3. RAG
现阶段,FastGPT的知识库集成做的最为优秀,利用多种优化结合RAG模型实现了其中的知识搜索和文本生成。
那么既然其这么强,且在官网上进行了详细介绍RAG,那么我们就总结一下
https://doc.fastgpt.cn/docs/guide/knowledge_base/rag/
- 什么是RAG
RAG是将两种模型结合的混合架构,分别为检索模型和生成模型
检索模型从知识库获取到和用户输入相关的内容片段传递给生成器,生成器作为文本生成模型会基于这些检索内容生成自然语言输出。
对于检索器,主要任务是从一个外部知识库或者文档中获取到输入最相关的内容
利用了向量检索 也就是将输入转换为向量,然后利用相似度来进行匹配。适用于捕捉语义性。除此外还利用了传统检索算法,利用逆文档频率来进行排序和检索。适合简单的匹配工作。
其次是生成器,也就是最终的语言输出模型。这里我们不多赘述,大家可以理解为最常见的ChatGPT,deepseek。
那么结合两者,其工作起来流程为
- 先将用户的输入问题转换为向量
- 检索器从知识库中检索文档片段
- 将文档片段提供给生成模型,然后生成自然语言答案
- 返回给用户
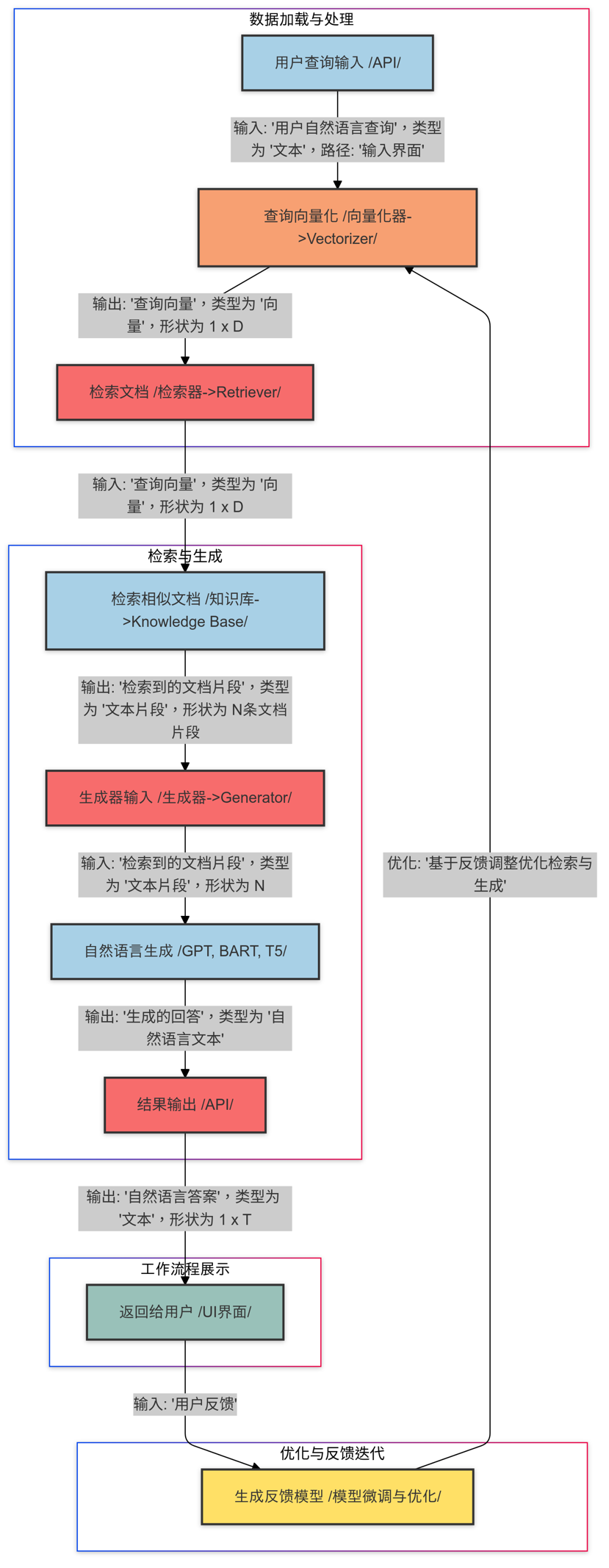
- RAG的优势和局限以及改进
RAG的优势可以分为如下几点
- 信息完整性,因为集合了两种模型,所以可以结合两者的优势,进行真实性的输出
- 知识推理能力,利用生成模型,可以进行知识推理
- 领域适应性强,由于可以和不同领域的知识库进行结合,所以在特定领域表现极好。
局限性则如下
- RAG模型中,生成的文本太过于依赖检索器的返回文档质量,如果检索的文档片段不相关,不连贯,会出现误导。
- 生成器的计算复杂度极高,因为可能传入大量的文本片段,那么会导致生成时间增加,响应速度慢的问题。
- 知识库的更新和维护,因为RAG模型依赖于一个强大的,预先建立好的外部知识库,那么其的维护和更新会影响到RAG的生成结果。
- 生成内容的不可靠,因为知识库可能存在多义性的问题,因此可能生成错误答案,那么配合RAG模型内部的黑箱特性,会导致用户对生成内容的不信任感。
为了解决上述说的局限性,RAG提供了改进方向。
主要分为几个方向
知识库的构建,数据库分块,检索优化,回答生成优化
对于知识库的构建
1.建立特定的数据集,采用特定的具有权威的数据来源,通过跨领域数据知识库建立,从而确保跨领域回答的正确性
2.建立数据质量审查和过滤机制,结合人工审查和自动化处理两个流程,确保数据来源可信,减少数据干扰。
3.引入自动化更新,比如网络爬虫等,将新的文档筛选后加入到之前的知识库,让知识更具有时效性。
4.建立合理的分段流程,一方面是算法去重,另一方面是引入后置重处理确保数据准确性。
5.优化数据储存格式,确保数据格式一致,使用JSON等结构化形式存储数据,便于高效查询。
6.建立用户反馈机制,通过这个反馈机制,帮助维护人员管理知识库。
对于数据分块的优化
RAG模型中数据分块和是RAG模型应用中的重要模块。如果具有合理的分块策略,那么可以在生成时提供清晰的上下文支持,反之如果分段不合理,可能要么取得的上下文是断裂的,要么是过多的,影响生成模型的速度。
相关的优化方向有
1.采用NLP来进行文本切割,确保每个文本拥有完整信息链
2.进行去重,简化内容,利用相似度算法识别冗余内容,避免内容重复出现的情况3.根据任务需求进行动态的分块。这一点可以通过数据库的划分实现,根据任务不同,设置不同分块粒度的数据库,比如问答的时候采用小粒度的分块,长文本的时候采用大粒度分块。
4.根据主题进行分块,利用主题分片模型来进行分块,比如医学特定的。
5.引入用户评估,生成内容时将分块一并返回用户,由用户打分来重新生成内容。
对于检索优化
因为检索中具有多种方式,比如BM25适合匹配关键字,DPR适合理解语义进行匹配。所以优化一般围绕算法选择进行检索优化。
1.采用混合策略。采用BM25关键词匹配和DRP深度语义匹配来一起匹配。
2.引入后置去重和排序优化,在检索结果中应用去重和排序,确保返回给生成模型的更加简洁,直接。
3.动态调整检索策略,根据不同任务调整不同的权重,比如金融场景倾向于关键词匹配。
对于生成模型的优化
因为依赖于生成器来生成自然语言答案。那么确保生成器得到的知识输入一致性就很重要,其优化可以考虑为
1.引入知识图谱
2.增加特定领域的生成规则和约束,比如医学,法律,设定一些回答模板,术语库来进行辅助
3.优化用户反馈机制,实现动态生成逻辑,这属于机器学习领域,微调模型对用户反馈进行分析。
4.引入一致性检测算法对内容进行统一管理,确保返回一致性。