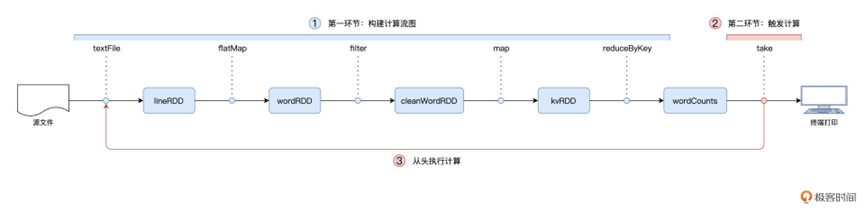
第一章的时候,我们有使用到map,filter,flatMap,reduceByKey这些算子,而在Spark整体中,包含了很多算子,可以作用于函数的转换,最常见的,也就是上面说的这几个算子,主要都是用于数据形态上的转换
这一类用于转换的算子,都简称为Transformations类算子,除了这一类算子,还有Actions类算子,负责将计算结果进行输出
因为存在这两种算子,所以整体计算可以分为两个环节
基于转换算子,构建计算流图 DAG
通过Actions类算子,以回溯的方式触发这个计算流图
这样的架构,在业内有一种专门的术语,叫做延迟计算
这也就是为什么Word Count在执行的过程中,只有最后一行代码会花费时间
因为会先构成图再计算,也正因为这种架构,保证了其优化
最后我们给出了比较完整的RDD算子集合,聚合为了下图
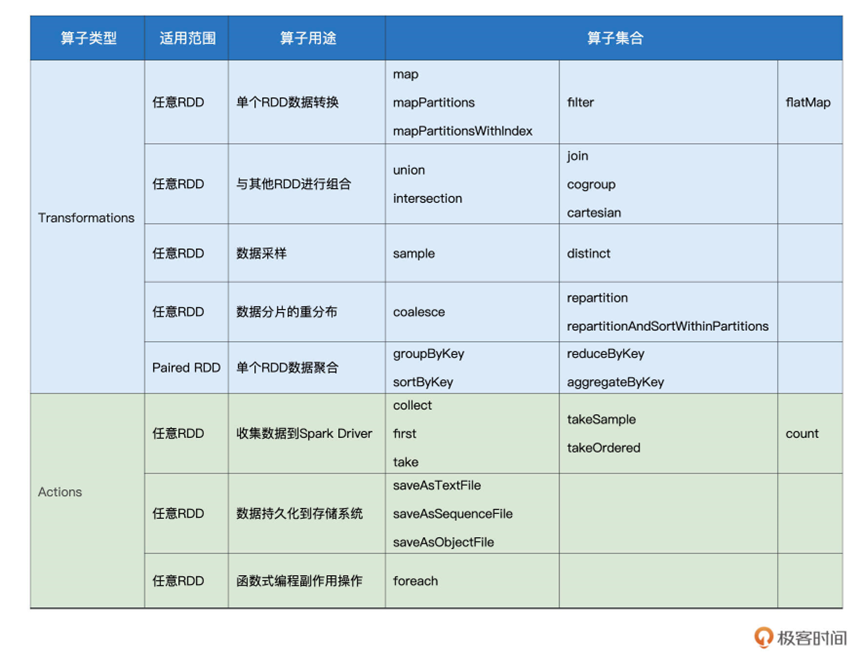
那么除了这个之外,我们还可以看看map,mapPartitions,flatMap,filter 几个算子的用法。
不过在讲之前,需要看下创建RDD的典型方式
我们可以在执行过程中,在内部数据之上创建RDD
也可以通过读取外部数据创建RDD
通过内部数据创建的方式如下,只需要parallelize函数即可
import org.apache.spark.rdd.RDD
val words: Array[String] = Array(“Spark”, “is”, “cool”)
val rdd: RDD[String] = sc.parallelize(words)
通过外部数据创建的方式如下
我们可以通过SparkContext.textFile的方式从外部数据创建RDD,由于textFile API 比较简单。我们就使用这个
import org.apache.spark.rdd.RDD
val rootPath: String = _
val file: String = s”${rootPath}/wikiOfSpark.txt”
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
那么说完了基本的创建,我们看下RDD内的数据转换
比如map,以元素为粒度的数据转换
Map算子支持匿名函数或者声明函数两种方式
如果是声明函数,可以参考如下
// 把RDD元素转换为(Key,Value)的形式
// 定义映射函数f
def f(word: String): (String, Int) = {
return (word, 1)
}
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(f)
我们定义了def函数,然后将函数传递给了map算子
但是由于map函数有着一次处理一个的问题,对于某些需要在函数内初始化对象的代码,就不太友好,因此引入了mapPartitions,支持一次性处理一批数据,比如如下代码
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {
// 注意!这里是以数据分区为粒度,获取MD5对象实例
val md5 = MessageDigest.getInstance(“MD5″)
val newPartition = partition.map( word => {
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
(md5.digest(word.getBytes()).mkString,1)
})
newPartition
})
这样我们就可以共享某些对象在map处理过程中
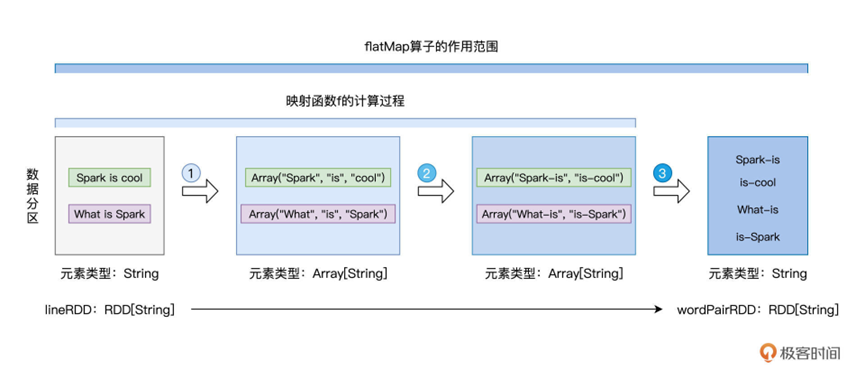
之后就是一个更为好玩的转换类型函数,flatMap
支持进行转换,并输出0到多个结果
我们来看一段代码
// 读取文件内容
val lineRDD: RDD[String] = _ // 请参考第一讲获取完整代码
// 以行为单位提取相邻单词
val wordPairRDD: RDD[String] = lineRDD.flatMap( line => {
// 将行转换为单词数组
val words: Array[String] = line.split(” “)
// 将单个单词数组,转换为相邻单词数组
for (i <- 0 until words.length – 1) yield words(i) + “-” + words(i+1)
})
我们直接输出了一个Array数组包含了多个字符串,但是我们得到的RDD其中包含的直接是String,这就是flatMap,将结果进行了展平处理。
最后我们说下和map一样常见的算子,filter 用于对RDD进行过滤,filter函数需要返回一个Boolean 类型的结果,根据这个结果从而确定保留哪些元素,比如如下代码,我们过滤其中包含特殊字符
// 定义特殊字符列表
val list: List[String] = List(“&”, “|”, “#”, “^”, “@”)
// 定义判定函数f
def f(s: String): Boolean = {
val words: Array[String] = s.split(“-“)
val b1: Boolean = list.contains(words(0))
val b2: Boolean = list.contains(words(1))
return !b1 && !b2 // 返回不在特殊字符列表中的词汇对
}
// 使用filter(f)对RDD进行过滤
val cleanedPairRDD: RDD[String] = wordPairRDD.filter(f)