7. FastGPT 配置模型
本次我们说下FastGPT中如何接入模型
分为了通过AI Proxy接入和OneAPI接入
同时还会讲解如何接入本地模型,分为了Ollama和Xinference两种
在FastGPT中,常见的接入是AI proxy,其是提前配置好了很多模型,从而方便用户对接。
除此外还可以使用OneAPI来进行接入。有OneAPI作为一个代理,面向FastGPT进行调用。
首先是AI Proxy的接入,如果是docker-compose部署的话,则默认加入了AI Proxy的配置
对于AI Proxy的使用,相对来说比较容易,可以说是开箱即用。
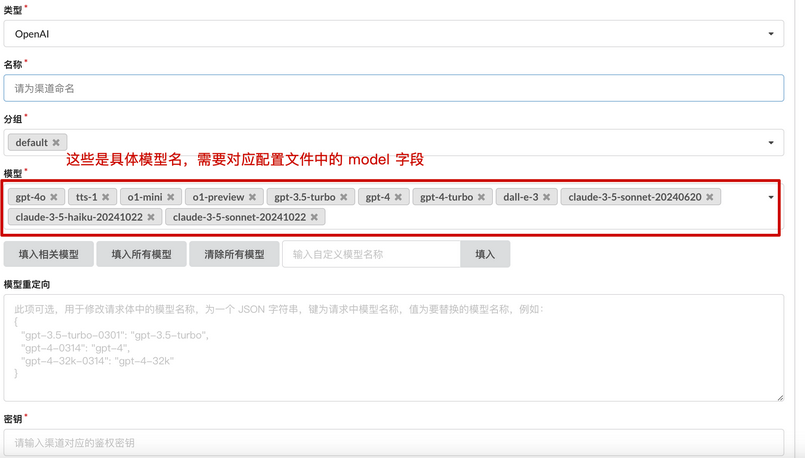
需要先创建一个渠道,在模型提供商页面,点击模型渠道,进行渠道配置
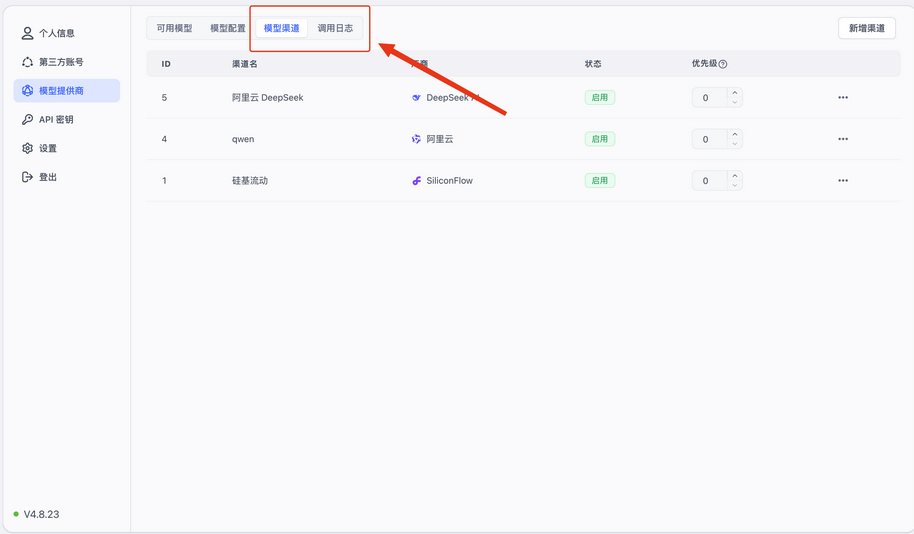
在新增渠道之中,填入厂商,选择模型后,输入代理地址和官方的API密钥即可,这里和Dify的使用一样。
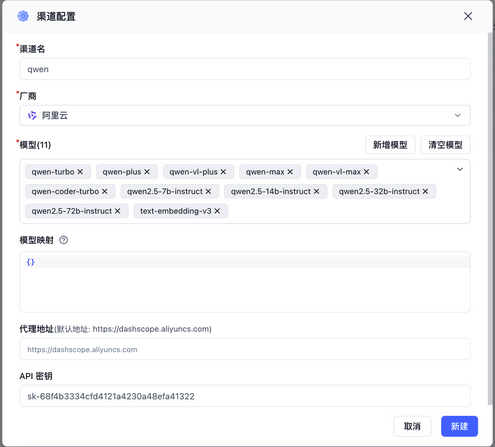
通过配置密钥及选择的模型列表,增加了模型提供商。
之后就可以启用模型了
如果模型是FastGPT提前定义好的,直接点击启用即可。
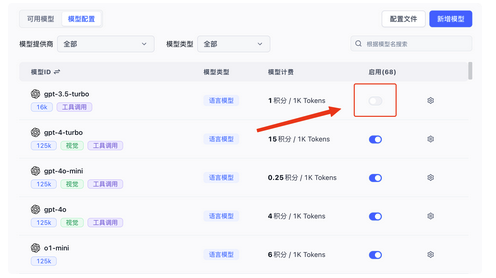
但是如果不是系统内置模型,那么可以添加自定义模型,在自定义模型中,如果模型ID和系统内置ID一致,那么会被认为修改系统模型。
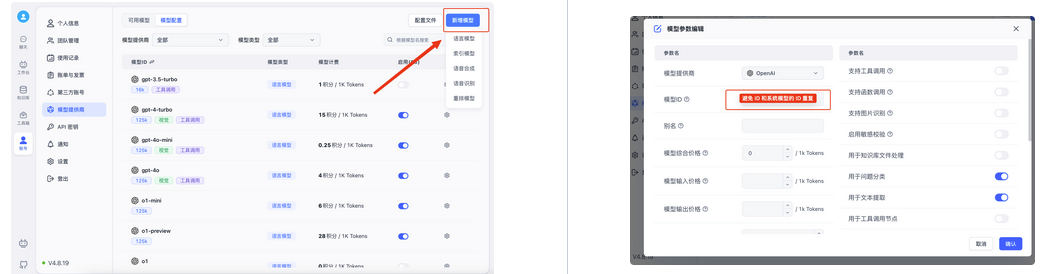
同时还支持配置文件式的新增模型
配置文件中的字段可以参考此链接
https://doc.fastgpt.cn/docs/development/modelconfig/intro/
在系统配置页面,还存在一个调用日志的页面。此页面可以查看发送给模型的请求记录,包括具体的输入输出,tokens等。
这页面的信息会保留1小时。
除此外就是OneAPI,FastGPT早期通过OneAPI作为代理来实现不同模型的对接。
因此需要在接入模型的时候,先在OneAPI之中配置一遍参数,再在FastGPT中配置一遍参数。
这里我们以Docker-compose的方式部署OneAPI
默认3000端口进行访问,这里可以通过docker-compose.yml选定进行新的端口映射。
在进入OneAPI之后,可以设置渠道
一个渠道类似一个供应商。比如配置OpenAI的渠道
之后可以创建OneAPI重的Api key来使用。
这时候还需要在FastGPT中的配置文件,将原本的AI proxy改为OneAPI

从FastGPT的默认配置中可以看出,FastGPT本身也是推荐使用AI Proxy而非OneAPI的。
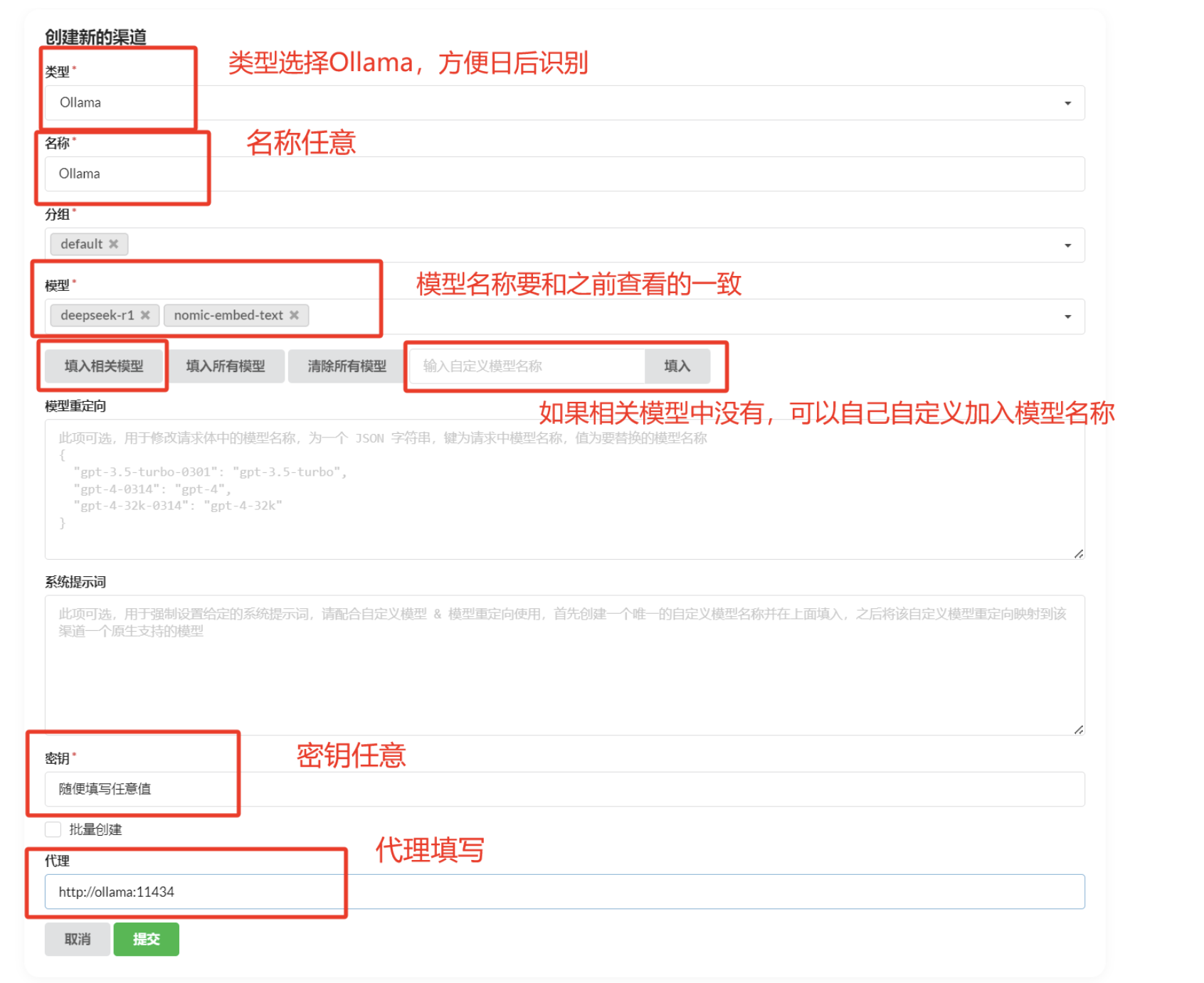
其次对于本地模型,常见的运行方式有Ollama和Xinference两种
如果是使用Ollama来进行接入,可以使用AI proxy和OneAPI两种。
如果是AI proxy则直接在账号中选择新增渠道
然后在渠道中选择Ollama,加入自己拉取的模型,填入代理地址即可。
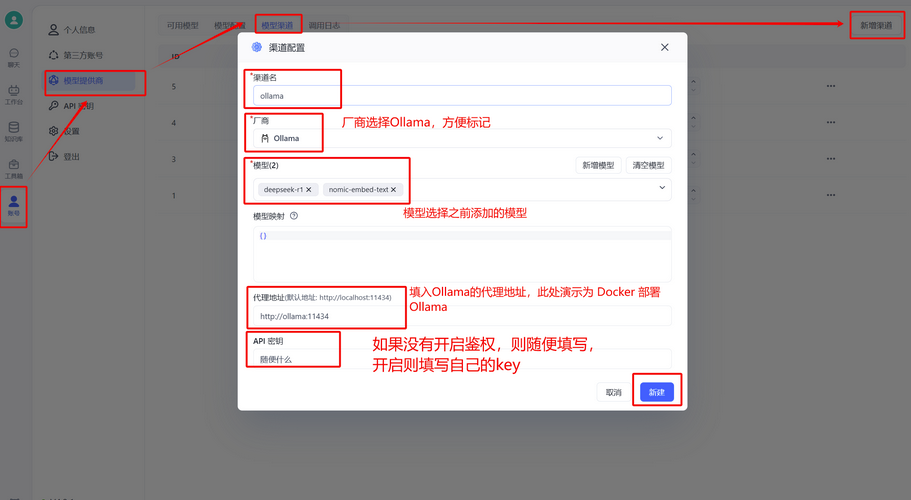
之后就可以在模型页面选择新增模型。
通过新增的方式来修改模型的供应商方式即可。
同样,如果是OneAPI的方式进行访问,则需要在OneAPI中创建新的渠道
然后填入代理地址即可。
之后就是通过令牌进行使用即可。
最后FastGPT还支持了直接接入
在FastGPT的docker-compose.yml文档中,将AI-PROXY和OneAPI相关配置都进行注释,在OPENAI_BASE_URL中加入ollama地址即可。

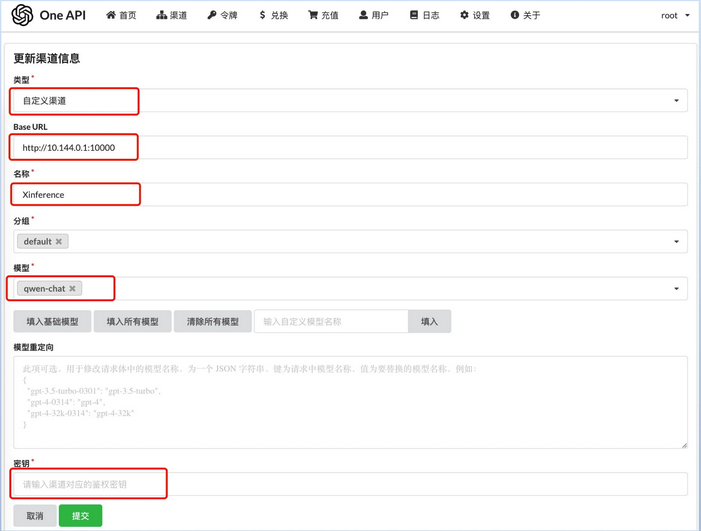
之后是Xinference的接入
其接入和Ollama类似,如果通过AI Proxy进行接入
也是遵循先增加渠道,然后新增模型的操作流程
如果是OneAPI
也需要先在One API之中增加一个Xinference服务的端点。
然后将令牌放入到FastGPT之中使用