MCP中的采样机制
在MCP中,采样机制是一个强大的功能,是让服务器代替客户端去请求语言模型LLM的生成结果,实现复杂的代理机制。
其常见于服务器可以读取数据,一部分自己处理,一部分交给AI分析和解释数据。
服务器交给AI分析代码库。或者在一个复杂的文档操作场景中,一部分交给AI来设计处理。
这一功能让MCP服务器自己也拥有大脑。
而且这个请求,并不会越过用户,而是采用了一种人在环路中的设计,让交互过程中的用户保证了对LLM的绝对控制权。
整体来说,这个机制包含如下流程。
- 服务器发出请求 对应的就是sampling/createMessage到客户端
- 客户端接收请求,允许用户审核和修改请求
- 客户端调用语言模型生成结果,语言模型处理并批准请求并获取到内容
- 内容审核,客户端向用户展示内容,让用户审核。
- 最终将用户审核后结果返回给MCP服务器。
这种设计让用户牢牢把控了对AI系统的控制,增强了透明度和可信度。最终提供了互动指南和模板。
并且在MCP内部,采样请求有着标准化的消息格式
|
{
“method”: “sampling/createMessage”, “params”: { “messages”: [ { “role”: “user”, “content”: { “type”: “text”, “text”: “用户的问题” } } ], “modelPreferences”: { “hints”: [{“name”: “claude-3”}], “costPriority”: 0.5, “speedPriority”: 0.7, “intelligencePriority”: 0.8 }, “systemPrompt”: “你是一个助手…”, “includeContext”: “thisServer”, “temperature”: 0.7, “maxTokens”: 1000, “stopSequences”: [“\n\n”], “metadata”: { “requestType”: “query” } } } |
在其中包含一些关键部位
首先是消息的数组,包含了历史对话消息,每条消息有着角色和内容两方面
角色可以使user或者assistant
内容和之前的tool返回相似。
其次是模型偏好,这样Server有一定的建议,让客户端可以进行模型选择,其中通过hints来指定推荐的模型,诸如 claude-3, 优先级参数, costPriority 成本参数,speedPriority速度参数, intelligencePriority 能力参数
之后是系统提示,这是一个系统的提示词工程,可以设置语言模型的角色和行为指南。
上下文包含,这个包含三个选项,none,thisServer,allServers
采样参数, temperature 控制随机性, 最大生成令牌数量, stopSequences 停止生成的序列数组。
这里我们通过一个完整的代码来说明采样机制的内部运转过程。
利用采样机制,来让用户的文件系统查询转发给语言模型,获取到专业解答,同时利用上面的人在环路中的设计,让交互过程中的用户保证了对LLM的绝对控制权。
首先是服务器端实现采样功能
|
@app.get_prompt()
async def get_prompt( name: str, arguments: dict[str, str] | None = None ) -> types.GetPromptResult: “””根据名称和参数获取提示内容””” if name == “file-system-assistant”: question = arguments.get(“question”) if arguments else “” # 构建采样请求 sampling_request = { “method”: “sampling/createMessage”, “params”: { # 各种参数设置 # … } } # 将采样请求作为响应返回 return types.GetPromptResult( messages=[ types.PromptMessage( role=”assistant”, content=types.TextContent( type=”text”, text=json.dumps(sampling_request, ensure_ascii=False) ) ) ] ) |
返回给客户端之后,将提示结果返回给客户端
在客户端,主要分为两个方面,一方面是关于采样请求的解析,另一方面是关于给用户反馈并交由用户确认
|
# 解析服务器发送的采样请求
sampling_request_json = prompt_result.messages[0].content.text sampling_request = json.loads(sampling_request_json) # 检查是否是采样请求 if sampling_request.get(“method”) == “sampling/createMessage”: params = sampling_request.get(“params”, {}) # 处理请求参数 # … # 构建语言模型请求 messages = [] if “systemPrompt” in params and params[“systemPrompt”]: messages.append({“role”: “system”, “content”: params[“systemPrompt”]}) for msg in params.get(“messages”, []): if msg.get(“content”, {}).get(“type”) == “text”: messages.append({ “role”: msg.get(“role”, “user”), “content”: msg.get(“content”, {}).get(“text”, “”) }) # 调用语言模型 response = self.client.chat.completions.create( model=”deepseek-chat”, messages=messages, temperature=params.get(“temperature”, 0.7), max_tokens=params.get(“maxTokens”, 1000) ) |
上面表格中展示了客户端如何去根据采样请求来组织发给大模型的请求。
另一方面我们也说了,采样功能还需要包含人机协作机制,确保用户对AI保持控制。
|
# 显示采样请求给用户
print(“\n服务器发送的采样请求:”) print(f”系统提示: {params.get(‘systemPrompt’, ”)}”) print(f”温度: {params.get(‘temperature’, 0.7)}”) print(f”最大令牌数: {params.get(‘maxTokens’, 1000)}”) # 让用户确认或修改采样参数 print(“\n是否要修改采样参数?(y/n)”) if input(“> “).lower() == ‘y’: # 用户修改参数 # … # 显示采样结果给用户 print(“\n采样结果:”) # … # 让用户确认或修改结果 print(“\n是否要修改结果?(y/n)”) if input(“> “).lower() == ‘y’: print(“\n请输入修改后的结果:”) sampling_result[“content”][“text”] = input(“> “) |
通过这种的代码,我们简单实现了采样的交互流程,这样,我们通过简单的演示来看下整体流程。
首先是启动并初始化了服务器和客户端的链接,之后输入一个问题
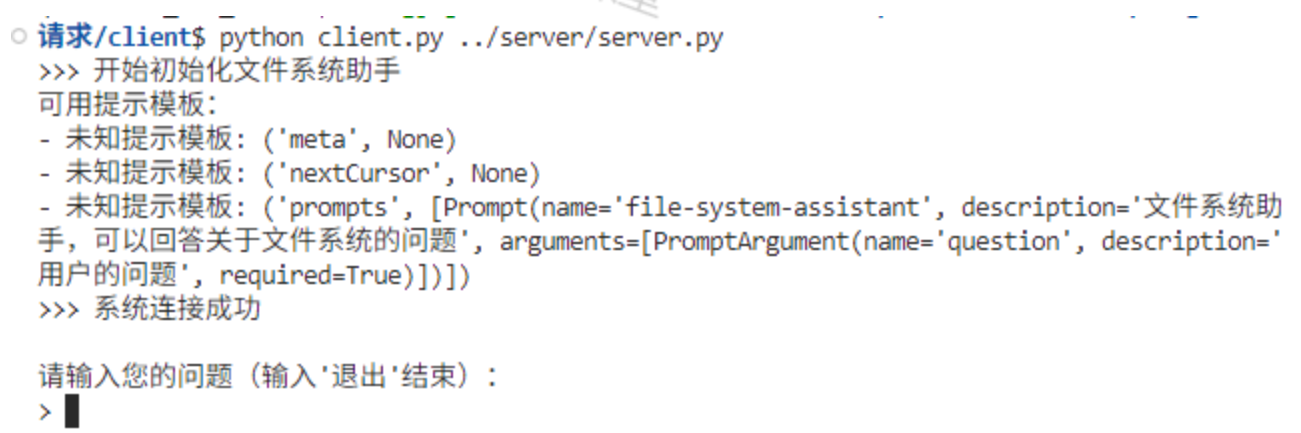
然后MCP Server收到请求后,返回采样请求,客户端询问是否调整大模型请求参数

之后我们进行交互完成,让客户端修改完成后启动LLM调用,返回结果。

最终获得到了大模型结果。
当然在这个采样过程中,不会涉及到真实情况中,和文件系统的真实交互。
不过也是可以简单介绍下MCP中的采样实现方式。
其主要流程是,客户端调用 session.get_prompt()。 服务器返回JSON采样请求
客户端解析这个请求, 和用户进行交互, 调用Deepseek API, 处理结果返回用户交互。
而在一个sampling/createMessage内部,还能有很多控制内容生成的行为和特性。
- 停止序列
指定一系列的字符串,当模型生成到特定字符串的时候停止
sampling_request[“params”][“stopSequences”] = [“\n\n”, “结束”, “###”]
- 模型偏好
- 包含上下文,这个是控制LLM能够访问的上下文进度
- 系统提示工程,支持传入系统提示词
- 历史上下文,构建消息,也就是对话历史来引导模型的行为。
|
sampling_request[“params”][“messages”] = [
{ “role”: “user”, “content”: { “type”: “text”, “text”: “如何查找大文件?” } }, { “role”: “assistant”, “content”: { “type”: “text”, “text”: “您可以使用’find’命令来查找大文件。具体来说,您可以…” } }, { “role”: “user”, “content”: { “type”: “text”, “text”: “如何删除这些文件?” } } ] |
总结一下,本章我们阐述了MCP中的采样能力,其为服务器和AI直接沟通搭建了一个桥梁。
同时利用用户参与设计,保证了用户的掌控性。