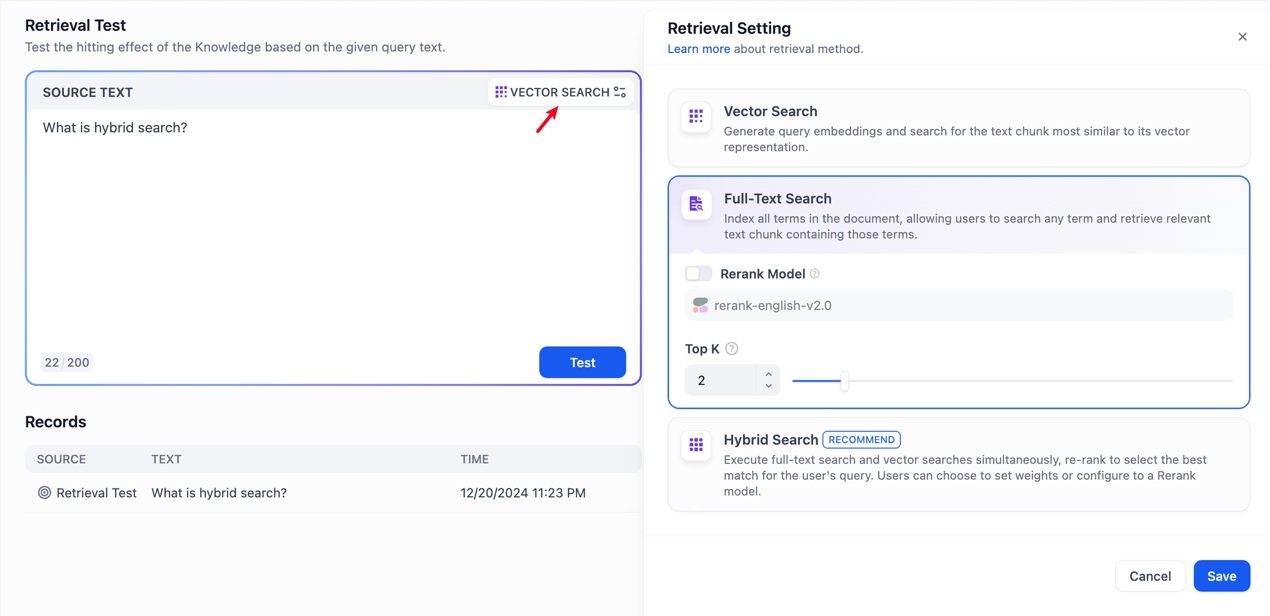
- 召回测试
主要是测试用户输入问题后是否能得到正确的文本区块。
支持输入文本来获取到完整上下文
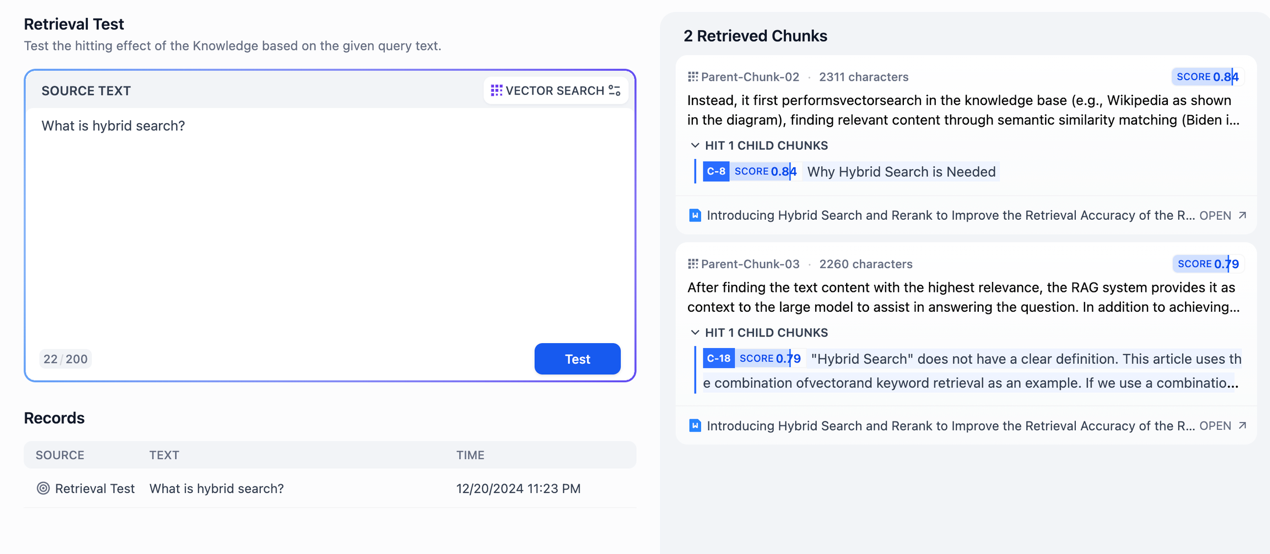
我们可以通过文本查看饮用的内容
从而调整搜索设置,对于搜索,只需要在右上角点击更换当前知识库的检索方式即可
- API链接知识库
可以通过对外部暴露API,来管理知识库
比如最常见的通过文件创建文档
|
curl –location –request POST ‘https://api.dify.ai/v1/datasets/{dataset_id}/document/create-by-file’ \
–header ‘Authorization: Bearer {api_key}’ \ –form ‘data=”{“indexing_technique”:”high_quality”,”process_rule”:{“rules”:{“pre_processing_rules”:[{“id”:”remove_extra_spaces”,”enabled”:true},{“id”:”remove_urls_emails”,”enabled”:true}],”segmentation”:{“separator”:”###”,”max_tokens”:500}},”mode”:”custom”}}”;type=text/plain’ \ –form ‘file=@”/path/to/file”‘ |
通过文件更新文档
|
curl –location –request POST ‘https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/update-by-file’ \
–header ‘Authorization: Bearer {api_key}’ \ –form ‘data=”{“name”:”Dify”,”indexing_technique”:”high_quality”,”process_rule”:{“rules”:{“pre_processing_rules”:[{“id”:”remove_extra_spaces”,”enabled”:true},{“id”:”remove_urls_emails”,”enabled”:true}],”segmentation”:{“separator”:”###”,”max_tokens”:500}},”mode”:”custom”}}”;type=text/plain’ \ –form ‘file=@”/path/to/file”‘ |
详情可以参考
https://docs.dify.ai/zh-hans/guides/knowledge-base/knowledge-and-documents-maintenance/maintain-dataset-via-api