4.FastGPT的知识库实现和调优
在FastGPT之中,我们采用了Embedding方案来构建知识库,这个Embeddeding的方案,是将文字或者图片转换为向量。然后在搜索的时候,计算不同向量之间的距离,也就是向量之间的相似度,从而得到最符合意思的大难。
因此在知识库实现中,向量的录入和搜索环节是最重要的。
在FastGPT之中,其将文本拆分为了小段的数据,并将数据转换为向量。
然后分别存储数据和向量
拆分下来就是如下图
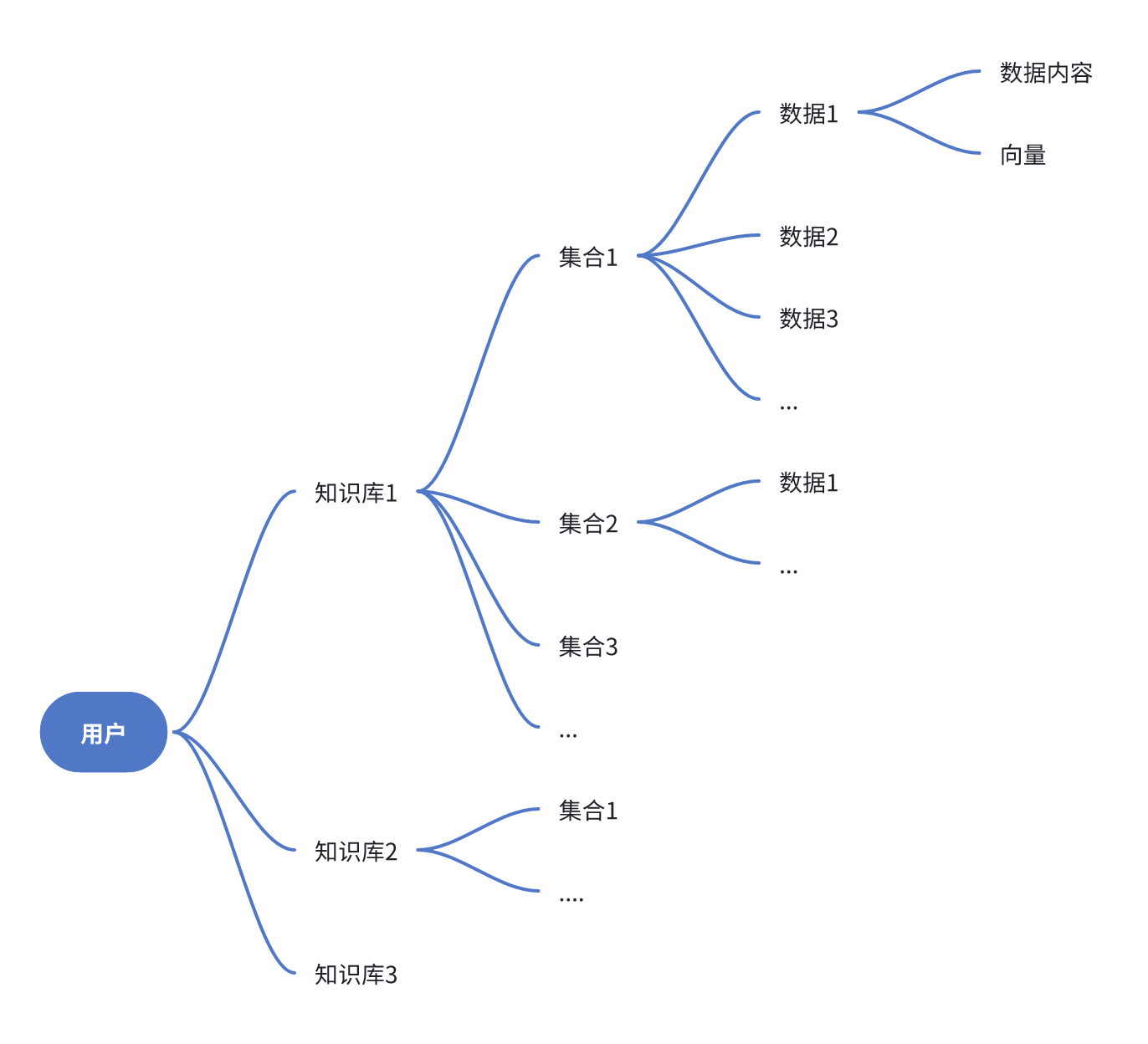
知识库中包含多个集合,集合可以理解为文件,文件中被拆分为多段,对应的就是数据,而数据分别以内容和向量的方式存储。
而在搜索的时候则以库为粒度进行搜索。
在FastGPT中,默认使用PostgresSQL中的PG Vector插件进行向量的检索。
实际的数据存储在MongoDB的dataset.datas表中。存储了index和原数据信息。
也就是先在PgSQL中进行向量的检索,然后在MongoDB中寻找原答案。
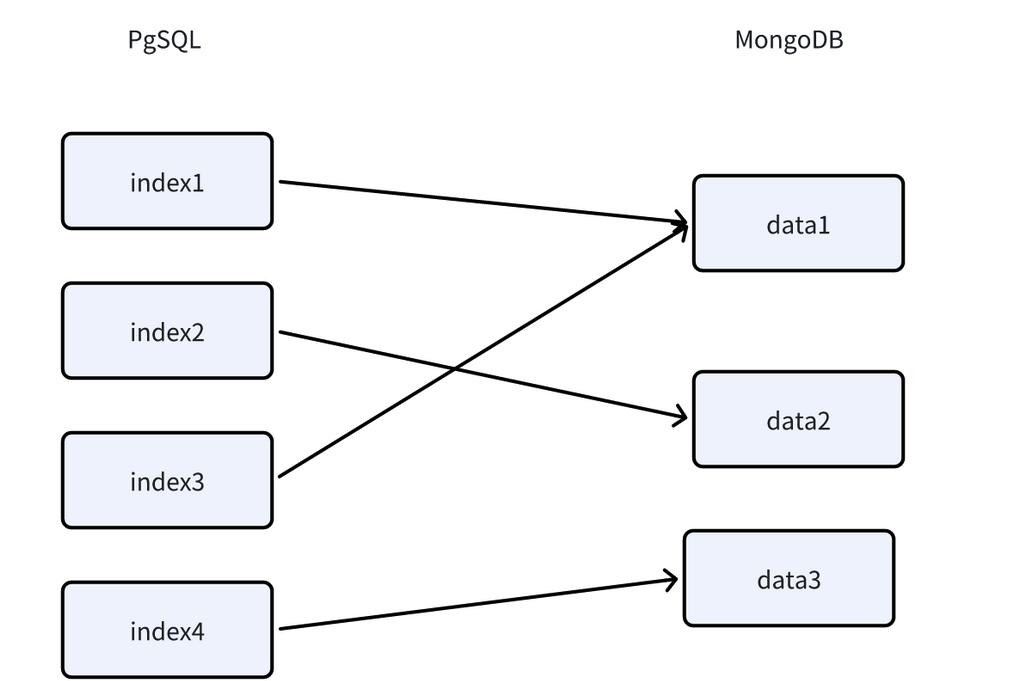
如果同一向量对应的数据被检索到了多次。那么会采取最高分为返回。
再之后,我们说下提高向量的搜索精度的方式和实现。
常见的有
提高分词分段的方式,如果一段话的内容完整,结果单一,那么在匹配时也会很精准,
精简index的内容。Index对应的内容少,会提高匹配精度
丰富index数量,一个chunk可以对应多组index
优化检索词,用户的问题往往是模糊或者缺失的,并不一定是一个完整清晰的问题。
微调向量模型,通过微调算法的方式,增强特定领域的检索效果。
对应到知识库之中。
可以通过问题优化来增强搜索
通过concat query 来增强连续对话准确性
通过Rerank模型来后置处理,提高精度。
通过RRF来合并多个查询库的结果。
相关的配置参数有
设置搜索模式,支持语义检索,全文检索,混合检索
语义检索是通过计算向量距离,得到相似度来进行匹配的
全文检索则是匹配关键词
混合检索则是同时匹配向量检索和全文检索,通过RRF来进行结果合并,这种情况往往需要引入Rerank模型来进行结果重拍
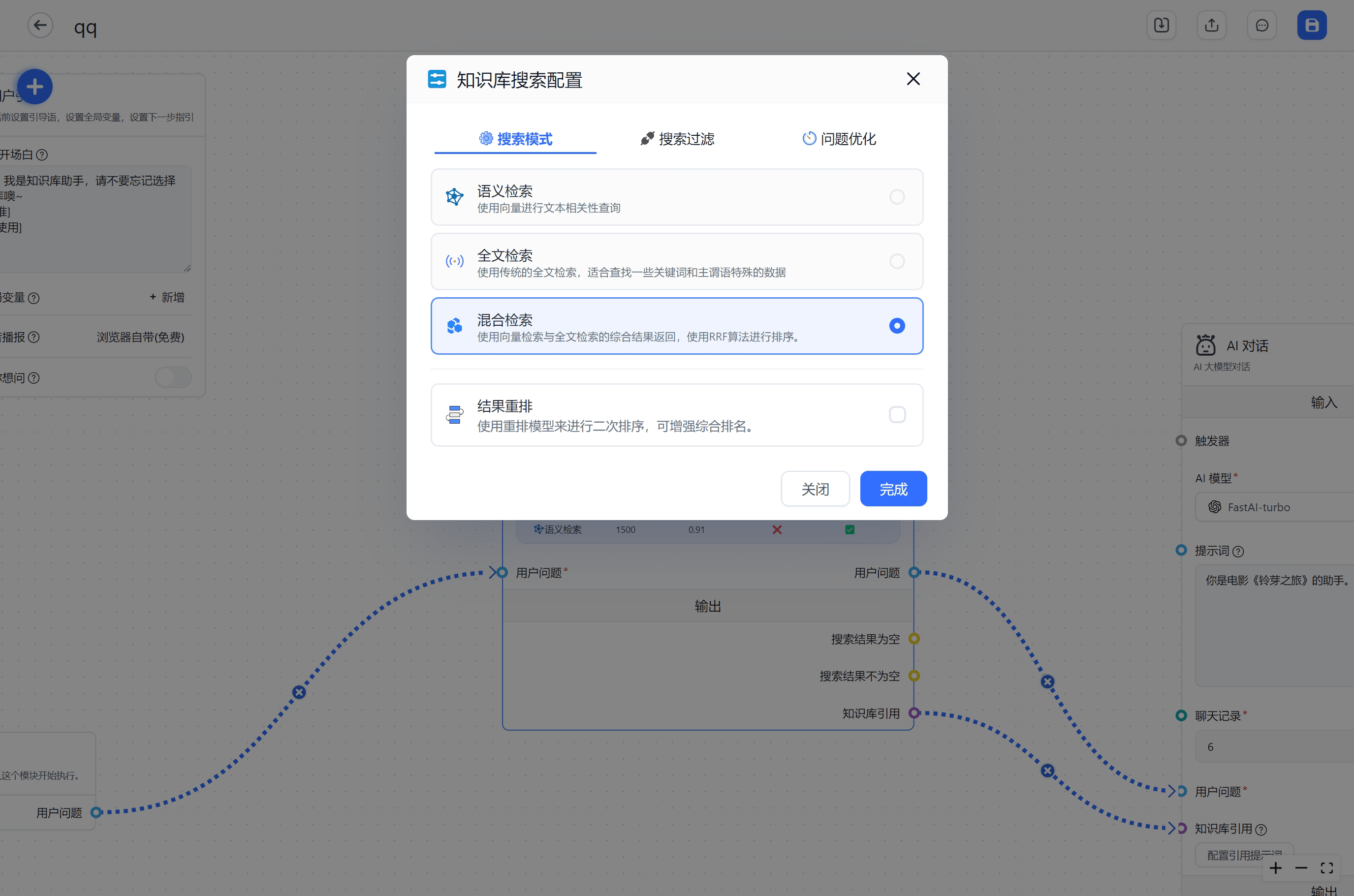
除此外还可以设置topk的引入。
设置最相关度,这些和Dify类似。
那么主要的不同点在于
增加了问题优化,可以将上下文加入到提示词中,进行问题的优化处理。
并且FastGPT虽然支持飞书知识库,语雀知识库,Web站点同步,外部文件库
但都是商业版才支持的功能。
社区版只有本地知识库和API文件库支持。