1.对于Producer,我们需要明确消息会被指定到topic的哪个分区中,Producer提供了默认的分区器,其会通过hash算法将key映射到相同的partition,如果没有指定key,那么就会利用轮询的方式来确保topic在所有的分区上均匀的分配.
但是我们可以自定义分区机制,通过实现一个自定义的分区器即可.
创建一个自定义的分区器,只需要实现对应的Partitioner即可,
这个接口的入参具有topic,key,keyBytes,value,valueBytes,cluster
我们接下来创建一个具有特定规则的分区器.
我们假设有些key会携带字符串audit,如果遇到这些消息,就将他们发送到topic的最后一个分区,对于其他的消息,则还是使用随机的方式来发送到不同的分区上.
基本代码如下

![]()
其中我们获取了topic对应了Cluster的信息,然后根据key中的包含,来返回对应的partition数字.
那么我们创建了一个自定义的分区策略,对应的使用方式如下
props.put(“partitioner.class”,”com.xxx.yyy.producer.MyPartitioner”)
这样我们就自定义了一个消息分区策略.
2.消息序列化
则是kafka为了实现将消息以字节的方式进行发送,而提供的功能,分为了key序列化器和value序列化器.而对应的consumer中包含key解码器和value解码器.
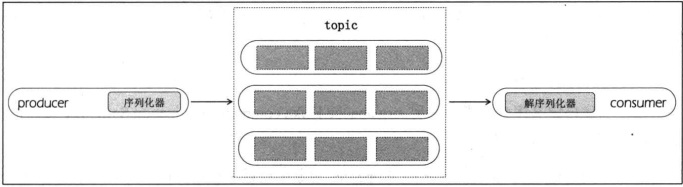
而Kafka提供了十几种序列器,常见的如下
ByteArraySerializer,什么都不做
ByteBufferSerializer,序列化ByteBuffer
BytesSerializer,序列化Kafka自定义的Bytes
StringSerializer 序列化String类型
使用也很简单,只需要在配置中指定就可以了.
如果需要 自定义实现一个序列器,只需要编写一个自定义的Serializer
这需要实现Serializer接口.
其中的入参无非就是 topic,data, 并要求返回一个byte数组.
3.Producer拦截器
用于在消息发送前对整个消息进行一个定制化处理,并且可以指定多个intercetpor形成一个拦截器链.对应的实现接口是ProducerIntercetpor
其中方法有
onSend 在计算分区调用这个方法,用于修改消息,最好不要修改消息所属的topic和分区
onAcknowledgement 消息被应答之前或者消息发送失败时候调用,因为运行在producerIO发送线程,不要在其中放入很重的逻辑,不然拖慢producer消息发送效率.
close,执行一些资源清理工作.
我们实现一个拦截器

然后在interceptor之后,在producer主程序中指定.
![]()
![]()
从而进行拦截器链的使用.
接下来我们说下一个如何配置一个不会丢失数据的Kafka集群.
这需要我们分别配置broker端和producer端.
我们分别说两端的配置,首先是producer端
acks = all 需要等待所有follower都响应了消息之后才认为提交成功
retries = 一个较大值,给与一个较大值,来进行多次重试
max.in.flight.requests.per.connection = 1
限制一个broker上能够发送的未响应的数量,甚至为1,保证在某个broker发送响应后无法再给broker发送producer请求.
确定使用带有回调的send
如果失败之后在callback中立刻关闭producer
对于broker端配置
首先是关闭非ISR中的副本来选举为leader.
relication.factor 设置多份,来保存分区的消息
min.insync.replicas 大于1 ,设置大于1是提高可用性
最后设置replication.factor > min.insync.replicas
因为两者相等,那么只要有一个副本挂掉,那么分区就无法正常工作,为了保证可用性,所以建议如上设置.
对于消息压缩
则是一种通过提高CPU使用率来降低磁盘使用率和带宽使用率,
而且在broker端,并不会对消息进行解压缩,那么就是producer压缩,broker端保持,consumer端解压缩.
对于不同的压缩算法的选择建议是查看Kafka的官网,来进行压缩算法的选择.
最后对于实际项目中,Producer的使用,基本分为了多线程单实例使用,多线程多实例使用.
对于单实例,顾名思义,就是一个Producer订阅多个topic,然后交给多个线程来使用.
多实例则更为简单,就是每个线程构建自己的producer实例,来保证可用.
而对两种的对比
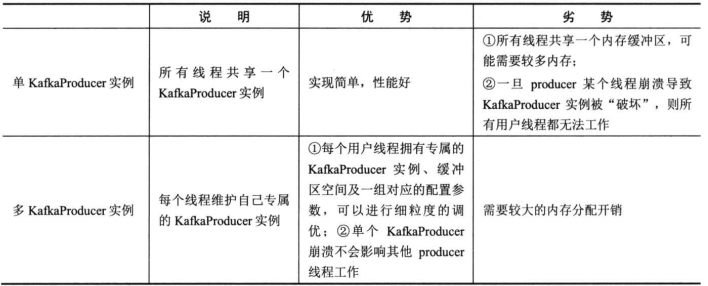
基本上,如果分区数量不多,那么推荐使用第一种
如果拥有很多的分区数量,推荐使用二种方式.
根据上面所讲,基本可以阐述Producer在项目中的基本使用.