基础数学课30搜索引擎的构建
本次我们说下如何构建一个搜索引擎,搜索引擎最关键的点在于需要满足用户的搜索需求。最为常见的模型就是布尔模型,只需要考虑单词是不是出现在文档中,如果出现了就返回,不出现就不返回。在此基础上,我们还可以使用向量空间模型来衡量文档和用户查询之间的相似度,确保两者是相关的。
在文本搜索系统中,往往包含两个重要的模块,离线的预处理和在线的查询分解。最为简单的实现如下。
首先是离线预处理,也就是索引阶段,主要是文本预处理和倒排索引构建两个步骤,其中文本预处理很简单就是分词,移除停用词,取词干,归一化,扩充同义词。
然后进行索引计算,将出现的词干作为key,出现的文档集合作为值进行保存。
其次是在线查询,这个过程也是现将用户的输入转换为单词,然后根据单词,检索出文档,进行匹配。
只不过计算的时候,布尔模型只判断是否存在,向量空间模型VSM则是计算查询向量和待查询向量的余弦夹角。语言模型则是计算匹配的贝叶斯概率。
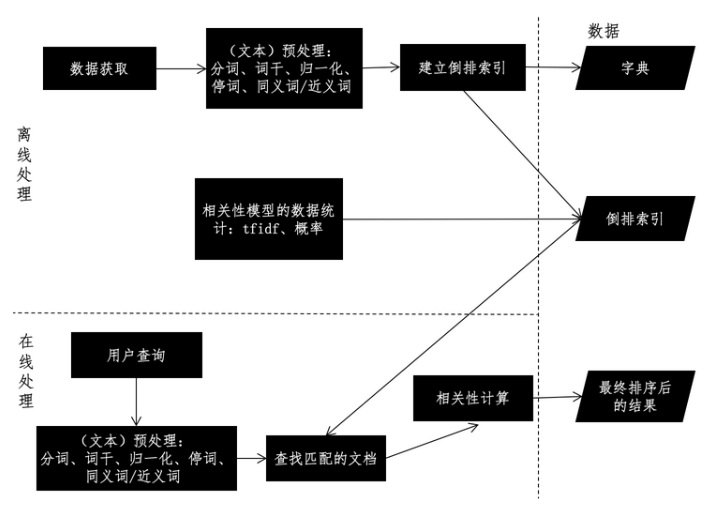
在实际落地的时候,往往为了满足上述的要求,我们在倒排索引中,key对应的数组中存放的往往是对象,比如词频 tf, 词频-逆文档频率 tf-idf,还有诸如词条出现的摘要。
在利用具有这些信息的对象形成倒排索引后。
后续判断相似度就不难了,由如下的公式组成
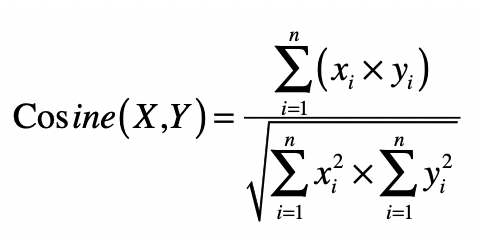
如果直接进行计算,那么我们的时间复杂度相对较高
但是如果我们可以使用倒排索引进行提前的规避,可以大大减少计算量。
我们之前设计的倒排索引保存了tf-idf的信息,所以可以直接获取到分子部分,至于分母。
则是用户查询的向量和文档向量的范数,相对来说数量较少。
这个就是一个简单的搜索系统的建立
之后还有一个问题,如果我们的搜索系统是建立在电商平台的呢?
因为电商平台非常的讲究精准。这就需要从几个方面找下原因
- 商品的标题比较短,这种情况下,商品的标题,名称就成了主要搜索属性,需要去除商品的简介的信息
- 关键词往往出现在了标题等地方,考虑频率往往不太需要,所以可以减少
- 用户的搜索往往比较短,所以更需要关键词。
针对上述的问题,我们主要进行几点的优化
- 首先只从商品的标题以及副标题中取出数据。
- 利用朴素贝叶斯处理商品,从而确定用户的关键词对应哪些商品,并给出一个排序。
- 利用用户的后续操作,进行顺序上的调整。比如用户输入了咖啡,然后最多的下单数量或加入购物车的是冲饮咖啡,咖啡豆,咖啡饮料,那么就可以将这个分类排在最前面。
在上述的几点优化中
朴素贝叶斯可以利用大量的标注数据进行计算,但是无法很好的区分关键词的分类,比如咖啡色衣服和咖啡的区别。
而对于用户后续操作的统计,则有一个冷启动的问题。
所以应该综合使用。
P(C∣query)=w1⋅P1(C∣query)+w2⋅P2(C∣query)
P1是对应的概率,w1是第一种的权重。
根据不断地学习,让其中w2 p2的比重越来越大。
那么我们就可以以ElasticSearch为例,讲一下如何进行分类结果的排序。
ElasticSearch采取了类似向量的空间模型的方式进行排序,但是这里我们利用es提供的Similarty进行统一得分。然后利用后续用户行为进行行为的优化。
比如查询咖啡,咖啡饮料的得分应该是0.85,咖啡色衣服和咖啡味香薰应该是0.15。所以我们就可以组成如下的查询json方便ES进行排序。
| {
“query”: { “bool”: { “must”: { “match_all”: { } }, “should”: [ { “match”: { “category_name”: { “query”: “咖啡饮料”, “boost”: 0.85 } } }, { “match”: { “category_name”: { “query”: “咖啡色衣服”, “boost”: 0.15 } } }, { “match”: { “category_name”: { “query”: “咖啡味香薰”, “boost”: 0.15 } } } ], “filter”: { “term”: {“listing_title” : “咖啡”} } } } } |
利用其中的boost字段,进行了查询结果的排序。从而让咖啡饮料排到了最前面。
最后总结下,相关性搜索往往是搜索引擎的核心模块。其中我们分为了两大模块,数据预处理和用户查询。在其中,我们还会用到诸如向量空间模型,概率模型等常见模型。
并利用后续用户的操作记性优化。