我们这一次看Spark的内存管理
在Spark中,可以把内存分为四个部分,分别是Reserved Memory, User Memory, Execution Memoryh和Storage Memory
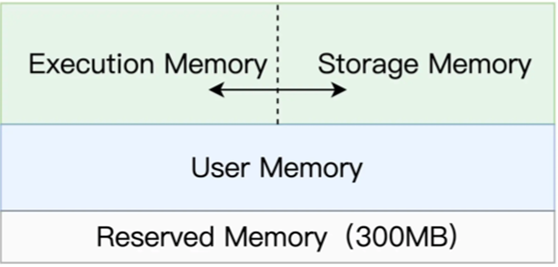
其中Reserved Memory大小固定是300MB,不受开发者控制,是Spark预留的,用于存储各种内部对象的内存区域
User Memory用于存储开发者自定义的数据结构,比如引用的数组,列表,映射等
上面的Execution Memory用于计算过程中的消耗谁用
Storage Memory用于缓存数据集,广播变量等,从而供计算使用
其中在执行过程中最为重要的,就是User Memory和 Storage Memory
而在Spark中,这两个区域是可以互相转换的,这里我们拿一个简单的示例距离
比如我们有一个加工厂,加工厂有施工区域和暂存区域
暂存区域负责存储物料,施工区域负责对物料进行各种加工处理
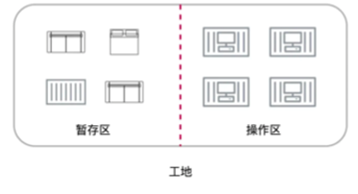
两个区域相接,中间有虚线相隔
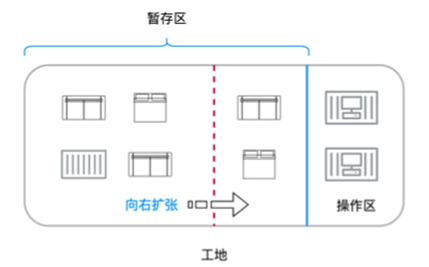
在此过程中,如果操作区只有两个工人,而暂存区很缺地方的话,那么就可以把操作区的一部分暂时割让给暂存区
其次,如果我们有多个工人,而暂存区的物料比较少的,那么可以向左扩张,也就是操作区临时占用暂存区
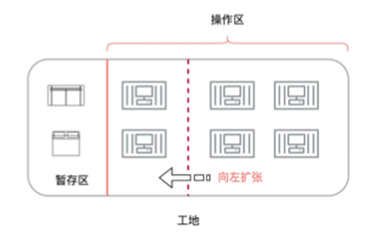
而对应到Spark中,操作区就类比Execution Memory,暂存区就类比Storage Memory
而两者的抢占规则可以总结为
如果对方还有空闲空间,可以彼此利用
其次如果Storage Memeory使用了Execution Memory,而有计算的需要的时候,Storage Memory需要立刻归还抢占的内存,使用的内存可以进行落盘等操作
对于Execution Memory抢占的Storage Memory,那么即使Storage Memory 有收回的需要,也需要等到分布式任务执行完成才能使用
那么其次,我们可以说下在Spark中相关的内存配置项
主要有三个部分
spark.executor.memory是指定JVM Heap总大小,包含了Execution Memory和Storage Memory以及User Memory三个部分,然后是 spark.memory.fraction标记Execution Memory和Storage Memory两部分占总量的百分比
最后是spark.memory.storageFraction来区分Execution Memory和Storage Memory两个部分比例
最后我们聊下RDD中如何进行缓存
也就是对同一个RDD,如何加块读取
我们可以在对应的RDD之上,依次调用cache和count即可,可以参考如下的代码
wordCounts.cache
wordCounts.count
这样就会进行缓存了
之所以调用两个函数,是因为cache函数并不会立刻出发RDD在内存中的物化,还需要调用count算子来触发这一执行过程
除了cache原语外,还可以使用persist来进行物化,基本代码使用如下
wordCounts.persist(MEMORY_ONLY)
其中可以指定缓存介质和缓存形式,以及副本数量
缓存介质可以指定为硬盘或者内存等
存储形式可以指定是对象值或者是序列化存储
副本数量可以指定拷贝数量,不指定则默认为1
更加具体的存储级别可以参考下表
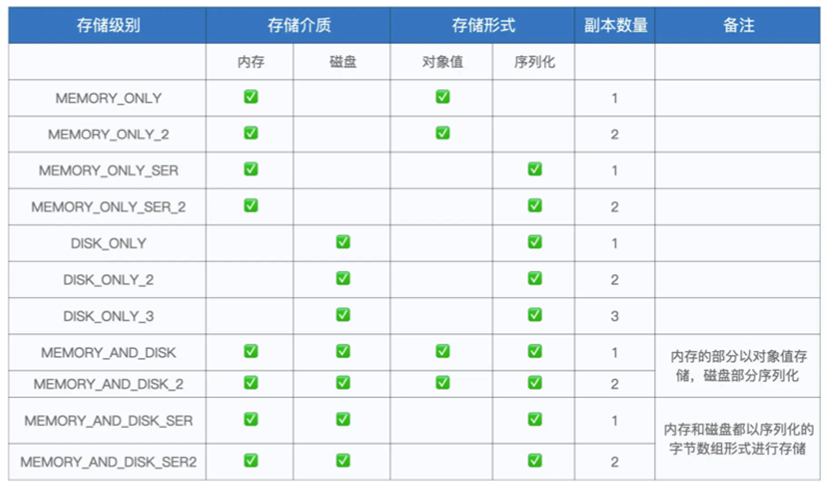
基本可以满足各类需求了
那么总结下本章,我们首先讲解了Spark的不同的内存区域
其次说明了内存相关配置项
最后说了RDD Cache的基本用法