基础数学课29 缓存系统的建立
如何通过哈希表和队列实现一个缓存系统,对于缓存系统的定义,这里简单的说明下,缓存可以定义为临时的数据交换区,其比普通的存储介质速度更快。
在设计缓存机制过程中,需要考虑两个因素,一方面是命中率,需要让查询尽可能的命中缓存。为了提高命中率,就需要保证缓存系统中尽可能的存储最经常访问的数据。
常见的策略有最少使用LFU策略和最久未用LRU策略。LFU会记录每个对象被使用的频率,将次数最少的对象剔除,LRU则是记录每个缓存对象的最近使用情况,将最远使用的对象剔除。
第二个因素是更新周期,虽然缓存处理速度很高,但这并不代表被访问的数据一成不变。如果我们更新速度慢了,导致用户没有读到最新的数据,很可能导致应用逻辑的错误。
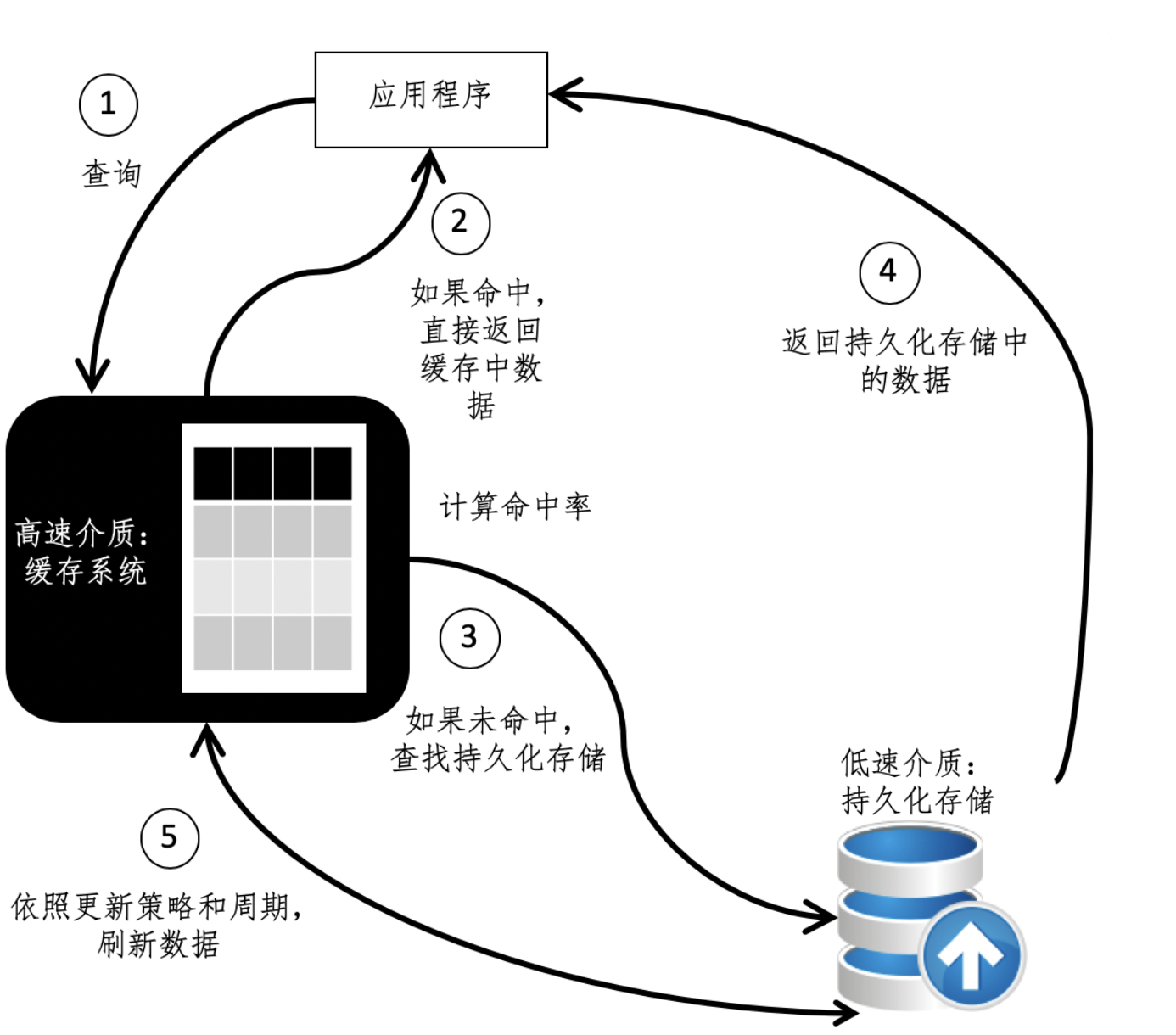
那么我们就利用哈希表和队列,设计一个最久未用的LRU策略的缓存。
其中哈希表用于判断缓存是否在缓存系统中。
其次是队列,利用队列的先进先出特性,实现LRU最久未用策略。最久远的对象会被淘汰。详细过程为,根据缓存系统大小,估算队列的最大值,作为队列上限。
然后访问数据后,将其加入队列的末尾,同时判断队列是否已经满了,如果已经满了,就需要淘汰一些缓存中的数据。这时候就需要移除队列头部的结点。同时从哈希表中移除对应的结点。
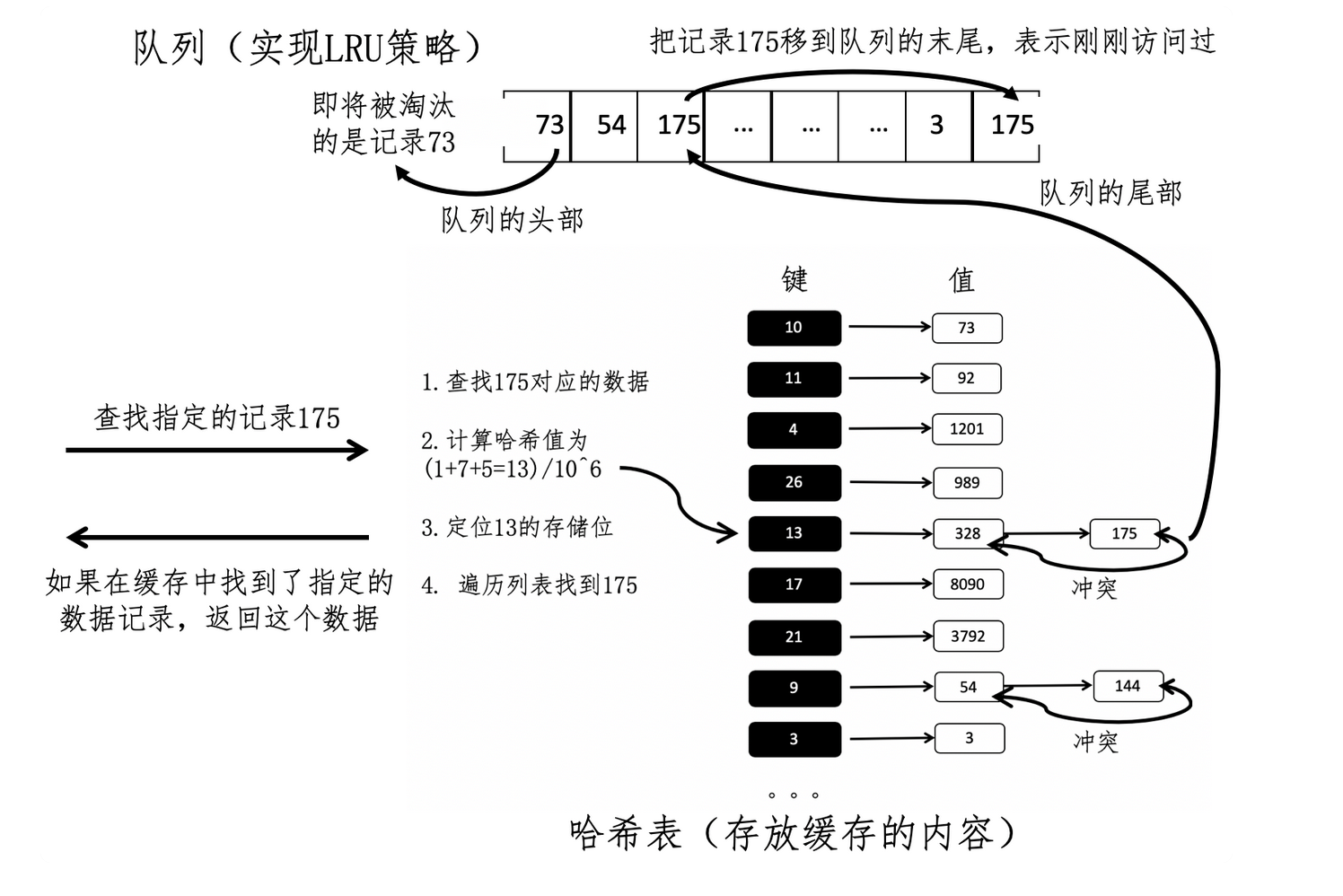
从上面的流程,我们可以看下整体的流程。
比如我们需要请求175,首先通过哈希计算得到175对于的数值,比如就是13,然后根据13得到对应的链表。并遍历链表得到175对应的结果。在获取结果之前,将队列中175的结点挪到队列的最后,远离被淘汰的命运。
之后再尝试获取到1228对应的数据时候,这条记录并不再缓存之中,所以在从硬盘中获取到的了记录,就可以将记录放入缓存区,并更新队列。这时候因为队列已经满了,所以需要将队列头部的结点出队列,将出队的记录从哈希表中删除。将新的1228对应数据放入哈希表中
最后总结一下
缓存在现代系统中扮演着非常重要的角色。小到CPU,大到互联网站点。都需要使用缓存。为了保证缓存系统的高效利用,这里我们提出了多种淘汰的策略,包括LRU和LFU。