Kafka的Producer
对于Kafka而言,由于Producer和Consumer是交付给不同环境,不同语言的系统使用的,所以需要支持多语言版本,常见的有Python,Go,C++
而且Kafka还提供了一个独立的二进制通信协议,对外提供各种各样的服务,方便用户使用任何编程语言来自定义的和Kafka进行沟通。
Kafka的Producer比起Consumer而言,更加简单,不涉及任何复杂的组管理机制,每个Proudcer也是独立工作的,其主要的功能就是向某个topic的某个分区发送一条消息,那么就需要确定需要向哪个分区写入消息,于是Producer内部包含一个分区器,如果指定了key,就会根据key的哈希值来选择目标分区,如果没有指定key,就是用轮询的方式来确定目标分区,确保消息在所有分区上的均匀性。当然也支持用户手动指定目标分区,从而在消息发送的时候直接发送到目标分区。
同时producer也支持实现自定义的分区策略,而不是使用默认的partitioner。
确定了目标分区之后,接下来就是要寻找这个分区对应的leader,来通过和leader交互进行消息的发送。
更加详细的producer工作流程图如下。
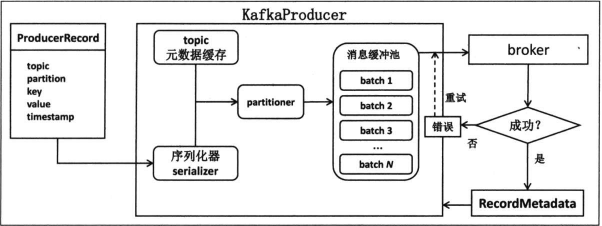
首先在用户主线程中,将消息封装进一个ProducerRecord类,然后将其序列化后发给paritioner,从而确定目标分区,确定完成目标分区后发送到一个内存缓冲区中,由另一个工作线程,即sender线程负责从这个缓冲区中提出消息封装进一个batch对象中,发送给不同的broker。
而一个Producer的使用流程基本分为构造Properties,通过Properties构造Producer,构造ProducerRecord发送,关闭Producer。
对于构造Properties,有三个属性是必要的,分别是bootstrap.servers 传入一组host:port,用于创建和Kafka broker服务器的链接,只需要传入集群中的部分broker即可,producer会通过这几个broker的链接,获取其他broker的信息。
Key.serializer,将message的key进行序列化的类,也是用户可以自定义实现的类
Value. Serializer, 将message的value进行序列化的类,也是用户可以自定义实现的类
其次是构造Producer
直接传入上面构造好的Properties即可,
![]()
然后是消息的承载体,ProducerRecord的构建
直接查看ProducerRecord的构造器方法即可,最少可以只传入topic和value.
然后就可以在用户的主线程中发送消息了,利用Java的Future,Kafka提供了同步和异步的两种发送方式。
默认是异步的,可以通过callback函数来判断消息的响应。通过在发送的时候传入一个callback匿名类,实现其中的onCompletion方法,来进行判断相应,onCompletion方法中具有metadata和exception两个入参,不会两个都是null,通过两个可以判断发送的情况。
如果是同步发送,是在send函数默认返回一个Future对象,可以利用Future.get来获取结果
如果get时候跑出了异常,就交给Producer进行处理。
而无论是在哪里获取到的异常,都可以分为两类,分别是可重试异常和不可重试异常,比如
LeaderNotAvailableExceptiion,分区的副本不可用,往往预示着选举中。
NotControllerException,当前controller不可用,表示着controller正在选举。
NetworkException 网络故障
上面都是可重试的异常,只要在规定的重试次数内就会继续重试,且都继承自RetriableException类。
不可重试的异常比如有RecordTooLargeException 发送的消息过大
SerializationException 序列化失败异常
KafkaException 其他类型的异常。
最后在使用完成后一定要手动的关闭Producer,
调用其close方法,让其将缓冲区的消息全部发送出去,不建议使用close(timeout),因为这样可能会导致消息的丢失。
接下来再Producer初始化的Properties中,还可以设置一些其他的参数,也比较重要
1. Acks,用于控制producer在什么时间返回响应给producer,可以设置为 0,1,-1
如果设置为“0”,就表示producer将消息发给了broker之后就不再理会消息了,这时候回调参数也就失去了作用,用户也无法感知到消息的失败与否。
如果设置为 “-1”,就需要leader和所有的ISR中的follower都落盘成功后返回给Producer。不过吞吐量因此是最低的
如果是1,那么就只需要leader进行落盘成功即可,这也是一种折中的方案。

推荐对于不同的消息,设定不同的acks值。
Buffer.memory,指定缓存消息的缓冲区大小,单位是字节,默认为33554432(32MB)
对于这一个空间的大小,是和消息发送的频率和大小有关的,如果设置过小,可能发挥不出什么缓冲作用,来一条就需要发一条。
Compression.type,是否压缩消息,以及压缩的类型,如果期望进行消息压缩,建议查看官方网站,推荐使用什么类型的压缩算法。
Retries,重试次数,默认值是0,表示不重试。不过在实际生产者,建议将其设置为一个大于0的值。
与之配合的还有一个retry.backoff.ms的值,来设置多少秒来重试一次。
Batch.size
将发往一个分区的多个消息封装进一个batch中,当batch满了,就会发送出去。而一个batch中包含多少个消息就是由这个参数控制,默认是16384,也就是16KB,合理的增大这个值,可以增加吞吐量。
Linger.ms,如果一个消息放入了缓存中,即使没有达到batch.size,也会在多少时间后直接发出去。不过关于这个值,即便我们总是希望消息尽快的发送,但如果设置的过短,也会导致吞吐量的下降。
Max.request.size,用于控制producer发送请求的大小,但是由于请求是包含一些头部数据结构的,所以这个总大小并不能完全等于消息的个数乘以单个消息的大小,所以考虑设置大一点。
Request.timeout.ms,当消息发给broker之后,broker需要在规定时间内件消息返回给producer,默认是30秒,如果broker在30秒内没有返回给producer,就会被认为超时了,抛出TimeoutException异常。