上一章我们说了Spark调度系统的三巨头,DAGScheduler,Task Scheduler SchedulerBackend,了解了整体的调度过程,在整个调度中,尤其是DAGScheduler划分Stages的时候,是以Shuffle为依据进行了划分
那么在Spark中,我们需要看下这个重要操作Shuffle,
首先是什么是Shuffle
我们可以这么类比,比如我们作为一个京东物流,分别由三家公司需要购买三种不同的货物,体量还比较大,而我们每一个上流仓库,都保存这三种不同的货物,只不过每一个仓库的货物都无法单独满足公司需求,这就需要我们将其进行打乱调货,让每个上流仓库把货汇聚到离客户公司最近的仓库
Shuffle任务就是这样的,就是为集群范围内跨节点,跨进程的数据分发,在其执行过程中,需要引入大量的磁盘IO,网络IO,也就对应着现实生活中调度商品要用大量的人力物力
而虽然需要大量的资源消费,但是正如同显示生活一样,Shuffle操作应对的就是后续的一些聚合操作,是不可避免的。
那么接下来我们就讲解下Shuffle的工作原理
为了讲解这个算子的使用,我们拿一开始的Word Count的例子来说明,在之前的代码中,Shuffle操作对应的reduceByKey算子,也就是下面的代码
Var wordCounts: RDD[(String,Int)] = kvRDD.reduceByKey((x,y) => x+ y)
上面代码就声明了需要按照key进行shuffle
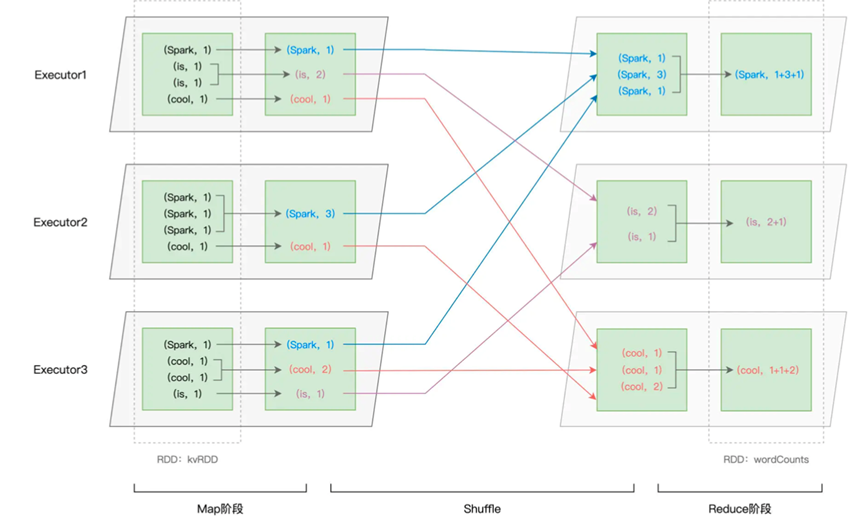
这个Shuffle操作可以大致分为两个阶段,分别是前置的Map操作和后续的Reduce阶段
在Map阶段,每个Executors的Task先对自己负责的数据进行初步聚合,然后发送给不同Reduce阶段,在Reduce阶段进行二次聚合
那么其中,Map如何把自己的初步聚合发送给Reduce算子就是我们需要了解的Shuffle操作,就是需要我们了解的数据交换操作
首先我们需要回忆,在DAGScheduler执行的时候,会为每一个Stage创建任务集合TaskSet,包含多个Task 分布式任务,Map阶段就包含了多个Task,那么每个Task都会生成一个初步聚合的中间文件
而这个中间文件,主要由两部分组成,分别是data文件和index文件,data文件记录原始数据,而index文件则是记录了下游Reduce阶段的Task和对应的data文件中的记录。
至于如何生成的index文件,则是Spark规定了一套的数据交换规则,默认是一个哈希算法算出来的,大致公式如下
P = Hash(Record Key) % N
P代表着Reduce阶段的Task编号,通过哈希计算得到的
那么这个中间文件的生成,就是Map端在初步聚合的时候,首先利用一个类似Map的数据结构进行初步聚合。Map中的key是 Reduce Task Partition ID,Record Key, value是默认值
然后不断的将数据放进去,当Map在内存中达到了声明的上线,就写入文件,这样不断的重复,直到所有的数据都被处理完成。
这样就将磁盘中的临时文件进行合并,生成最终的中间文件,叫做Shuffle write
这样就完成了Map端的处理过程,对于Reduce端的工作,则是由Reduce端通过网络从不同的节点的磁盘拉取,获取到属于自己的data文件
到此为止,就基本完成了Shuffle的流程
我们总结下,Shuffle是一种很消耗硬件资源的操作,但是却是不可缺少的一环
我们在本章介绍了Shuffle交换的整体过程,我们大致分为Map和Reduce阶段
并且讲解了两个阶段的操作步骤