2. FastGPT中的工作流
那么这一章是对上一章的一个延续
主要是说明在Dify和FastGPT之间的工作流编排的区别。
在FastGPT之中,仍然具有直接创建机器人和工作流两种方式
对于工作流的话,使用起来和Dify大致相似。只是编排的形式不一样。
具有一个额外的系统配置节点,可以在这个配置节点中配置整个工作流的详情。
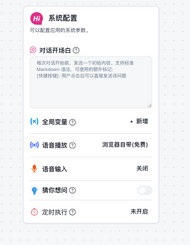
其节点和节点的配置方式也是类似。
接下来是两者之间的详细节点对比
- 对于AI对话节点,基本相同
同样支持书写提示词,当中插入变量,设置知识库引用。
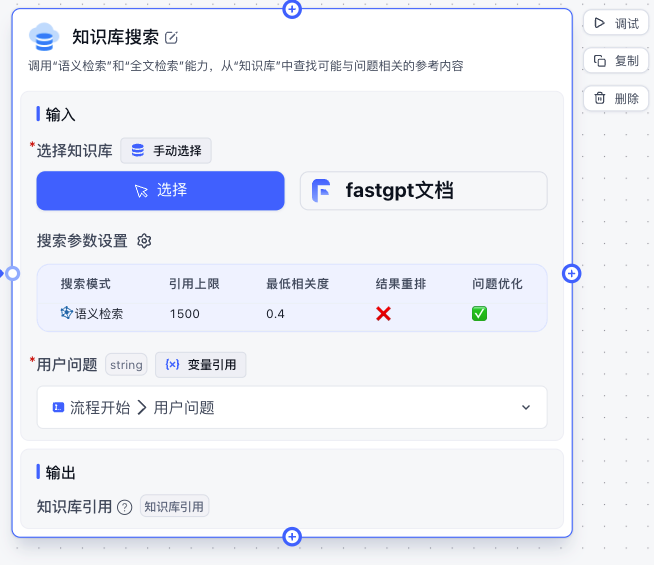
- 对于知识库集成,提供了更强的能力
首先最直观的就是支持配置问题优化
因为很多用户的问题往往表达性不好,因此引入一个大模型进行问题优化是有必要的
- 工具调用节点
对于FastGPT中的工具调用,提供了额外的搭配节点,即工具调用终止节点。
可以结束本次调用,接在某个工具后,当工作流执行到这个节点的时候,会直接结束这个工具调用,
自定义工具变量,也就是预设变量,方便工具的使用。
- 问题分类节点
在这个节点中,额外提供了背景知识这个概念
也就是在让LLM进行问题分类的同时,可以通过阅读背景知识来增强选择。
- 文本内容提取
官方提供的一个变量提取器,可以和变量更新节点配合使用
通过声明目标字段来进行提取字段
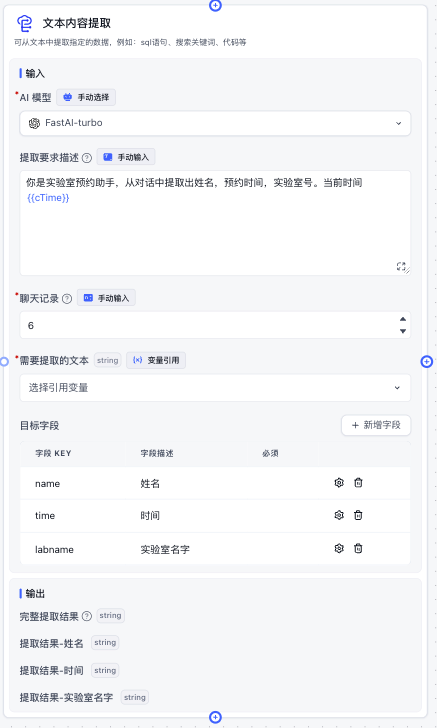
可以通过这些判断来决定是否开启下一阶段。
变量节点如下
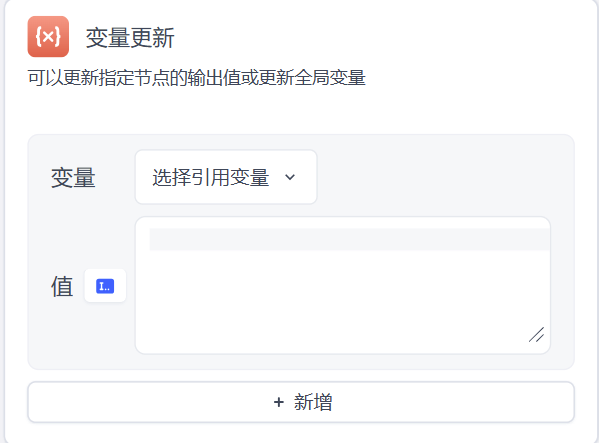
选择一个引用变量,并设置其的新值。
- 用户交互
在FastGPT中,提供了两种用户交互方式,一种是用户的选择,一种是用户的输入
对于用户的选择,则可以配置多种选项
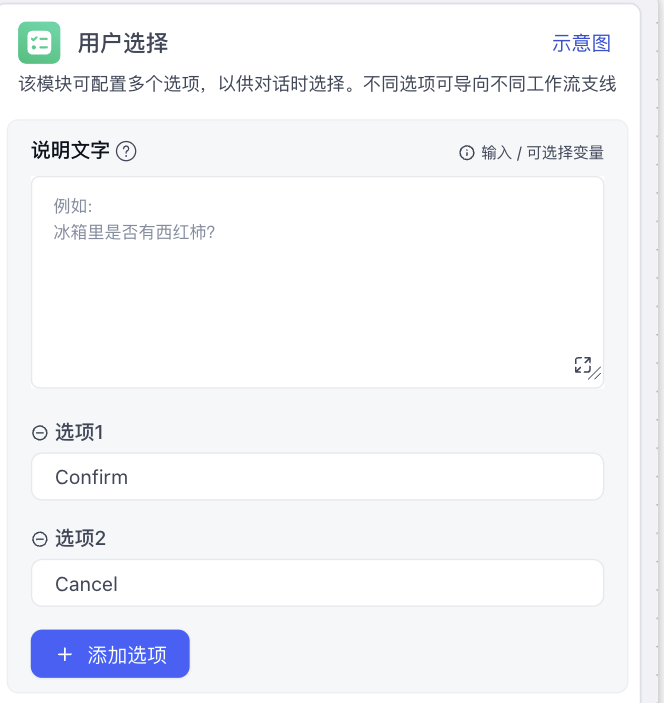
由用户选择获得下文变量
除此外就是表单输入
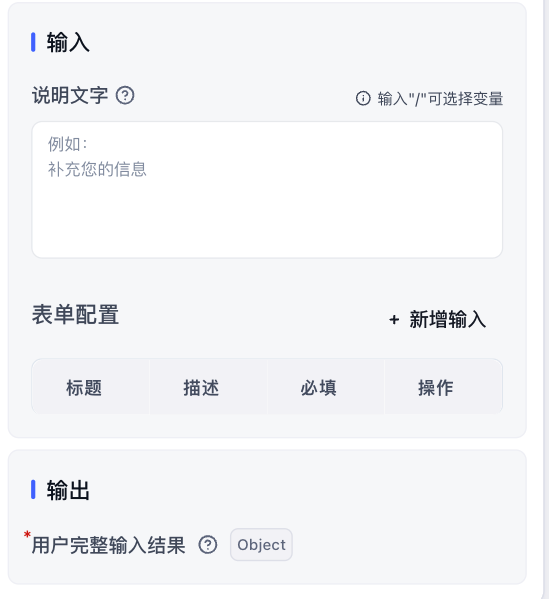
输入说明文字,告知用户为什么需要填写
以及新增表单配置,来增加部分的参数
让用户选择给予一些上下文信息,类似Dify的开始变量,只不过这是一种固定的选择。
- 文本拼接
对某些文本类型的变量进行加工,这也是一个不错的创新,这里可以注意,用户问题也是一种问题类型。
- 代码执行
这里需要注意,FastGPT仅仅支持js类型的代码,但是因为和Dify一样,代码最终运行在沙盒之中,无法进行网络请求和异步操作。
其中输入类似Dify,声明变量名一致即可
对于输出,则是需要返回一个Object对象
根据变量名来获取到object中的key
- 知识库结果合并
可以将多个知识库的结果合并为一个结果进行输出,通过RRF进行重新排序,并且支持通过token数量来进行过滤。
这也是一个非常优秀的优化点。
导入Gapier的Agent工具
FastGPT支持导入别人开发的Agent Tools,但是由于是使用Function Call来调用的工具,因此需要模型支持Function Call功能,这一点可以在模型配置中看到。