8. FastGPT中PDF文档解析
因为在解析PDF的时候,经常遇到一些图片格式的PDF 文档,FastGPT默认集成的pdfjs库无法理解有效复杂的pdf文件,所以我们在解析pdf的时候,遇到图片格式的pdf会出现解析效果不佳的情况。因此可以在本地部署Marker的方式,增强PDF解析。
如果希望使用Marker,直接使用Docker进行快速部署即可
|
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
docker run –gpus all -itd -p 7231:7232 –name model_pdf_v2 -e PROCESSES_PER_GPU=”2″ crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2 |
其次是修改FastGPT中的systemEnv配置
|
{
xxx “systemEnv”: { xxx “customPdfParse”: { “url”: “http://xxxx.com/v2/parse/file”, // 自定义 PDF 解析服务地址 marker v0.2 “key”: “”, // 自定义 PDF 解析服务密钥 “doc2xKey”: “”, // doc2x 服务密钥 “price”: 0 // PDF 解析服务价格 } } } |
不需要填入key等信息,只需要写入url为可以访问到的docker地址。
这样我们可以在创建知识库和对话的时候进行使用PDF增强。
比如创建知识库的时候,可以在上传的时候勾选PDF增强解析
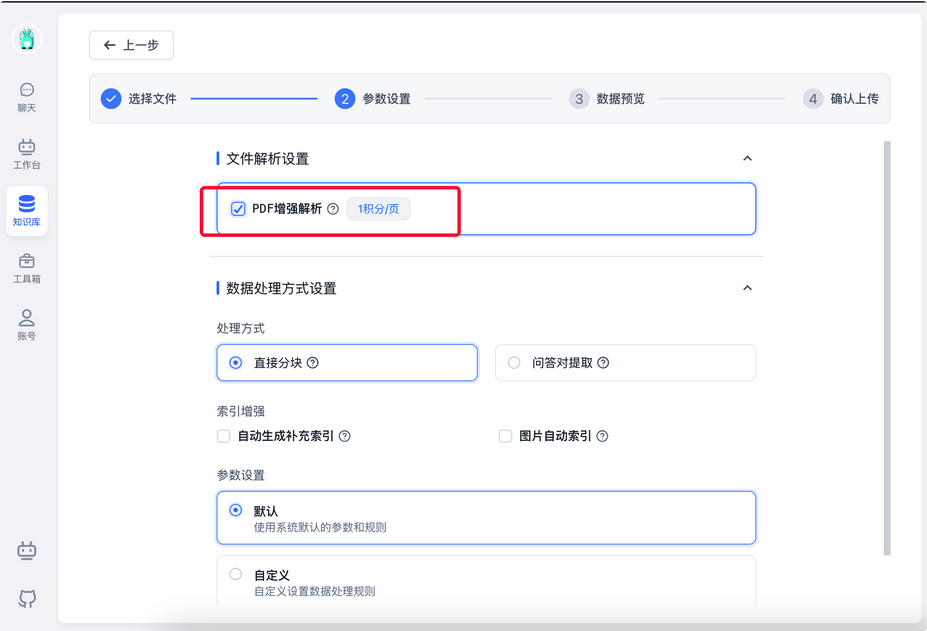
如果是在对话应用中,可以在文件上传中勾选上PDF增强解析
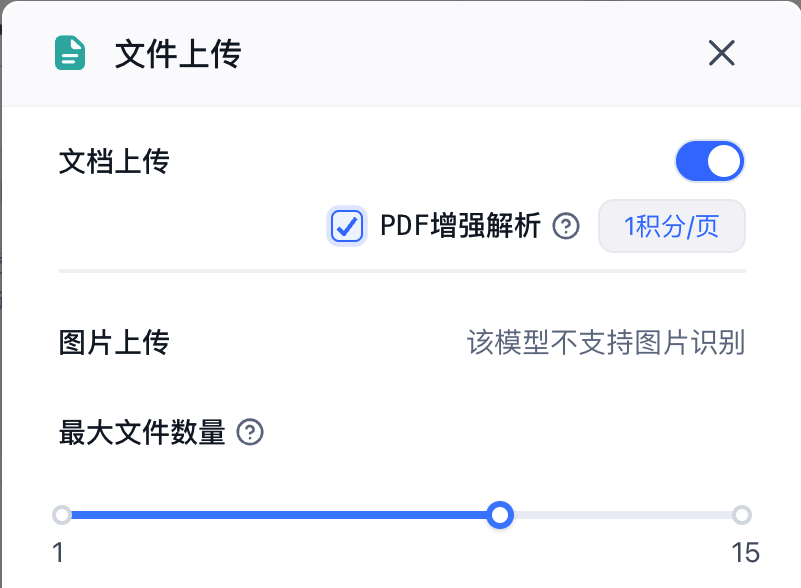
如果是老版本的FastGPT,则可以在FastGPT的环境变量中配置
CUSTOM_READ_FILE_URL – 自定义解析服务的地址, host改成解析服务的访问地址,path 不能变动。
CUSTOM_READ_FILE_EXTENSION – 支持的文件后缀,多个文件类型,可用逗号隔开。