Dify中的工作流
这里仍然是一章对于Dify中工作流相关知识的介绍,不过在介绍过程中,仍然是基于笔者的视角,对于个人觉着比较重要的知识点进行记录。
- 工作流简介
分为两种Chatflow和Workflow
Chatflow:面向对话类情景,包括客户服务、语义搜索这类交互式对话
一般是给予指令 生成内容 多次讨论,生成结果 结束
Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
给出指令 生成结果 结束
常见的实现案例有
1.客户服务 2.内容生成 3.配合Trello Slack 等系统进行任务自动化 4.数据分析和报告 5.邮件自动化处理
- 工作流中的变量
在工作流中,变量很重要,比如一些系统变量,诸如sys.files 用户上传的文件,需要注意在交互过程中多次上传只会保存最后一次。
一些环境变量 比如运行时涉及的API密钥等。
一些会话变量,上个节点的输出,用户的一些偏好的等。这里我列一些我觉着重要的方便记忆。
Workflow:sys.files,sys.user_id 分别对应着用户上传的文件以及用户ID
Chatflow:sys.dialogue_count 记录着用户对话轮数,方便进行操作,比如对话到X轮的时候,进行历史对话总结。
环境变量,主要是存储API密钥相关的Secret
- 节点
节点是工作流中的关键构成。这里我挑一些重要的说
- LLM
主要是调用大模型,来进行信息的处理
诸如使用大模型来进行意图识别 文本生成 内容分类 代码生成,文本转换 RAG 图片理解 文件分析
可以对其进行模型参数设置,比如温度 TopP 最大标记等
可以提供上下文 向LLM提供背景信息
编写提示词 提供System User Assistant 三部分内容
还可以给LLM设置记忆和记忆窗口的大小
- 知识检索
这里主要是给流中的后续节点提供外部知识检索的能力。首先在知识检索节点将用户问题最相关的知识进行检索并召回。然后将问题和检索的上下文传输给后续节点。
配置比较好玩
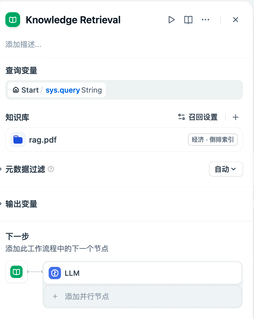
设置查询变量为用户输出sys.query
设置知识库
制定召回模式(权重还是Rerank模型)
这样会输出result数组,方便后续操作,常见的有LLM或者code节点。
- 代码执行
负责执行Python或者NodeJS代码来进行数据转换。
一般来说就是提取数据,比如利用Json类库,json.loads来进行提取
但需要注意,对于代码执行,一般是执行在沙箱中,确保安全,所以对于直接访问文件系统,网络请求这类操作,请注意。
- 文档提取器
主要是将文档进行文本提取,供下游使用,增强某些不支持文档读取的LLM能力。
需要注意的是,因为没有驱动LLm,所以只能去读取文档类型的信息。
- 变量聚合
将多路分支的变量聚合为一个变量,实现下游的统一配置
比如,虽然不同的分支经过了不同的知识库检索,但是下游LLM操作是一样的,这时候就可以使用多路聚合来操作。
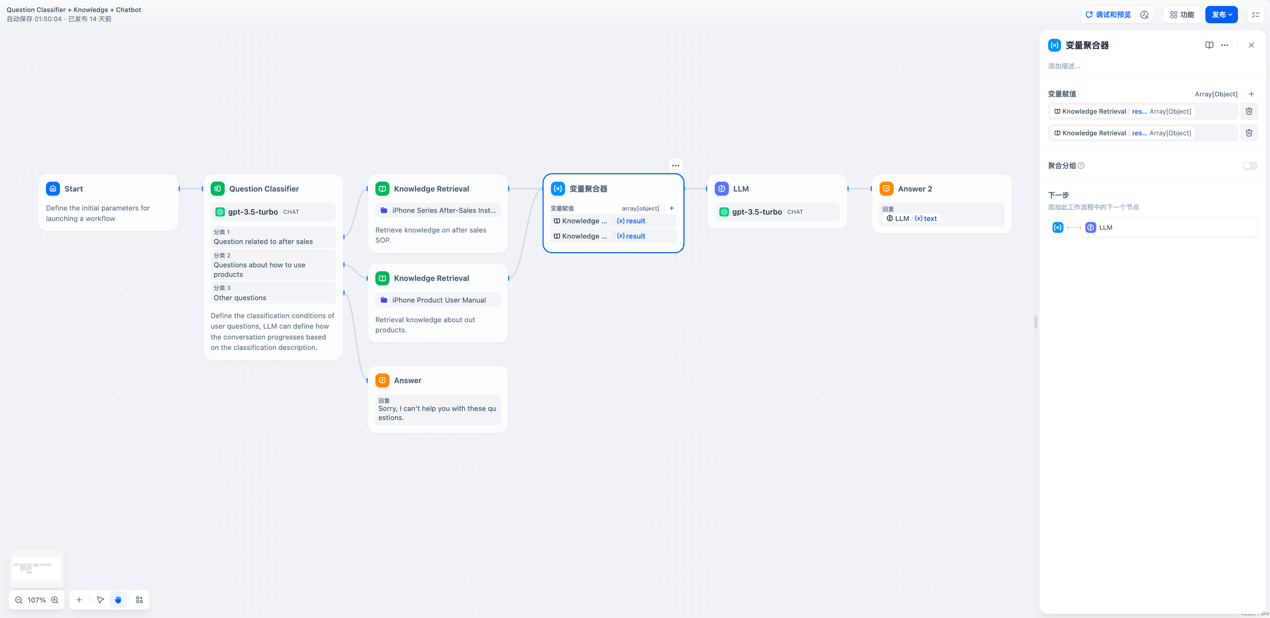
而且变量聚合器只能聚合同一种数据类型的变量。
- 变量赋值
因为在对话流中存在多轮交互,因此变量赋值就是将对话流中的变量赋值给会话变量中用于临时存储。
方便后续轮次对话中使用。
这里拿官网例子举例
自动判断提取和存储对话信息
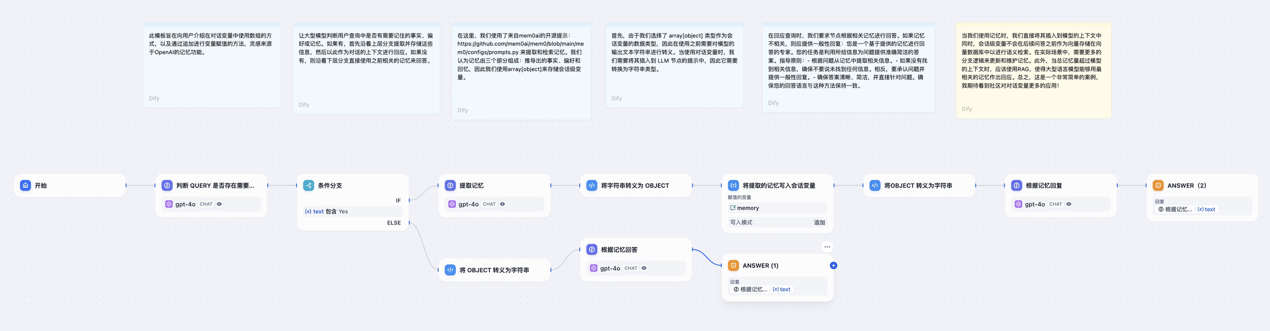
根据是否是搜索历史,来走不同的流程
设置一个会话变量memories,类型为array[objecy] 负责存储
然后分别判断存储还是读取。
对于这样的一个会话变量,可以如下配置
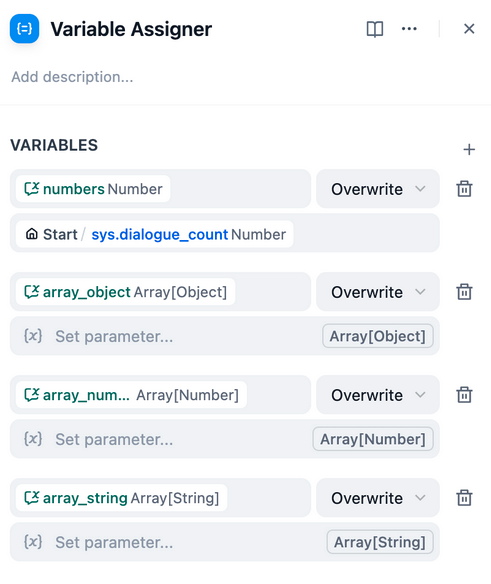
- 参数提取
支持根据上下流节点的需求,结合自然语言推理,获取到结构化参数,用于后置的工具调用或HTTTP请求。
配置方式如下
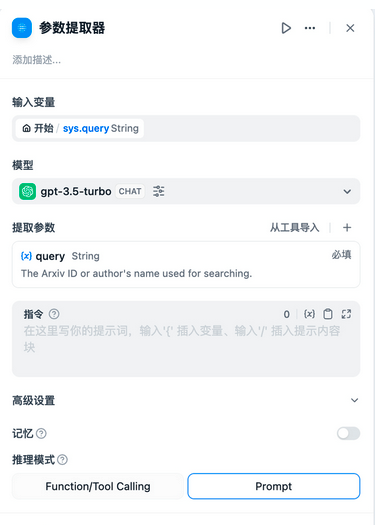
其中输入变量为sys.query这个系统变量
选择模型
以及提取的参数格式,可以从已有的工具中快速导入
以及编写一个prompt
推理模式则是根据大模型,选择是否是Function还是Prompt
- Agent
基本上和使用Agent一样,支持一些最大迭代次数等。