4. Dify使用 跟着官方文档做应用-创建文本解析工作流
这里我们创建一个文本解析工作流,在该工作流之中,我们需要让用户上传一个或多个文件然后对文件进行提取文本,之后经过两个LLM解析,最终输出
整体如下
- 创建工作流

- 添加一个开始节点,同时在其中声明用户需要开始的时候上传的文档
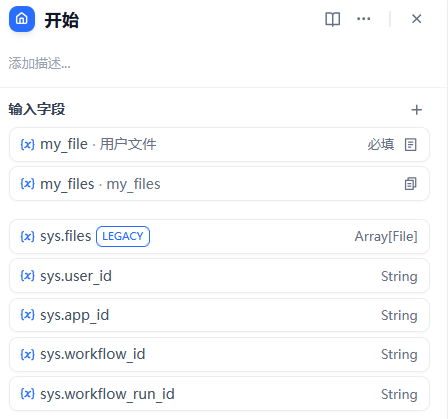
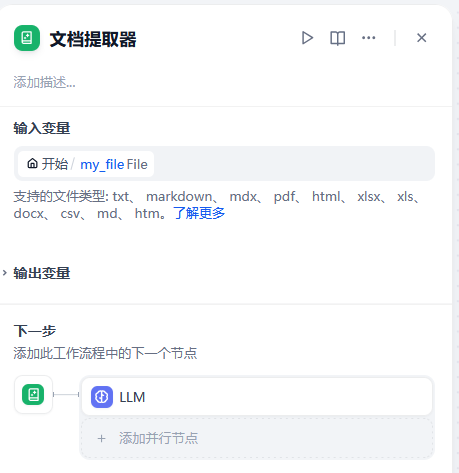
- 创建文档提取器
通过在其中声明使用开始节点中用户必填的输入字段 my_file来作为输入,进行文档的提取
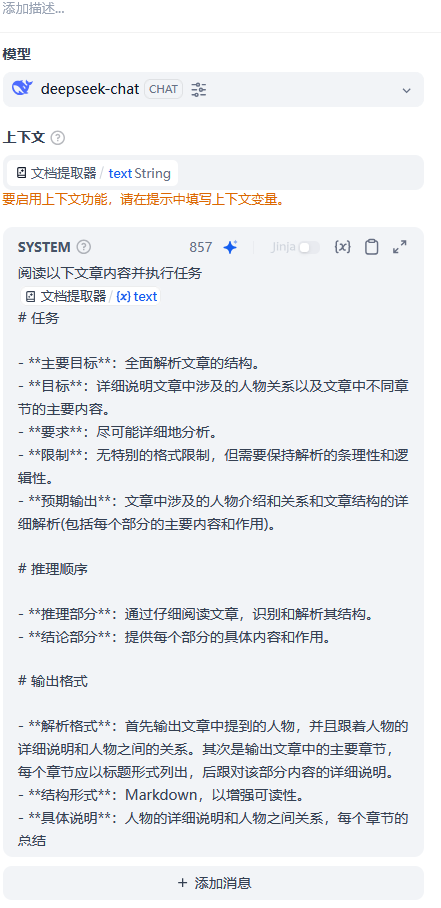
- 之后是两个LLM节点,一个负责对文章中人物关系进行总结,另一个负责对总结后的人物关系抛出问题,提示词分别如下
文章总结:
|
阅读以下文章内容并执行任务
{{#text#}} # 任务 – **主要目标**:全面解析文章的结构。 – **目标**:详细说明文章中涉及的人物关系以及文章中不同章节的主要内容。 – **要求**:尽可能详细地分析。 – **限制**:无特别的格式限制,但需要保持解析的条理性和逻辑性。 – **预期输出**:文章中涉及的人物介绍和关系和文章结构的详细解析(包括每个部分的主要内容和作用)。 # 推理顺序 – **推理部分**:通过仔细阅读文章,识别和解析其结构。 – **结论部分**:提供每个部分的具体内容和作用。 # 输出格式 – **解析格式**:首先输出文章中提到的人物,并且跟着人物的详细说明和人物之间的关系。其次是输出文章中的主要章节,每个章节应以标题形式列出,后跟对该部分内容的详细说明。 – **结构形式**:Markdown,以增强可读性。 – **具体说明**:人物的详细说明和人物之间关系,每个章节的总结 # 示例输出 ## 示例文章解析 ### 人物信息: #### 小红帽 – **背景**:美丽的小红帽,故事的女主角,性格天真开朗。 – **关系**:和猎人和奶奶生活在森林里,害怕大灰狼。 #### 大灰狼 – **背景**:要吃人的大灰狼,在故事中吞下了小红帽的奶奶,对小红帽垂涎三尺。 – **关系**:吞下了小红帽的奶奶,被猎人击杀。 ### 章节总结: #### 小红帽收到了将面包送给奶奶的任务 – **总结**:小红帽收到了妈妈给予的任务,要将新烤出来的面包送给奶奶。 #### 大灰狼吃掉了奶奶 – **总结**:小红帽的奶奶被大灰狼吞下来了,同时知道了小红帽要送面包过来,因此准备吃下小红帽 # 备注 – **边缘情况**:如果文章结构不典型(例如,缺少某些部分或有额外的部分),应在解析中明确指出这些特殊情况。 – **重要考虑事项**:解析时应关注人物之间的关系,反复的进行推测,并详细的总结文章内容。 |
问题生成
|
阅读以下文章总结并执行任务
{{#text#}} # 任务 – **主要目标**:全面阅读上文,针对人物之间的关系提出尽可能多的问题。 – **要求**:问题要有意义和价值,值得思考。 – **限制**:无特定限制。 – **预期输出**:一系列针对文章各个人物关系的问题,每个问题都应有深度和思考价值。 # 推理顺序 – **推理部分**:全面阅读文章,分析文章各个部分的内容,思考每个部分可能引发的深层次问题。 – **结论部分**:提出有意义和有价值的问题,确保问题能够引发深入的思考。 # 输出格式 – **格式**:每个问题单独成行,编号列出。 – **内容**:针对文章的各个部分(如引言、背景、方法、结果、讨论、结论等)提出问题。 – **数量**:尽可能多,但每个问题都应有意义和价值。 # 备注 – **边缘情况**:如果文章的某些部分内容较少,可以适当调整问题的数量和深度,但每个问题都应有思考价值。 – **重要考虑事项**:确保问题能够引导读者深入理解文章内容,而不仅仅是表面的疑问。 |
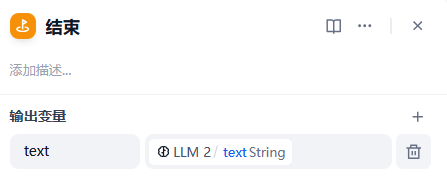
最后通过结束节点
将最后一个LLM的输出展示给用户
在此基础上,还可以将其进行修改,比如我们有两个LLM,分别是在线的Deepseek满血版和本地的残血版
那么我们可以设置一下
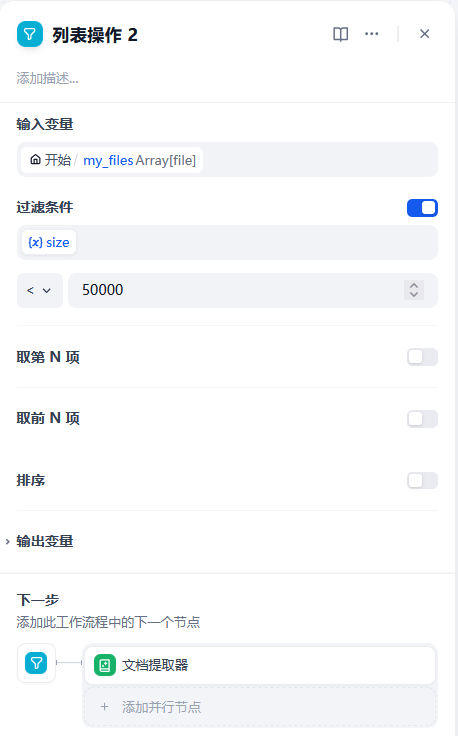
当上传的文件列表中,某个文件的大小小于50KB,那么由本地处理,大于则由满血版处理
整体形成如下列表
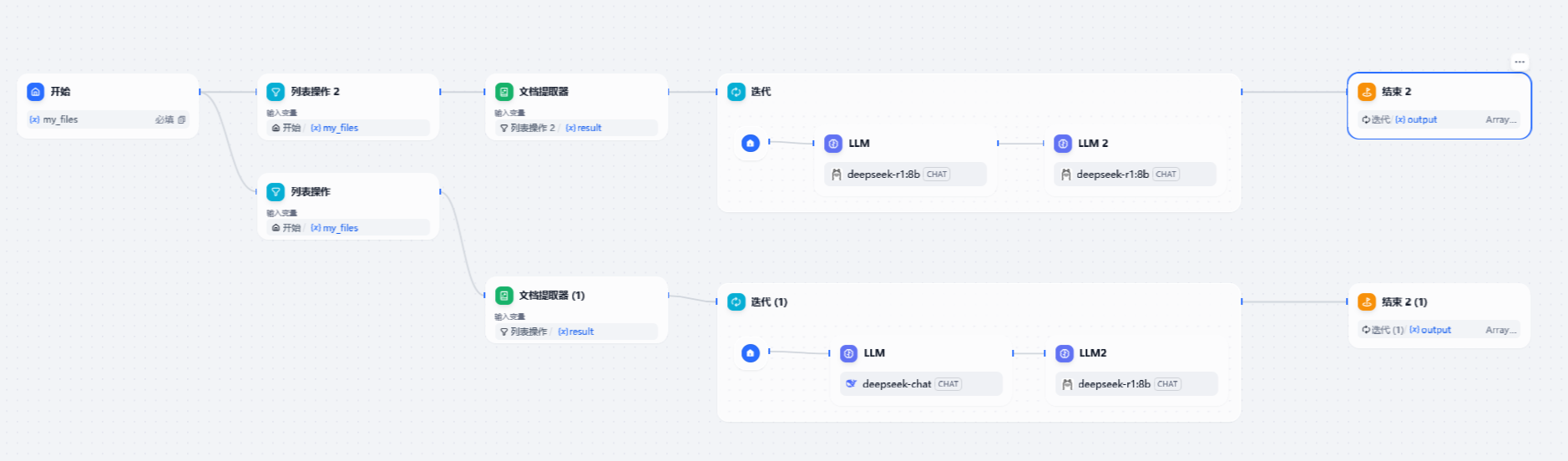
只需要在开始之后接入两个列表操作,主要在其中设置过滤条件
然后设置文档提取器,之后跟着一个迭代操作
迭代操作如下
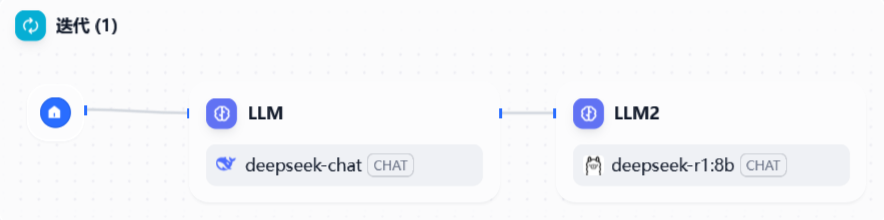
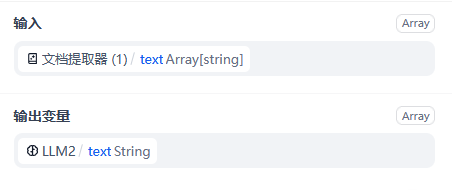
迭代操作中,开始后跟着两个LLM
第一个LLM中读取上下文中的item文本,第二个接着读取第一个LLM的输出
最后将其作为整体输出到控制台即可