本章,我们讨论下分布式计算的实现模型,如何将抽象的计算流图,转换为实实在在的分布式计算任务,并且以并行计算的方式进行交付执行。
在Spark种,任何一个程序的入口,都是带有SparkSession的main函数,其包罗万物。提供Spark运行时上下文的同时,为开发者提创建,转换,计算 分布式数据集的开发API
对于这样的一个main函数,称之为Drvier
Driver就负责将代码进行解析,构建计算流图,然后交付进行运行,也就是类似主脑的地位,实际负责运行的,在Spark环境中,被称为Executor
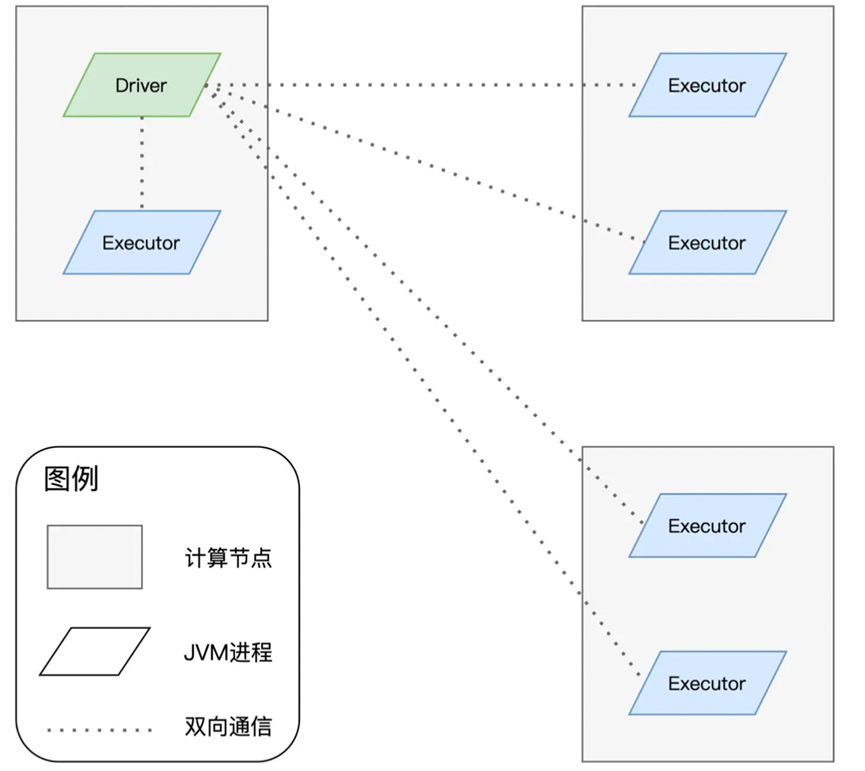
大致是这样的一个架构
而在Driver进程之中,DAGScheduler,TaskScheduler,SchedulerBackend三个对象进行通力合作。
将用户的代码转换为计算流图
根据计算流图拆分出分布式任务
然后将分布式任务分发到Executors中
接收到任务之后,Executors调用内部的线程池,执行任务代码,对于一个完整的RDD,每个Executors负责处理其中的一个数据分片子集,进行处理
之后,我们拿上面的CountWord作为例子,看下如何形成的执行过程
首先我们在执行的时候,需要先进入spark-shell交互式环境
Spark-shell有很多命令行参数,其中最为重要的有两类,一类是指定部署master,一类指定任务所需的资源。
然后默认的进入模式,指定master部署模式为local,第二个是部署规模,默认是按照CPU个数启动的,假设有4个CPU,敲入spark-shell的时候,会启动1个Driver进程,3个Executors进程。
然后我们输入了不同的计算原语,直到输入take这个Action算子的时候,会触发之前构建好的计算流图。划分不同的任务,分发给不同的Executors
那么,如何划分不同的任务呢? 是根据的Shuffle任务为边界进行的划分
也就是洗牌任务,这种任务,对应到我们之前的Count Word任务中,就是reduceByKey算子,就比如一个单词spark,在之前可能散落在不同的Executor中,我们需要将不同的Executor进程中的单词,汇总到一个Executor中,这就是Shuffle
那么根据CountWord的代码,大致可以分为两个部分,一部分是textFile,flatMap,filter,map
组合成一份任务,然后另一份是reduceByKey,确定了这两个任务之后,我们就可以将其发给对应的Executors进行执行,整体的流程参考如下
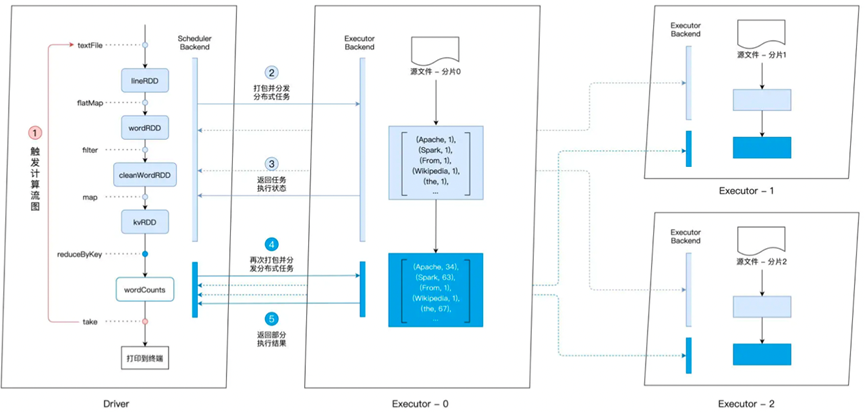
这样,我们就在本地部署的环境中进行了运行,不过一般的Spark代码运行,都是依赖于集群环境,而不是一个单机环境,而Spark集群支持运行在Standalone,YARN,Mesos,Kubernetes。
这里我们也简单说下如何进行Standalone模式下的Spark集群搭建。
首先准备三个机器,并配置对应的SSH互联

然后安装spark
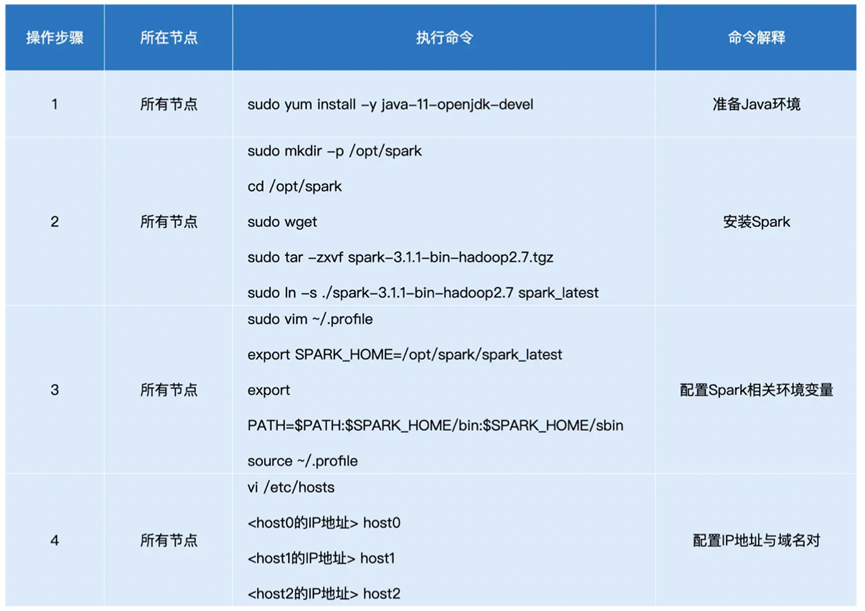
之后启动Master和Worker节点

这样就启动了一个Standalone的集群运行Spark任务了。
之后我们更加详细的讲述下分布式计算中的整体架构
//插入昨晚写的
首先是核心组件DAGScheduler
负责将形成的计算图DAG拆分为执行Stages,并且将每一个Stage转换为TaskSets,
而在TaskSets中,包含了多个Task,也就是多个分布式任务,每一个Task中包含的属性主要如下

上面的属性中,stageId和stageAttempld标记了Task和Stage的对应关系
TaskBinary封装了用户代码,partition则是对应的RDD数据分区,locs则是用于计算任务倾向的计算节点。
那么关于一些Task的细节我们最后再说,先来总结下DAGScheduler的主要职责
首先根据用户代码构建DAG
然后以Shuffle 为边界进行Stages的切割
基于Stages创建TaskSets,并且将TaskSets交为TaskScheduler进行调度
那么DAGScheduler讲完了
我们就可以看看TaskScheduler的功能了,不过TaskScheduler在获取到了TaskSets之后,需要先去找SchedulerBackend获取执行资源
我们就先看下SchedulerBackend这个组件的功能
其内部维护了个名为ExecutorDataMap的数据机构,以Executor节点为Key,保存了每个节点的资源状态。其中包含了Executor的RPC地址,主机地址,可用CPU核数和CPU总数。
这样,在TaskScheduler请求资源的都是,就可以返回给TaskScheduler多个WorkOffer了,其中每个WorkOffer都封装了ExecutorID, 主机地址,CPU核数方便TaskScheduler用于任务调度
至于SchedulerBackend如何维护这个ExecutorDataMap,则是通过了ExecutorBackend保持周期性通信,ExecutorBackend存在于每一个节点上,来进行消息的互通有无,记录资源变更
然后我们回到TaskScheduler,在获取到多个WorkerOffer之后,TaskScheduler会将Task分配到不同的节点上
那么如何进行分配的,则是根据每一个Task中存在的locs字段,也就是倾向性来决定的。
由于 移动数据不如移动计算的概念,所以locs中保存了本地倾向性来进行调度
比如我们数据存放在node0,node1节点,那么我们在设置读取Task的时候更倾向于放在node0,node1节点上,这种节点倾向称为 NODE_LOCAL
除了这种节点调度,还有着PROCESS_LOCAL、RACK_LOCAL 和 ANY。
上面的调度规则的优先级则是 PROCESS_LOCAL > NODE_LOCAL > RACK_LOCAL > ANY
按照优先级进行调度,确认分配节点
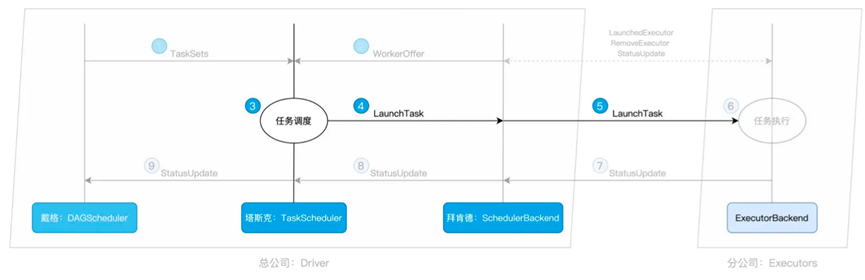
确认节点后,发往对应节点上的ExecutorBackend进行执行。
而Executor Backend除了负责协助SchedulerBackend来维护各个节点的资源状态
还负责实际的执行操作,负责实际执行-Task
每当Task处理完成,ExecutorBackend还会向SchedulerBackend 发送StatusUpdate事件,告知Task的执行状态,最终将状态汇报给DAGScheduler
从而让DAGScheduler知道自己完成了某一个Stage的任务调度。
而在DAGScheduler中,因为存在两种Stage,ResultStage和ShuffleMapStage
ExecutorBackend上报的状态更新到了TaskScheduler,其会放在LinkedBlockingDequeu队列中,让DAGScheduler进行消费,
DAGScheduler会标记这个Task对应的Executor完成,然后检查对应的Stage是否还有没处理的Task,如果没有则说明Stage完成,继续等待后续Stage完成。