本次我们说Kafka的Consumer
毕竟在整个Kafka中,必然还有些外部消费者consumer负责读取producer发送的消息
那么我们就需要针对Kafka来看其整体设计,及相关API
对于consumer,基本可以分为老版本和新版本,在老版本之中,用户可以不使用消费者组,而直接使用一个单独的消费者进行消费,不过代表着也需要自行处理错误和故障转移,而新版本则必须要使用消费者组,并根据此来减少用户的额外开发
那么从上面看,新老版本的区别集中在于是否存在消费者组,consumer group
而consumer group这个概念,在kafka官网上给出了定义,
![]()
翻译过来就是,消费者使用一个消费者组名来标记自己,topic确保每个消息都会被发送到每个订阅他的消费者组的一个消费者实例上。
上面说明了,一个topic的消息会发送给所有订阅的消费者组,消费者组可能有多个消费者。
而我们之前也讲过,kafka支持两种消费范型,分别是队列消费和发布订阅
对于队列消费,很简单,所有订阅这个topic的consumer都放在一个group中
对于发布订阅则是consumer实例分属不同的group
而引入consumer group 不仅实现了两种消费范型,而且支持了高可用的consumer机制,在其中一旦有consumer挂了,就会将崩溃的consumer分区交给其他的consumer来处理,这个过程被称为重平衡(rebalance)。
再说完了consumer group之后,需要指出,consumer中还有其他比较重要的概念,比如位移
Offset,这个offset指的是consumer的消费位移,要和partition中记录的位移区分开来。
而这个位移信息并不是直接保存在了broker上,而是简单的在consumer group上保存offset,在consumer内部利用一个map来保存其订阅的topic信息
![]()
但是这个唯一并不会一直保存在consumer group,需要定期的kafka集群同步,这个同步过程被称为offset commit,在位移提交过程中,kakfa将group对应的位移信息放在了集群内部的一个topic(__counsumer_offsets)上
对于这个topic,不建议用户进行任何的删除操作,内部就是一个简单的topic文件,不过里面存储的都是kafka的位移信息罢了
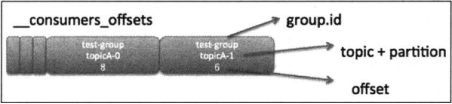
这个key value中,key是一个三元组,存储的group.id topic 分区号,value存储的是offset
而且kafka会定期的对topic进行压实的操作,只保存最新offset的消息
如果一个kafka中有很多的consumer或者consumer group,那么这些consumer如果并发高了,topic也受不了。因此创建了50个分区,并对每个group.id进行哈希取模运算,分配到不同的分区。
最后是重平衡,因为一个consumer group下的所有consumer需要达成一致来进行分配topic的所有分区,假设我们有一个consumer group,里面有20个实例,每个consumer预计会被分配5个分区。整个分配流程就被称为rebalance。
然后对于consumer的基本使用。
对于consumer这个对象的使用,基本上也是创建一个properties,然后填充对应的参数
利用prop对象创建一个consumer,
然后利用subscribe来订阅感兴趣的topic列表
利用consumer.poll来获取topic下的消息
处理获取到的consumerRecordd对象
最后关闭consumer对象。
那么更多的细节如下
首先是构造Properties对象,需要几个指定的参数,分别是
Bootstrap.servers
和java版本的producer相同,必须要指定,用于和broker链接,只需要制定部分broker即可,consumer会通过部分的broker找到全部的broker列表。
Group.id
标识一个consumer group,虽然官网上说有默认值,但是如果不写还是会爆出一个InvalidGroupIdException异常,一般是一个和业务有关的名字即可
Key.deserializer
对其中的key进行解码,一般来说最好和producer端的serializer进行呼应
Value.deserializer
对value进行解码,跟上面一样,和producer端的serializer进行呼应即可。
对于构造一个Consumer对象
只需要传入properties对象即可。
订阅topic队列
需要调用consumer的subscribe函数,传入一个topic数组即可
与之相对的还支持正则表达式,如果要订阅所有以kafka开头的topic,所以如此订阅
![]()
在这个方法中,我们传入了第二个参数,一个ConsumerRebalanceListner,用于进行rebalance
还有一个问题,对于订阅,后续的订阅会覆盖之前的订阅
获取消息
Consumer的关键方法,用于从订阅的topic获取信息,采用了类似selector IO机制,利用一个线程完成所有类型的IO操作
其中consumer.poll(Integer) 中的参数是一个超时时间,如果拿到了足够多的可用数据,会立刻返回,如果没有这么多,就进行阻塞,直到达到阻塞的最大时间。
处理ConsumerRecord
上一步返回了Kafka的消息,拿到这些消息后consumer需要进行逻辑处理,那么需要注意一点,到底哪一步算作consumer的消费成功了呢?是调用poll还是处理consumerRecord呢?
从kafka的角度来说,其实poll方法返回了就认为consumer成功消费了消息
最后关闭consumer
这个关闭是需要执行的,同样可以指定等待时间,如果不设置就最多等待30s
之后我们按照和producer一致的思路,讲解一下consumer在配置中的主要参数。
Session.timeout.ms
用于判断一个consumer gorup中成员是否崩溃了,如果设置为5分钟,那么当某个group成员崩溃了,那么就需要等待5分钟才可以感知到错误,还有些可以与之搭配的参数,比如下面的max.poll.interval.ms
这个是指的用户设置消息处理逻辑的最大时间,假设需要落地到远程数据库,一个平均处理时间是2分钟,那么就需要将这个值设置为大于2分钟的值即可
Auto.offset.reset
用于进行一个消费者组无位移信息或者位移越界的时候kafka的应对策略,可以设置3个可取的值
Earliest,从最早的位移开始消费
Latest, 最新处开始消费
None, 抛出异常,实际上基本不会设置为这个参数
Enable.auto.commit
Consumer是否自动提交位移,设置为true,则会自动提交,对于精准处理一次,最好将其设置为false,用户自行处理位移问题
Fetch.max.bytes
指定了consumer单次获取数据的最大字节数,消息很大,就需要设置一个较大的值。
Max.poll.records
Poll返回的最大消息数,默认是500条消息
Heartbeat.interval.ms
这一个是用于consumer group之间的通信,确定什么时间进行rebalance
需要注意,这个值需要小于session.timeout.ms
Connections.max.idle.ms
这是用于定期的关闭Socket链接,默认是9分钟,如果不希望关闭Socket,可以设置参数为-1,不关闭这些空闲连接。
订阅topic
对于基础的订阅,只需要订阅consumer中对应的api,
Consumer.subscribe(Arrays.asList(“topic1”))
需要注意一点,订阅信息只有下一次poll的时候才会生效,如果poll之前就尝试获取订阅信息,获取的也是空的
除此外,还有可以使用正则表达式来订阅topic
Consumer.subscribe(Pattern.compile(“service-*”),new ConsumerRebalanceListencer())
如果需要使用正则表达式,那么需要实现一个ConsumerRebalancerListener借口,来进行consumer重新变更分区的时候提交逻辑。
如果希望consumer订阅某些固定的分区,那么可以使用独立consumer,利用assign来接收一个分区列表,赋予这些consumer来访问这些分区的权利,同时这些consumer就不再需要consumer group了,基本使用如下,


消息消费,消息消费离不开poll
那么我们需要了解下poll的相关原理,其在新版的consumer中,改为了两个线程进行消费,一个是主线程,利用类似Linux中select的操作,进行管理和多个Socket的链接。
而且主线程中的selector还管理了包括coordinator的协调等操作。
而poll的使用方式也很简单,我们也会讲解consumer poll的操作范式。
基本的使用方式如下

对于上面polll中的参数,适用于控制consumer等待消息的最大阻塞时间,而poll的返回时机,是满足任何一个条件就可以
要么就是获取到了足够多的消息。
要么就是等待时间超过了指定的超时设置。
其次就是对于consumer来说,不建议多个线程持有一个实例,如果多个线程持有相同的实例,会在poll的时候抛出KafkaConsumer is not safe for multi-threaded access异常,所以不建议多线程共用一个Consumer实例,
然后在consumer使用完成之后,最好是显式的调用close方法,来关闭Socket链接,并通知coordinator主动离组来快速的开启一轮rebalancer
如果我们希望在拉取消息的时候,同时定时记录日志,就可以利用poll加时间
不然可以考虑consumer.poll()
consumer的位移管理
consumer端可能会订阅多个分区,那么分区中会包含最新消费的位置,就被称为offset,consumer会定期的向Kafka提交自己的位置信息,而提交的位移,就是下一条待消费的消息位置,假设已经读取了N条消息,那么提交的位移值就是N,因为位移是从0开始的,位移为N的消息为第N+1条消息。
而且offset就是实现Kafka不同处理语义的基石,比如
最多一次,最少一次,精确一次
如果在消息消费之前就提交了位移,那么可以实现at most once,如果消息消费之后提交,会实现 at least once,而引入事务,可以配合位移实现exactly once。
具体的consumer位置信息,可以归纳如下

其中,上次位移,是consumer最近一次提交的offset
当前位置,是指的consumer已经读取,但是尚未提交的位置
水位,不属于consumer管理的范围,而是分区日志的概念,对于水位之下的消息,是可以读取的,水位之上的,则是无法读取的。
日志终端位移,是保存了当前日志中保存的消息的最大值,一般来说,不会比水位值小,事实上,只有所有的分区都保存了一条消息,才会将水位值上移。
而在consumer中,因为所有consumer都会加入一个consumer group,而consumer group中会指定一个broker作为coordinator,负责和kafka负责保存位移的topic进行沟通,保存最新的位移,
当consumer运行一段时间之后,需要提交自己的位移值,如果consumer崩溃或者被关闭,就交给其他的consumer,所以需要尽快的提交位移请求,具体流程为,consumer发送位移请求给coordinator,然后coordinator负责进行提交给kafka,提交的请求中key为group.id,topic,分区元祖,value为位移值,而且Kafka会通过压实来进行处理消息,避免文件占用过大。
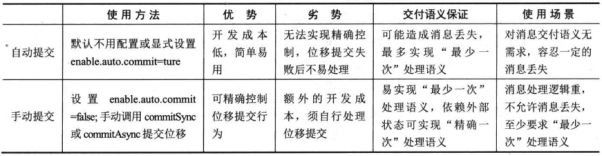
而consumer的位移提交,分为了手动提交和自动提交
默认情况下是自动提交的,间隔是5秒,这个间隔可以通过设置auto.commit.interval.ms来控制。
手动提交则是交给用户自行确定消息什么时候处理完成并可以提交位移,可以在消息处理完成后在提交位移,而对于手动提交位移,首先需要设置enable.auto.commit=false,然后调用commitSync或者commitAsync即可,两者区别在于一个是异步非阻塞的,一个是同步调用,不过异步非阻塞和同步的都是在主线程进行的操作,在selector中发出去的,不过异步的则是在发起消息的时候不会阻塞罢了。
两者的区别基本可以列举如下
而且无论手动提交还是自动提交,有着入参版本,可以指定一个Map来显式告诉Kafka那些分区需要提交位移,使用的代码基本如下。

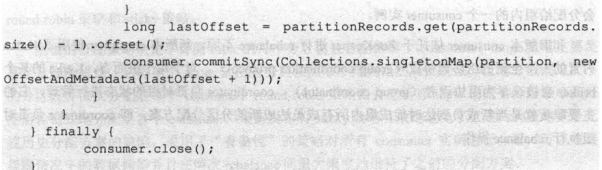
在上面代码中,我们获取到了每个分区下最后一条消息的偏移量,然后组成了一个OffsetAndMetadata对象进行提交。
而旧版本的consumer的位移提交,和新版本的使用基本一致,不过将位移相关信息保存在了Zookeeper中了。
Kafka的rebalance
Consumer中的rebalance本质上是一组协议,负责确定一个consumer group下的哪些consumer订阅那些topic下的哪些分区。而一个consumer group中,必然包含一个组协调者 coordinator,负责对组的状态进行管理,其主要职责就是当成员到达时候,协调进行重平衡操作。
而重平衡的触发时机有三个,
组的成员变更,新的consumer加入组,或者离开组
组的订阅topic数目发生变化变化,正则表达式方式的订阅,有新的topic创建的时候
订阅的topic分区数发生变化
最为常见的就是第一个条件,比如说,我们有一个非常重的处理逻辑,这样我们在处理的时候,可能因为超时导致不断的离开consumer group,而后又触发加入consumer group的操作。
Rebalance如何进行分区匹配的呢?基本有三种策略,分别是range策略,round-robin策略,sticky策略。
Range策略的分配主要是基于范围的思想,将单个topic按照顺序进行排列,然后按照固定大小分配给每个consumer,对于round-robin,则是将所有的topic的分区顺序摆开,轮训的分配给不同的consumer.而sticky则是进一步进行了优化,加入了黏性分配,维持了之前的分配策略。
而且在整个consumer过程中,我们会按照rebalance的次数,生成一个rebalance generation,用于确定是第几届的选举。
而与之相对的,在开发使用consumer过程中经常配到的ILLEGAL_GENERATION就是rebalance generation导致的,因为某些consumer提交offset,携带的信息是旧的generation信息。
而整个rebalance流程中,会被kafka划分几个协议来处理rebalance相关事宜。
JoinGroup 加入组
SyncGroup,进行分配方案的同步
Heartbeat,心跳请求,其中每个consumer是根据Heartbeat请求中是否包含REBALANCE_IN_PROCESS来确定是否开启了新一轮rebalance。
LeaveGroup,通知coordinator离组
DescribeGroup,查看组相关信息,是提供给管理员使用的。
而rebalance的整体流程如下
首先每个consumer确定coordinator所在的broker,并尝试建立连接,计算的算法基本如下,首先计算Math.abs(gourpID.hashCode)% offsets.topic.num.parition参数值
然后根据计算后的结果,来确定__consumer_offsets对应数字分区的leader所在broker,这个broker就是coordinator所在的broker。
其次就是往coordinator发出joinGroup请求,收集到全JoinGroup请求后,就会选择一个consumer担任group的leader,这个leader会收到coordinator发来的所有的成员信息,然后leader会制定分配方案。
同步更新分配方案,leader讲制定好的方案封装进SyncGroup,发给coordinator,其他的consumer也会发送一个SyncGroup请求,不过其中不包含方案。然后coordinator收到方案之后,将方案通过SyncGroup的response进行返回给每一个consumer。
Consumer group中,之所以让一个consumer作为leader进行分区管理,是方便具有更好的灵活性,可以做到根据机架来进行分配,做到一个机架上的分区数据可以被分配给同一个机架上的consumer,减少网络传输开销。
最后我们说一嘴rebalance的监听器,我们之前说过,如果希望将位移提交给外部的存储,那么需要使用rebalance监听器,使用rebalance监听器的前提是用户使用consumer group。
Rebalance监听器,主要是依靠 ConsumerRebalanceListener接口,里面有两个方法onPartitionRevoked和onPartitionAssigned。进行rebalace之前调用onPartitionsReoveked,完成rebalance之后调用onPartitionsAssigned。
比如我们实现了一个监听器,对于Revoked方法。

在rebalance之前进行保存offset.


在分区完成之后,利用seek来设置consumer分区的offset.
需要注意,上面的revoked和assign方法中不要存在一些阻塞方法。
Consumer解序列化
Consumer的解序列化是和producer的序列化相反的操作,kafka consumer从broker获取消息的格式是字节数组,consumer需要还原为对应的对象。Kafla提供的默认deserializer如下。

如果希望自定义一个deserializer,那么需要实现Deserializer接口
并且在配置中声明即可。
Props.put(“value.deserializer“,”xxx.xxx.xxx.UserDeserializer)
对于KafkaConsumer的使用,由于是非线程安全的,所以不希望多个线程公用一个实例,如果非要使用,也是希望接收数据和处理逻辑解耦。
我们按照两个方向,分别是多线程多实例的使用,和多线程单实例的使用来进行讲解。
对于多线程多实例,每个线程都创建属于自己的Consumer实例。
这样的创建使用是最为标准的方式,也是推荐的
对于单实例的使用,则是需要将消息获取和消息的处理解耦,将获取到的消息放入单独的线程池,基本如下图所示。
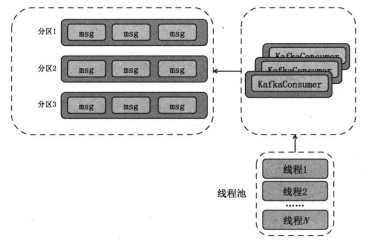
由全局的consumer获取消息 ,然后交给线程池中的worker线程进行处理,并由woker来记录位移状态。
我们来看一下代码,是如何处理记录这些位移信息的。
首先是创建一个consumer

主要的处理逻辑为


每次直接将数据封装为一个Runnable进行提交,然后直接提交offset
提交offset则是利用一个传递给runnable的map实现的,利用这个多线程共享的map来进行位移提交。
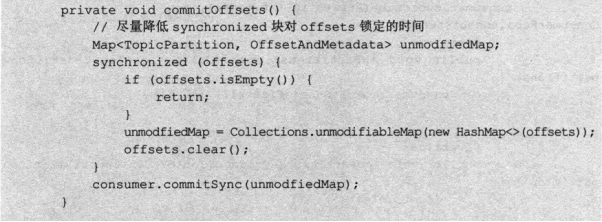
而这个map的数据放入,则是在runnable中
那么runnable基本如下:

在处理完成,讲消息位移放入map中
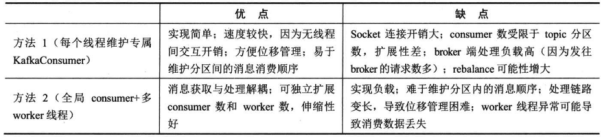
两种方法的对比如下
那么总结下本章,主要讲解了consumer的概要设计,consumer程序的开发,参数设置,consumer的各个子功能,比如rebalance,位移管理。