之前我们说了一些和聚合不相关的转换算子,比如map,mapPartitions,faltMap,filter
这次我们需要讲一下在Spark中和数据聚合相关算子,比如groupByKey,reduceByKey,aggregateByKey和sortByKey,而这些算子都涉及到Shuffle计算,也是Spark中比较重逻辑的一部分。
而且这几个算子,都是面对Paired RDD的,从而进行RDD内数据聚合
那么我们这次就说下这几个算子的使用
1. groupByKey,按组收集
对于PairedRDD,会先按照Key进行分组,然后把相关的Value值,以集合的形式收集到一起。也就是将RDD[(Key,Value)]转换为RDD[(Key,Value集合)]
使用起来也并不困难,我们拿WordCount来举例
val kvRDD: RDD[(String,Iterable[String])] = kvRDD.groupByKey()
从上面可以看出groupByKey使用并不困难,但是groupByKey存在着性能问题,这是由于groupByKey会将数据进行全量搜集,并在Shuffle后发送到相同的数据分区,这就导致数据量大的时候,会产生大量的磁盘IO或者网络IO,从而严重影响作业的执行性能。
不过一般groupByKey的使用频率不高,而是采用其他的聚合算子,那么我们就看看这些常用的聚合算子
2. reduceByKey 分组聚合
也就是按照Key值进行聚合,将Key相同的元素,聚合成一个元素
对应的代码可以如下参考
val wordCounts: RDD[(String,Int)] = kvRDD.reduceByKey((x:Int,y:Int) -> x + y)
上面的代码可以理解为
将PairedRDD的相同Key数据的Value进行了相加
而且我们在上面使用的是匿名算子,除了匿名算子,我们可以声明相关的具体函数,比如我们需要提取同一个Key的最大值,就比如如下的函数
def f(x:Int, y:Int): Int = {
return math.max(x,y)
}
然后直接reduceByKey(f)即可
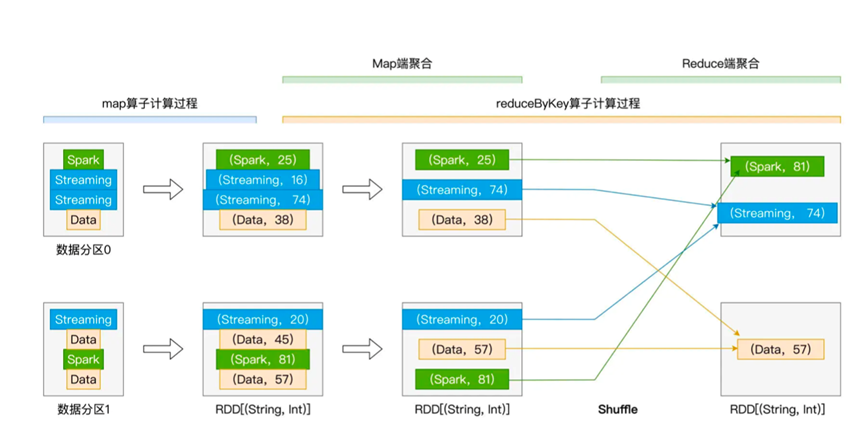
而且在使用过程中,由于Map端和Reduce段使用的聚合逻辑是一致的,是由函数f定义的,所以会进行一些优化,也就是在Map端的时候,就已经进行了预聚合,然后在reduce端进行二度聚合即可
由于这种优化的存在,在进行执行的时候,往往执行效率能至少提升一倍
不过reduceByKey存在的局限性是Map阶段和Reduce阶段的聚合逻辑要保持一致
如果我们希望Map阶段和Reduce阶段的逻辑不一致的话,可以考虑下面的aggregateByKey算子了
3. aggregateByKey 更加灵活的算子
聚合算子的参数比较多,需要提供三个参数,分别是一个初始值,一个Map端聚合函数f1,一个reduce端聚合函数f2
基本代码如下
rdd.aggregateByKey(初始值,f1,f2)
其中需要注意,f1的参数类型和f2要保持一致,而且f1的行参要和Paired RDD的value类型一致,初始值的类型也要和Paired RDD的value类型一致
具体的代码可以参考如下
def f1(x:Int, y:Int): Int = {
return math.max(x,y)
}
def f1(x:Int, y:Int): Int = {
return x+y
}
val wordCounts: RDD[(String,Int)] = rdd.aggregateByKey(0)(f1,f2)
这样就是在利用了和reduceByKey一样的优化,并且兼容了两种不同的聚合函数
最后则是sortByKey,字面意思是按照Key进行排序,使用方法也很简单,只需要在RDD上调用sortByKey()即可
然后如果需要按照升序或者倒序进行排列的话,只需要传入true或者false即可
如果按照降序进行排序的话,只需要传入false
那么我们总结一下今天说的几个算子,分别是groupByKey,reduceByKey,aggregateByKey和sortByKey
大致说明了这几个算子的用法和性能优化的点