6. 跟着FastGPT做应用一: 长文本翻译器
这是一个官方提供的模板,其目的是对用户输入或者上传的文件进行翻译。
其核心思路在于对于长文本来说,LLM无法很好的进行一口气翻译,因此需要进行分段,循环的翻译,最后拼接式的进行输出。
那么我们看下如何搭建这样的一个工作流。
首先在工作流的系统参数中,开启文本上传,设置开场白
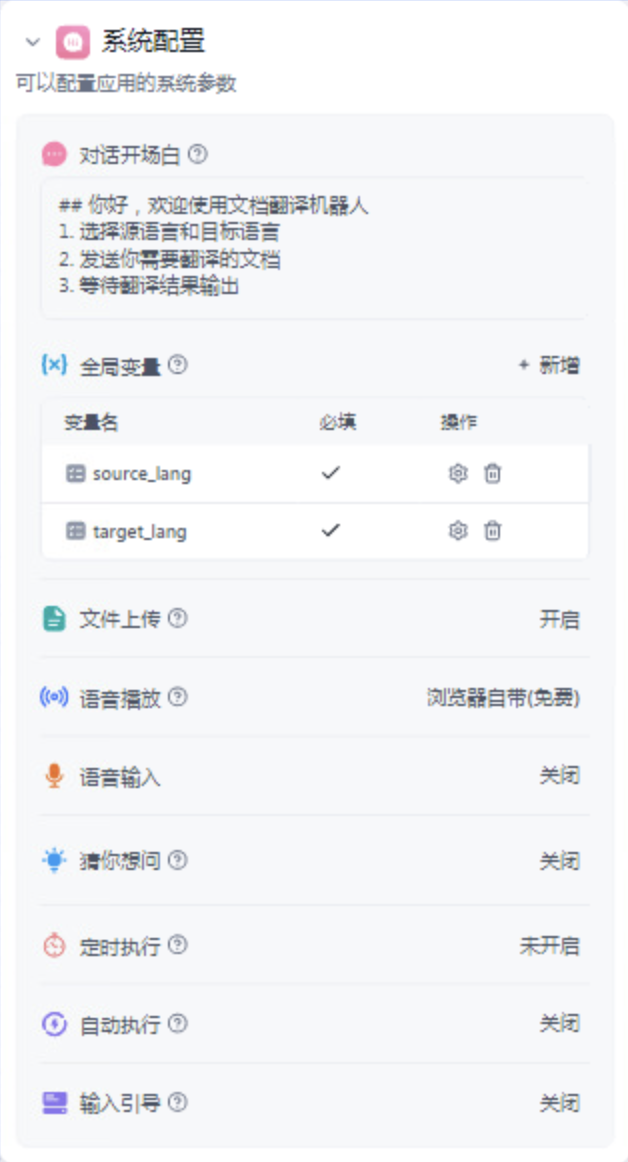
之后在开始流程之后,挂在一个代码节点,用于判断用户选择的两个变量是否是一致,从而让用户重新开启对话。
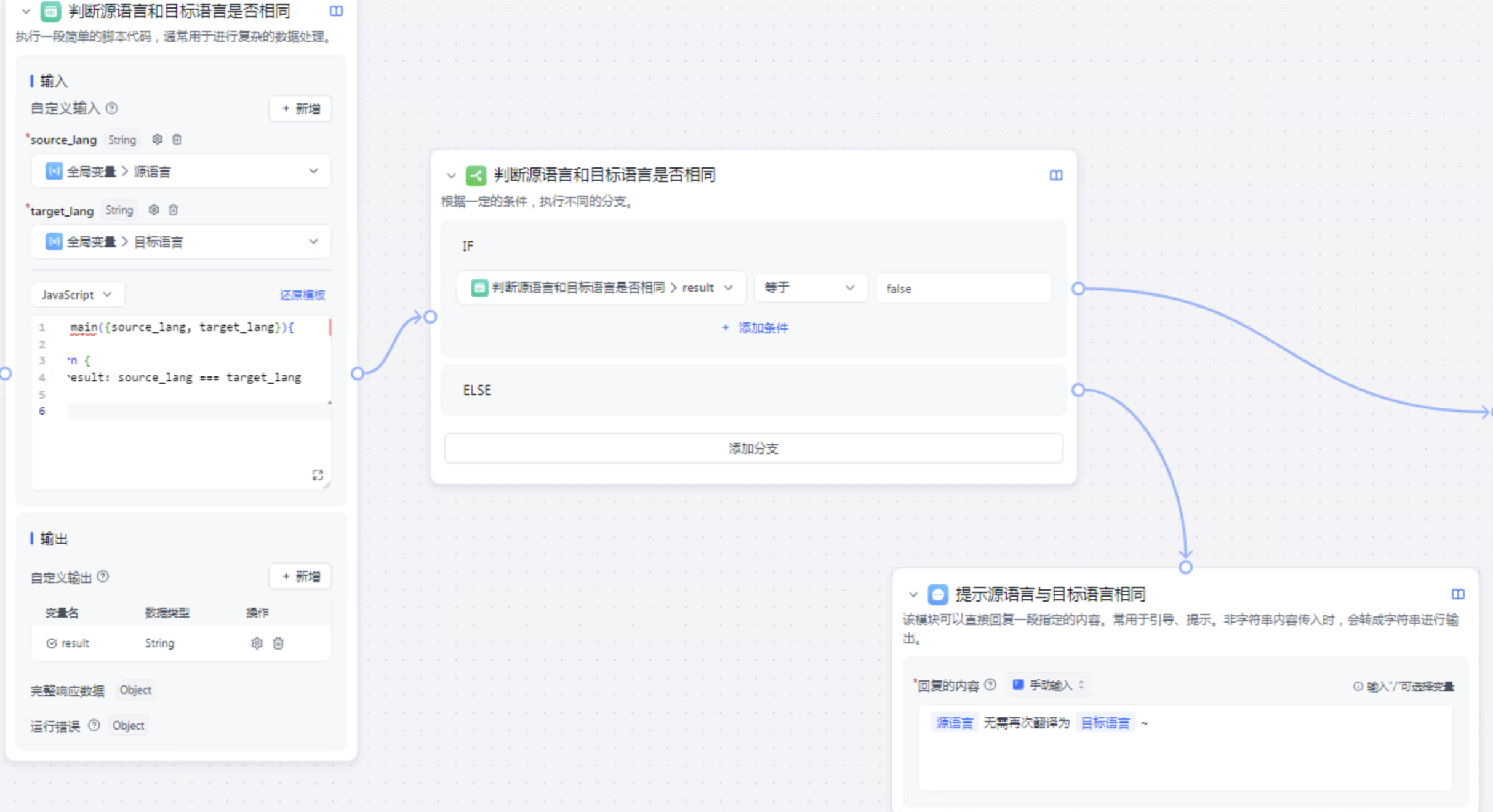
之后判断用户是利用对话框进行的翻译,还是通过上传文件进行翻译。
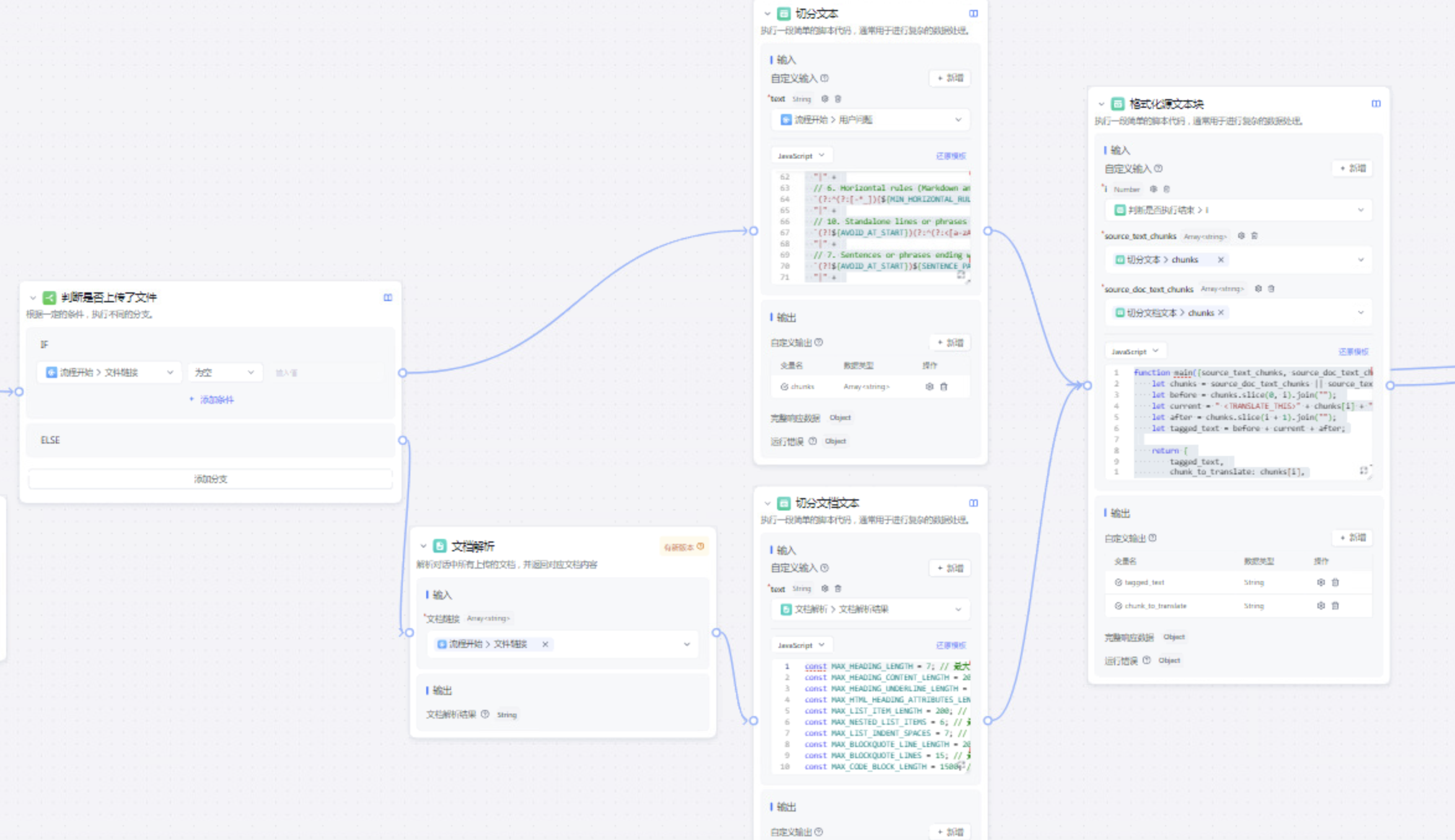
其中判断的代码简单,主要是切分文本的代码
在文本切分中,主要包含正则表达式和代码两部分组成。对于代码。
则是按照1000Tokens为粒度进行了切分
function main({text}){ const chunks = []; let currentChunk = ”; const tokens = countToken(text) const matches = text.match(regex); if (matches) { matches.forEach((match) => { if (currentChunk.length + match.length <= 1000) { currentChunk += match; } else { if (currentChunk) { chunks.push(currentChunk); } currentChunk = match; } }); if (currentChunk) { chunks.push(currentChunk); } } return {chunks, tokens}; } |
其中输出的chunks数组,其中每一个下标都是一个可以被LLM阅读翻译的字段。
在获得这样的一个整体输入后,需要以一个循环的方式,进行翻译输出。
首先是格式化原文本。
function main({source_text_chunks, source_doc_text_chunks, i=0}){ let chunks = source_doc_text_chunks || source_text_chunks; let before = chunks.slice(0, i).join(“”); let current = ” <TRANSLATE_THIS>” + chunks[i] + “</TRANSLATE_THIS>”; let after = chunks(i + 1).join(“”); let tagged_text = before + current + after; return { tagged_text, chunk_to_translate: chunks[i], } } |
这里是将需要当前一轮翻译的文本通过<TRANSLATE_THIS> 标签包裹起来。
那么下一步,必然就是利用LLM进行翻译及输出了
这里我们对LLM节点进行了客制化,主要分为用户问题和提示词两方面。
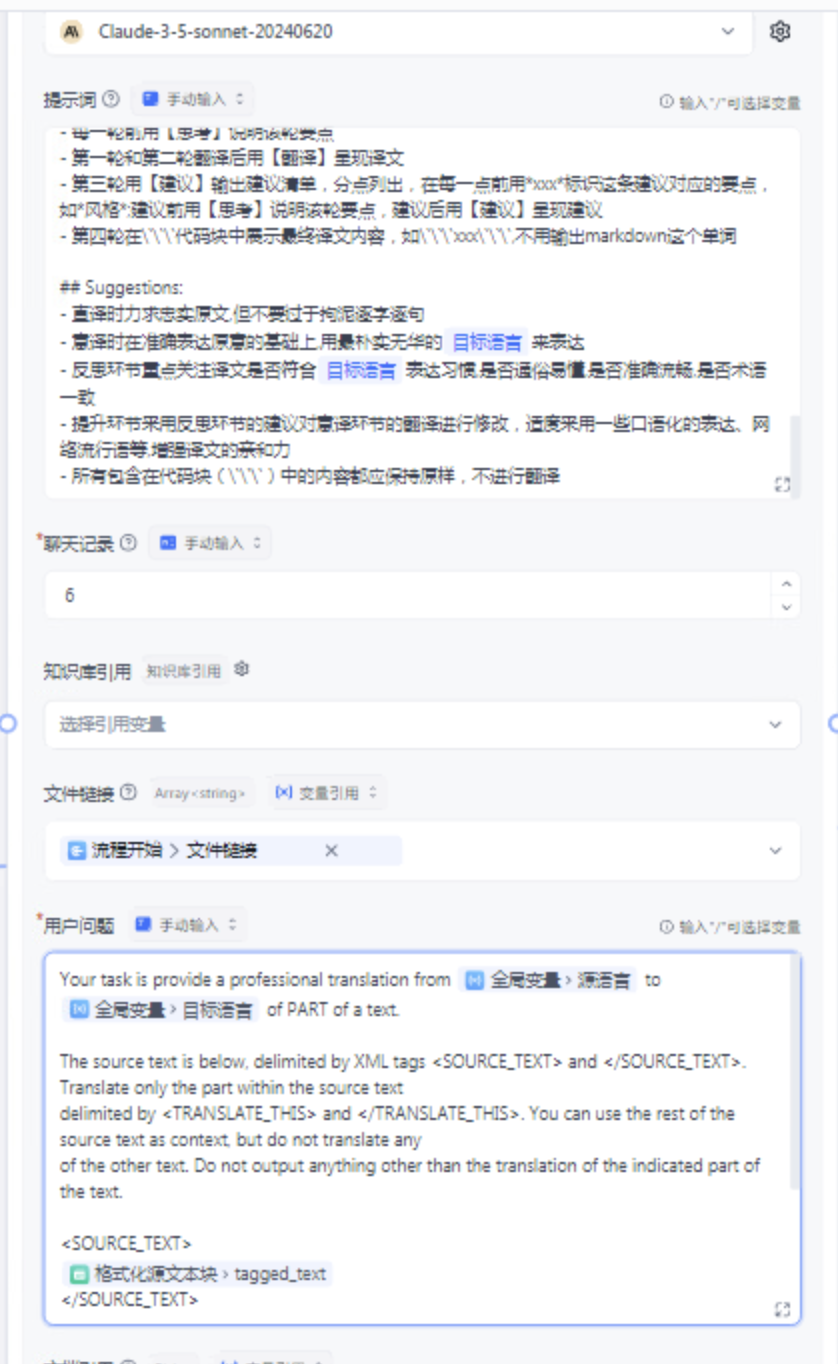
对于用户问题,我们进行了格式化处理,目的是告诉LLM,用户传入的文本格式
Your task is provide a professional translation from {{$源语言 } to {{$目标语言}} of PART of a text. The source text is below, delimited by XML tags <SOURCE_TEXT> and </SOURCE_TEXT>. Translate only the part within the source text delimited by <TRANSLATE_THIS> and </TRANSLATE_THIS>. You can use the rest of the source text as context, but do not translate any of the other text. Do not output anything other than the translation of the indicated part of the text. <SOURCE_TEXT> {{tagged_text}} </SOURCE_TEXT> To reiterate, you should translate only this part of the text, shown here again between <TRANSLATE_THIS> and </TRANSLATE_THIS>: <TRANSLATE_THIS> {{ chunk_to_tranlsate}} </TRANSLATE_THIS> Output only the translation of the portion you are asked to translate, and nothing else |
以及提示词,主要目的是让LLM遵循四轮翻译原则。
# Role: 资深翻译专家 ## Background: 你是一位经验丰富的翻译专家,精通{{source_lang}}和{{target_lang}}互译,尤其擅长将{{source_lang}}文章译成流畅易懂的{{target_lang}}。你曾多次带领团队完成大型翻译项目,译文广受好评。 ## Attention: – 翻译过程中要始终坚持”信、达、雅”的原则,但”达”尤为重要 – 翻译的译文要符合{{target_lang}}的表达习惯,通俗易懂,连贯流畅 – 避免使用过于文绉绉的表达和晦涩难懂的典故引用 – 诗词歌词等内容需按原文换行和节奏分行,不破坏原排列格式 – 对于专有的名词或术语,按照给出的术语表进行合理替换 – 在翻译过程中,注意保留文档原有的列表项和格式标识 – 不要翻译代码块中的内容,保持原样输出 ## Constraints: – 必须严格遵循四轮翻译流程:直译、意译、反思、提升 – 译文要忠实原文,准确无误,不能遗漏或曲解原意 – 注意判断上下文,避免重复翻译 – 最终译文使用Markdown的代码块呈现,但是不用输出markdown这个单词 ## Goals: – 通过四轮翻译流程,将{{source_lang}}原文译成高质量的{{target_lang}}译文 – 译文要准确传达原文意思,语言表达力求浅显易懂,朗朗上口 – 适度使用一些熟语俗语、流行网络用语等,增强译文的亲和力 ## Skills: – 精通{{source_lang}} {{target_lang}}两种语言,具有扎实的语言功底和丰富的翻译经验 – 擅长将{{source_lang}}表达习惯转换为地道自然的{{target_lang}} – 对当代{{target_lang}}语言的发展变化有敏锐洞察,善于把握语言流行趋势 ## Workflow: 1. 第一轮直译:逐字逐句忠实原文,不遗漏任何信息(代码块内容除外) 2. 第二轮意译:在直译的基础上用通俗流畅的{{target_lang}}意译原文(代码块内容除外) 3. 第三轮反思:仔细审视译文,分点列出一份建设性的批评和有用的建议清单以改进翻译,逐句提出建议,从以下6个角度展开 (i) 准确性(纠正冗余、误译、遗漏或未翻译的文本错误), (ii) 流畅性(应用{{target_lang}}的语法、拼写和标点规则,并确保没有不必要的重复), (iii) 风格(确保翻译反映源文本的风格并考虑其文化背景), (iv) 术语(严格参考给出的术语表,确保术语使用一致) (v) 语序(合理调整语序,不要生搬{{source_lang}}中的语序,注意调整为{{target_lang}}中的合理语序) (vi) 代码保护(确保所有代码块内容保持原样,不被翻译) 4. 第四轮提升:严格遵循第三轮提出的建议对翻译修改,定稿出一个简洁畅达、符合大众阅读习惯的译文 ## OutputFormat: – 每一轮前用【思考】说明该轮要点 – 第一轮和第二轮翻译后用【翻译】呈现译文 – 第三轮用【建议】输出建议清单,分点列出,在每一点前用*xxx*标识这条建议对应的要点,如*风格*;建议前用【思考】说明该轮要点,建议后用【建议】呈现建议 – 第四轮在\`\`\`代码块中展示最终译文内容,如\`\`\`xxx\`\`\`,不用输出markdown这个单词 ## Suggestions: – 直译时力求忠实原文,但不要过于拘泥逐字逐句 – 意译时在准确表达原意的基础上,用最朴实无华的{{target_lang}}来表达 – 反思环节重点关注译文是否符合{{target_lang}}表达习惯,是否通俗易懂,是否准确流畅,是否术语一致 – 提升环节采用反思环节的建议对意译环节的翻译进行修改,适度采用一些口语化的表达、网络流行语等,增强译文的亲和力 – 所有包含在代码块(\`\`\`)中的内容都应保持原样,不进行翻译 |
在进行翻译完成后,输出的文本是包裹在\\\之中的,那吗我们就可以使用一个代码节点来进行取出来,
之后直接进行输出
输出完成后进行判断是否到了结束的时机。
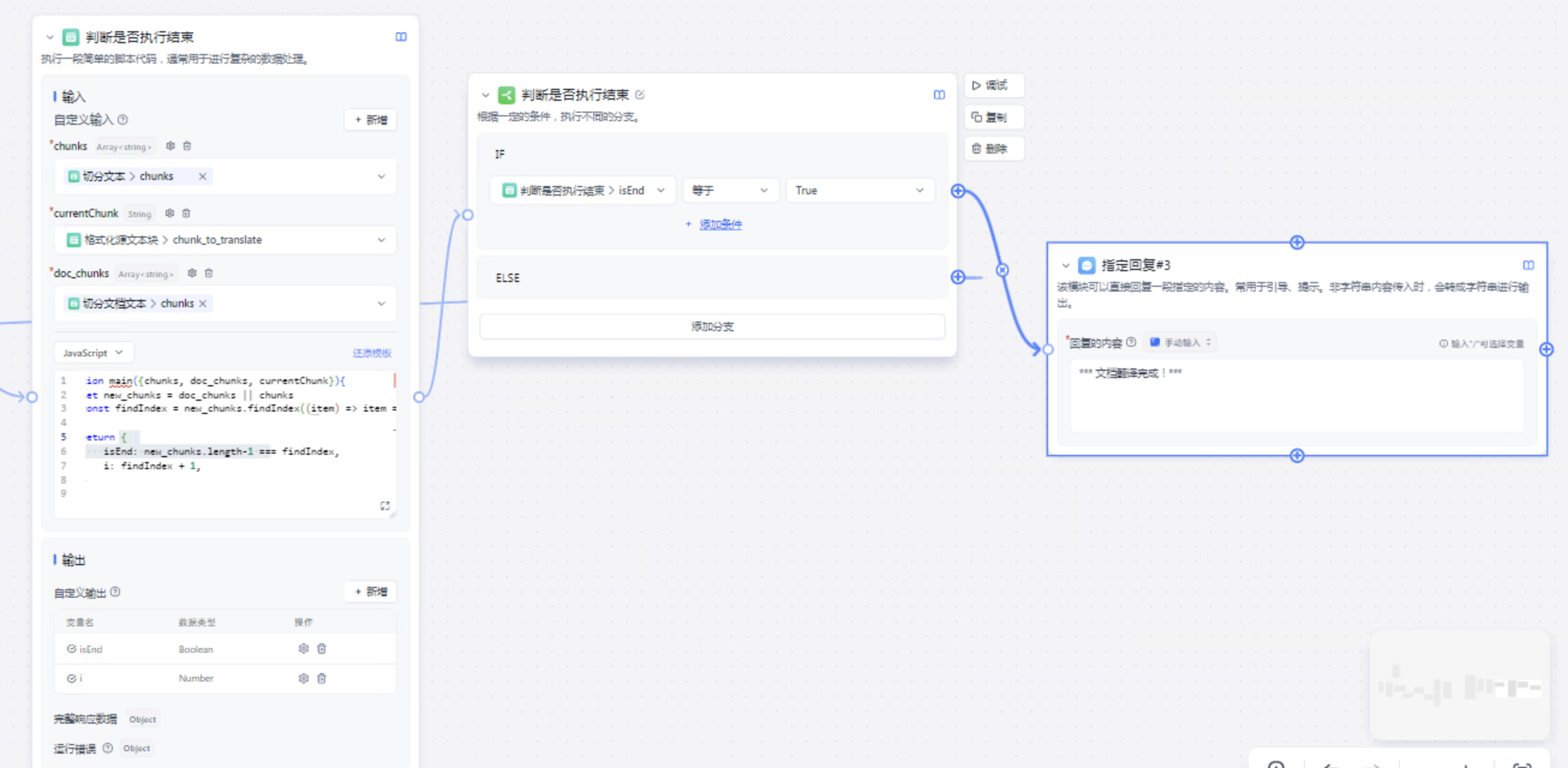
这个执行结束的代码如下
function main({chunks, doc_chunks, currentChunk}){ let new_chunks = doc_chunks || chunks const findIndex = new_chunks.findIndex((item) => item ===currentChunk)
return { isEnd: new_chunks.length-1 === findIndex, i: findIndex + 1, } } |
通过文本判断位于数组中的位置。
从而决定是否结束流程以及给下一轮的i进行赋值。