DeepResearch的第一次实战
本次我们看下最近比较火的框架,DeepResearch,在这个框架之中
目的是让大模型更加贴近人一样去搜索并整理回复给客户。
首先我们说下什么是DeepResearch
其是一个自主的Agent框架,核心逻辑就是收集需求,自主性的迭代信息,反思,并最终汇总输出。
可以分为三个步骤,收集需求
收集信息
最后完成报告
对于这三个阶段的,更加细粒度的划分为
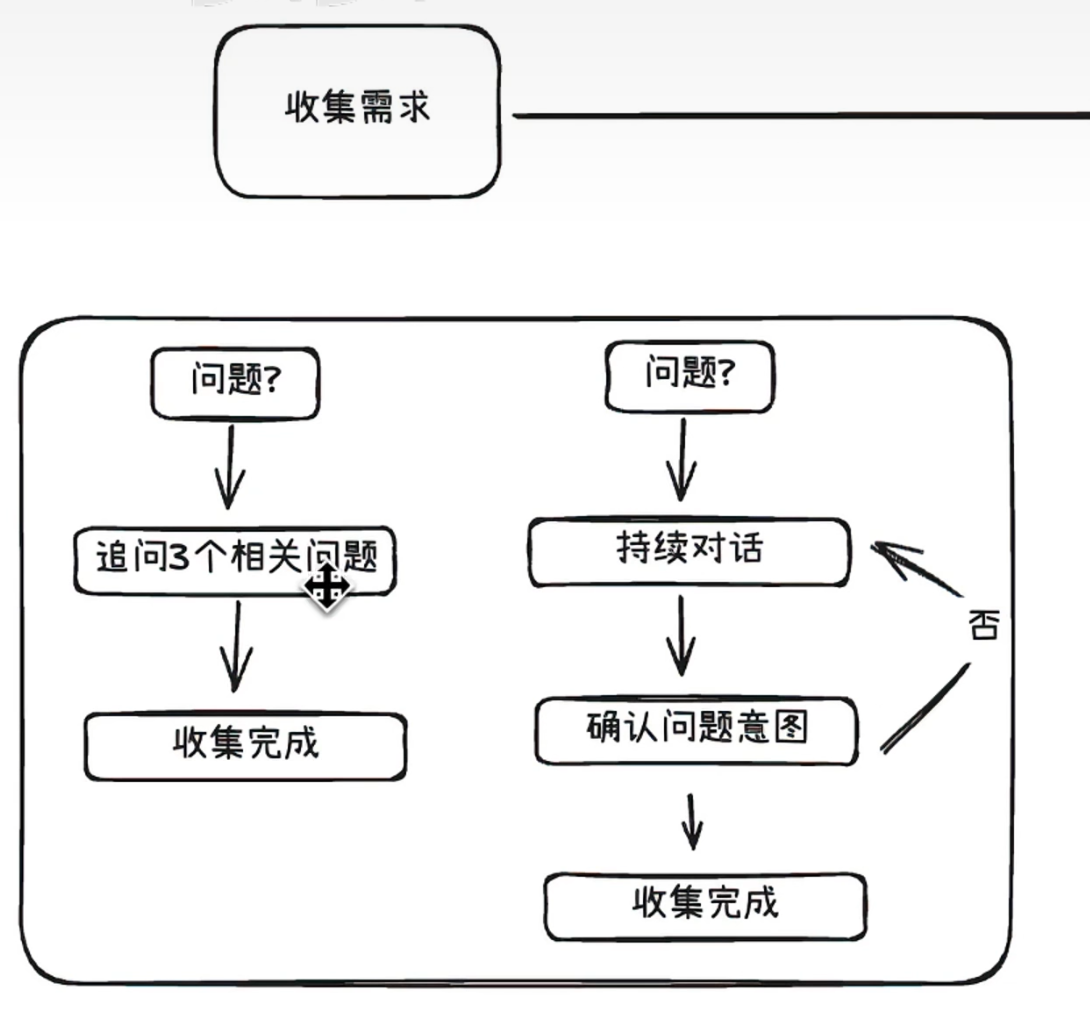
- 收集需求
针对用户的输入,首先是判断用户是否会追加问题,进行多轮对话后,判断完成完整的用户问题收集后汇总进行下一步。
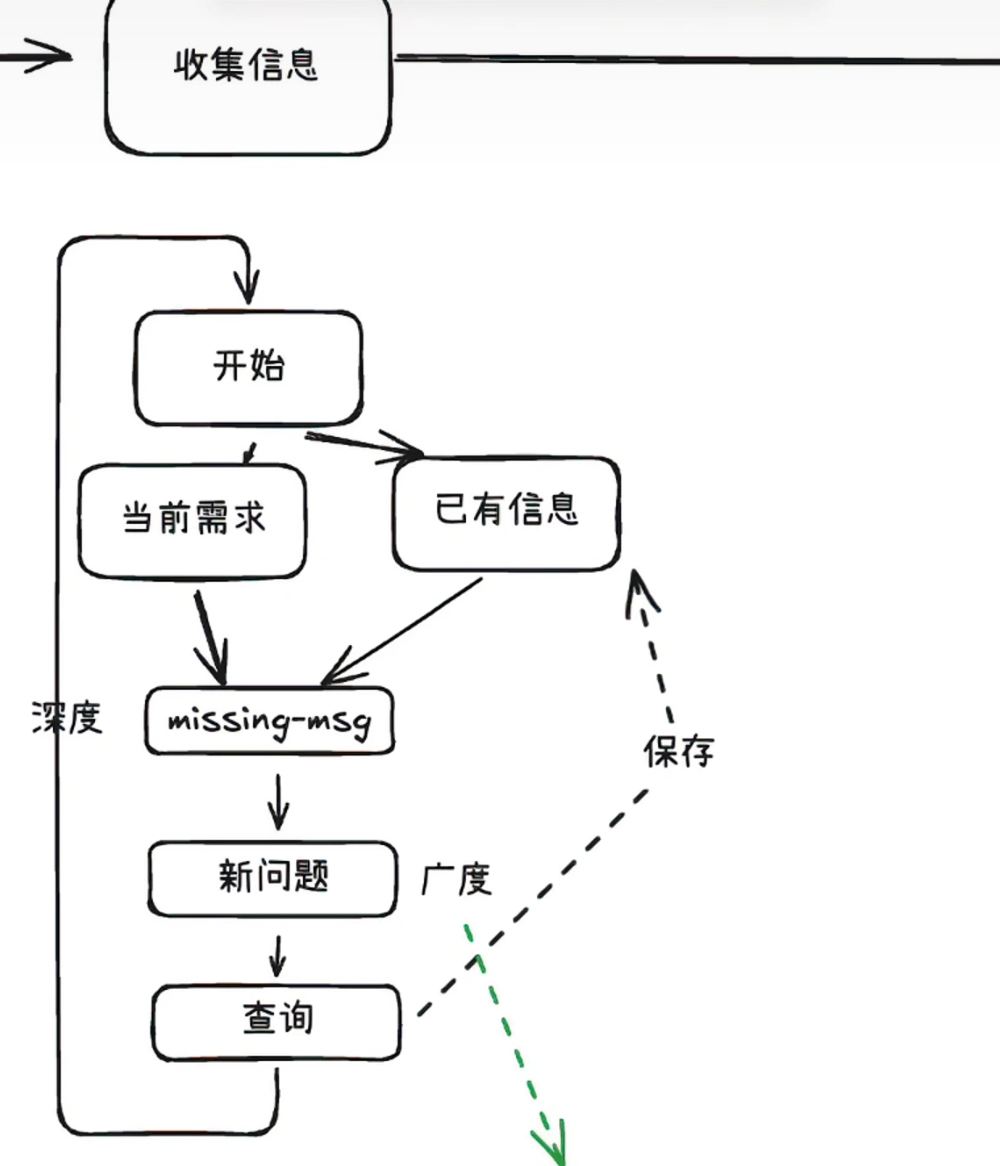
- 收集信息
开始进行迭代,基于目前这一轮的需求,和已经存在的信息,进行汇总后生成新问题,查询后进行保存在已有信息之中,最终完成所有信息的搜索并返回。
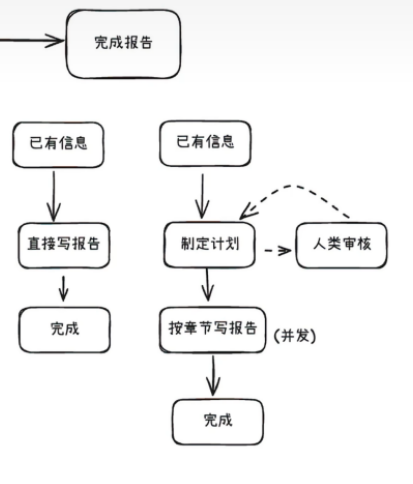
- 最后考虑输出报告
这一部分是基于已有信息,一方面可以直接输出报告,另一方面可以考虑先输出当前的信息给用户,用户确认完成之后,按照章节进行报告输出,最终进行完成。
这里我们就考虑进行DeepResearch的集成
这里使用Dify框架进行,
在Dify的官方建议工作流之中,
选择这个DeepResearch进行集成
而在这个DeepResearch工作流之中,我们可以依次看下不同节点的实现
首先是开始节点
用户输入一个搜索问题,并且给出对应的深度
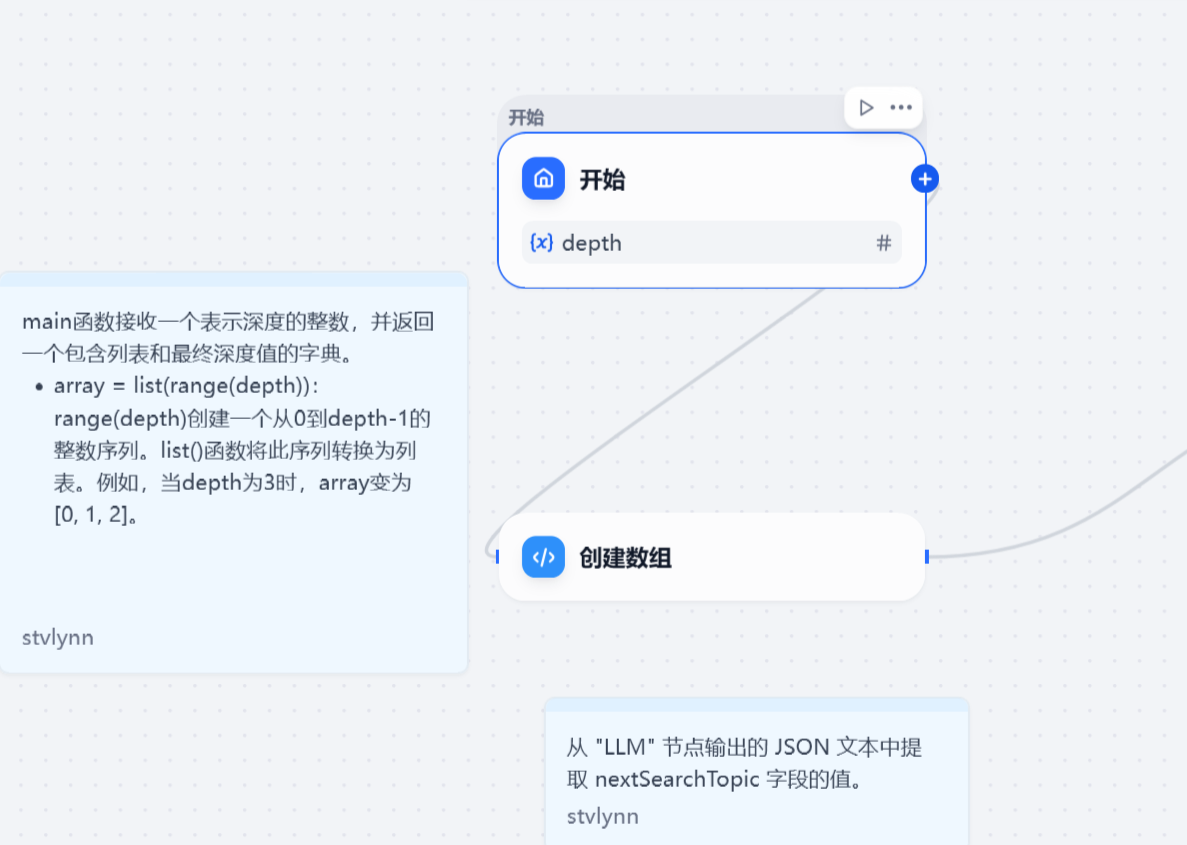
理论上这个节点可以模仿我们上面说的,在这里和用户进行多轮对话,从而实现深度且完整的用户问题搜集。
之后进入第二部,也就是迭代进行深度搜索,获得用户搜索的结果
首先是一个LLM
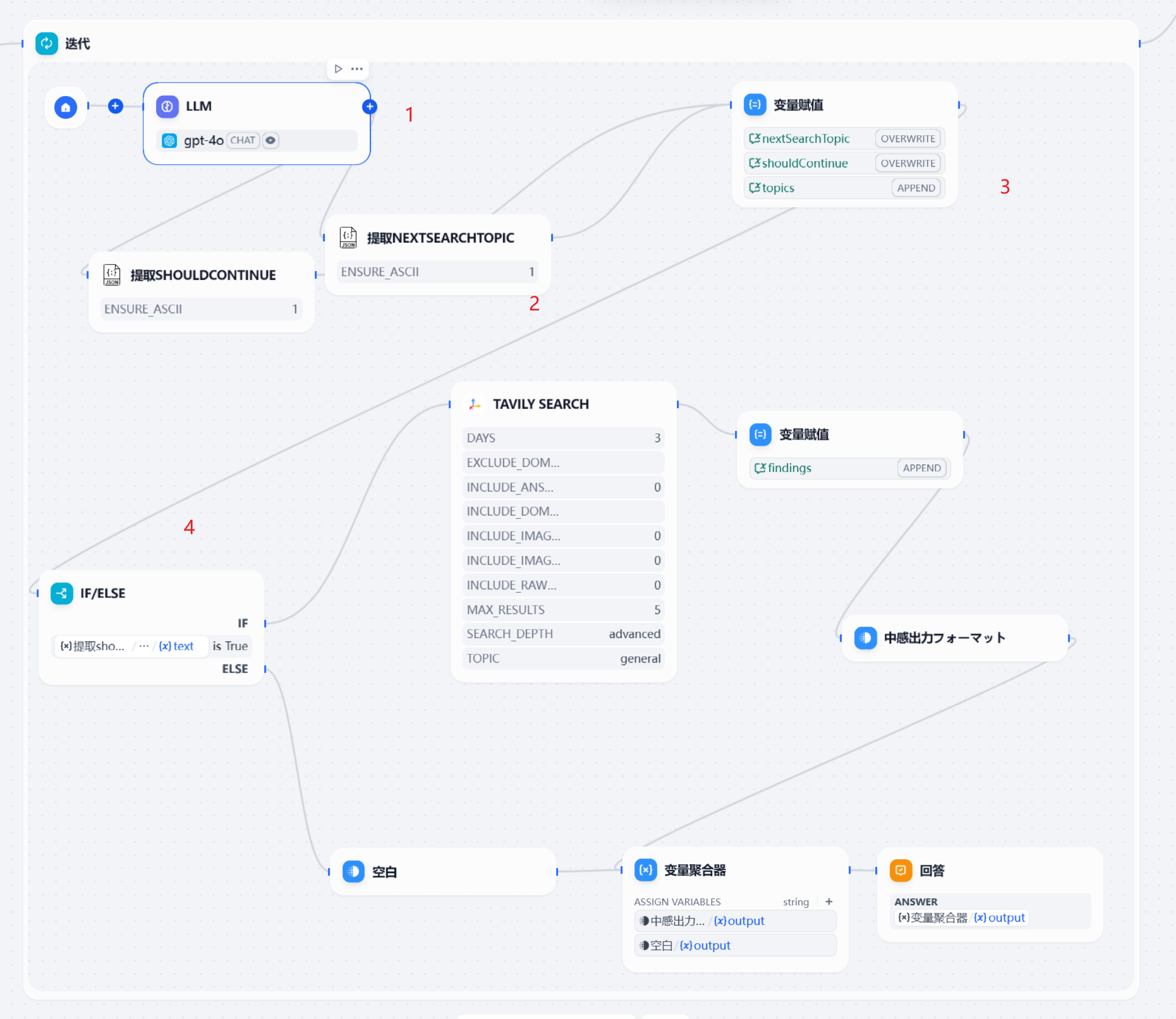
在第一个节点,LLM之中,我们看下系统提示词。
|
您是一个研究代理,负责调查以下主题。
您发现了什么?还有哪些问题尚未解答?下一步应该调查哪些具体方面? ## 输出 – 请不要输出与已搜索主题完全相同的主题 – 如果需要进一步搜索信息,请设置nextSearchTopic – 如果已获得足够信息,请将shouldContinue设置为false – 请以json格式输出 “`json nextSearchTopic: str | None shouldContinue: bool “` |
其次是在User之中,声明一方面获取到user的input。以及将之前迭代轮数之中的findings和topics一并进行了传入。
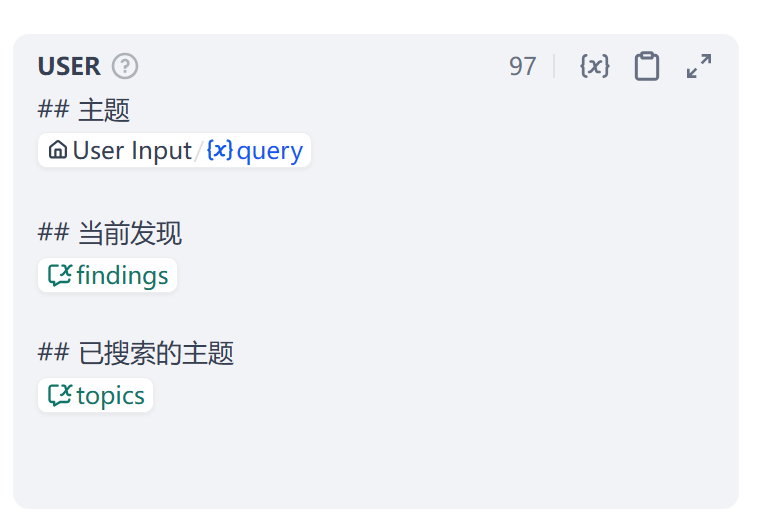
总结这一步骤,在这一步骤之中,我们将信息进行输入,之后要求大模型以JSON的方式进行输出。
之后第二步通过Dify提供的变量提取器,获取到JSON格式的输出。
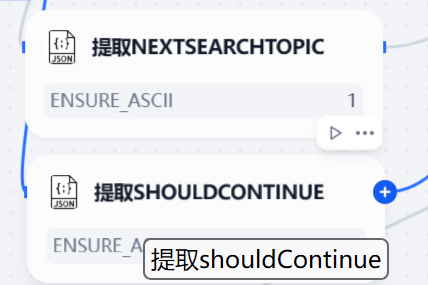
将提取出来的结果放入到全局变量之中。
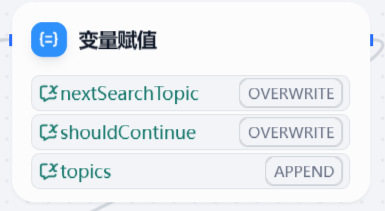
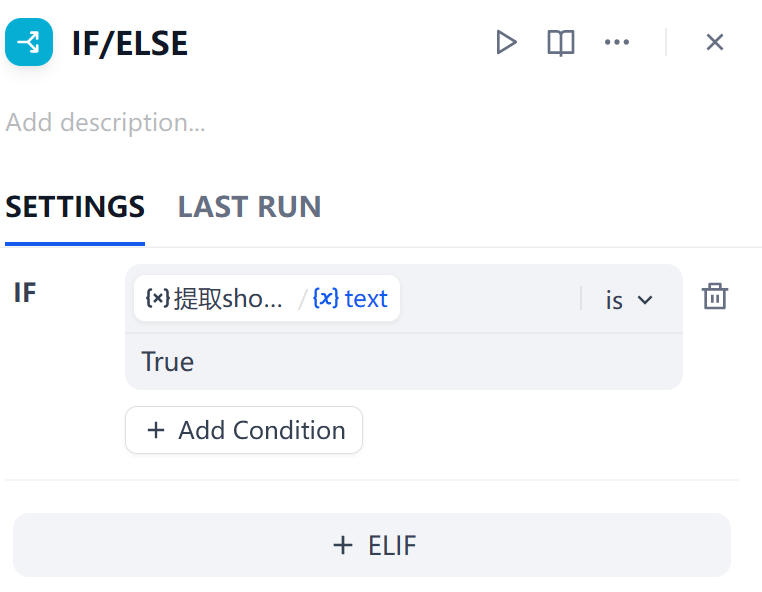
并通过一个默认的IF/ELSE
判断是否进行搜索还是进行聚合
如果需要进行搜索的话,那么就进行调用相关的搜索引擎,这里采用TAVILY SEARCH作为实现。
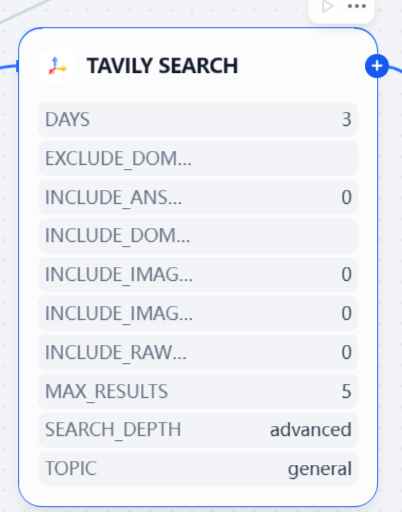
并且将结果存入到findings全局变量数组之中。
之后进行判断是否大于了递归深度。
之后为了提高用户体验将findings之中的数据进行了输出展示。
最后在完成递归或者判断不需要继续之后,进行相关的报告输出。
这里并没有选择我们上图中展示的一个通过和用户多轮迭代,修改并输出的方式
也没有考虑采用报告章节式的分章节导出。
而是直接采用直接输出的方式,详情如下
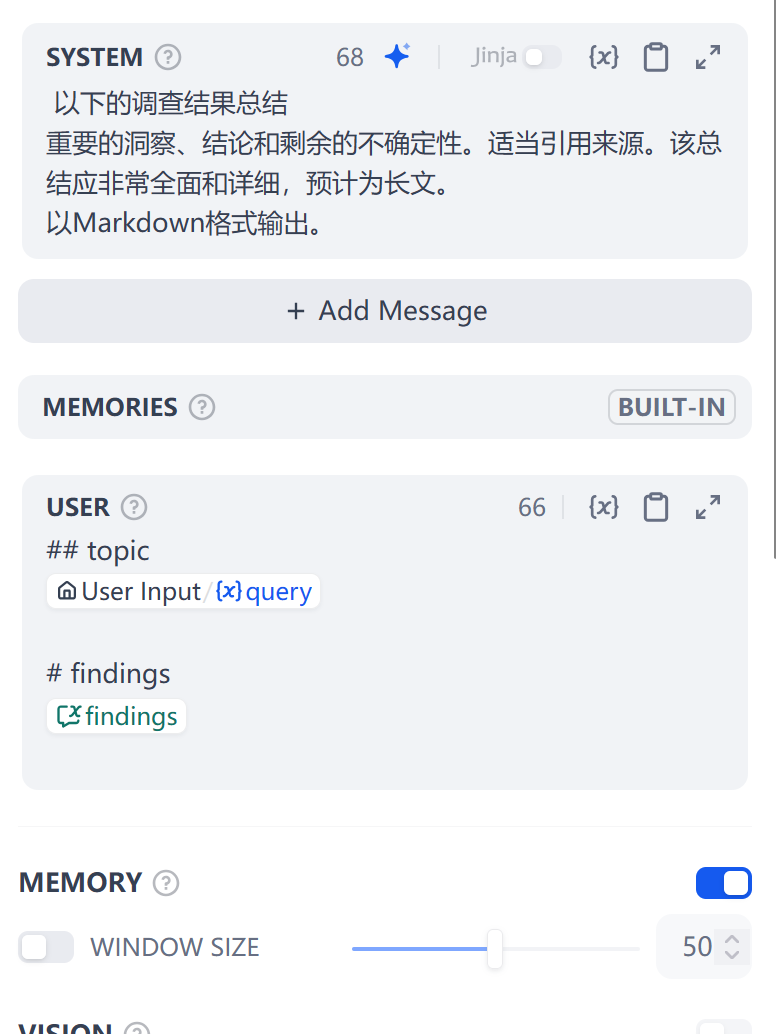
提示词之中,说明以Markdown方式输出文档
并且将用户输入以及findings发现的内容一并输出了出来。
那么这就是一个最简单版本的DeepResearch。
除了Dify之外,还有一些框架可以生成DeepResearch
诸如:
huggingface-deepsearch:https://huggingface.co/blog/open-deep-research
node-deepsearch:https://github.com/jina-ai/node-DeepResearch
zilliz-deepsearch:https://github.com/zilliztech/deep-searcher
langchain deepsearch:https://github.com/langchain-ai/open_deep_research
deepsearch-shandu: https://github.com/astordu/shandu
在这里,个人觉着可以主要关注 langchain和dify 以及 huggingface的DeepResearch框架。