我们说一下如何构建一个生产系统可用的Redis缓存集群+
Redis本身支持集群,即为Redis Cluser,Redis Cluster相比较于单节点的Redis,可以保存更多的数据,更大的并发,做到了高可用,在单个节点故障的情况下,继续提供服务
Redis Cluster如何进行的集群分布的呢?本质上也是通过分片的方式,将集群分布到多个节点上,Redis Cluster如何分片的?引入了一个槽的概念,本质上就是哈希槽,利用hash来计算分散在哪个槽上,槽的数量也是固定的16384 (16*1024)个
计算的方式为
HASH_SLOT = CRC16(key) mod 16384
先计算出CRC值,然后取模于16384,得到具体的槽
槽的位置是利用集群中每个Reids各自去保存的,集群初始化的时候,Redis自动分配16384个槽,然后当用户去请求一个key的时候,Redis先计算出Key对应的槽,然后找到槽在哪个节点上,然后重定向到这个节点上
解决了分片问题,在进行水平扩容的时候,往集群中增加节点,需要给其分配一些槽,可以进行手动的分配也可以利用官方提供的redis-trib-rb脚本来重新分槽
分片可以解决Redis的海量问题,但是在高可用方面,Reids需要进行解决对应的高可用问题
我们可以增加从节点,做主从复制,Redis Cluster支持给每个分片增加多个从节点,从节点刚刚连接到主节点的时候,会先给主节点发送一个SYNC的命令,请求一次全量的复制,然后之后主节点就会将更新的命令同步传给从节点,主节点故障,会导致从节点中选出一个节点作为主节点继续提供服务.集群其他的节点会了解到新节点的地址
然后是高并发相关,需要读写分离,对于这个问题,理论上Redis也支持读写分离
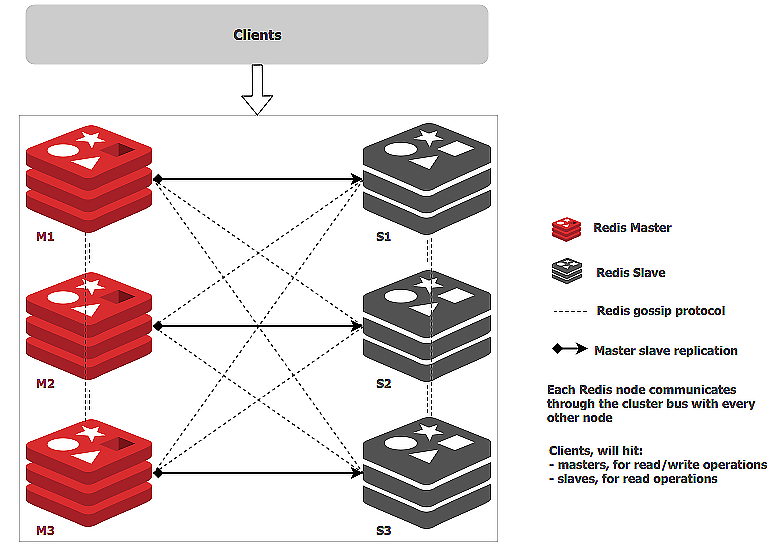
但是其并不适合于大规模集群
Redis Cluster适合于中小规模的Redis集群,但是不适合大规模集群,毕竟Redis的每个节点上保存了所有槽和节点的映射关系表,客户端可以访问任意一个节点,然后通过重定向的命令,找到数据所在的节点,这种去中心化的保存方式非常不适合于集群变化时候消息的变更
那么,如何使用Redis进行构建大规模的集群呢?
一般的厂子里,每家的解决是不同的,但总体都是大同小异的
我们可以再Redis和客户端之间,增加一层代理服务,代理服务有三个作用
第一个作用,负责在客户端和Redis之间进行响应和转发,客户端和代理服务打交道,代理收到客户端的请求之后,转发到对应的Redis,节点返回的相应经过代理返回客户端
第二就是监控集群中所有Reids的节点状态,如果发现有问题节点,我们及时进行主从切换
然后就是维护集群的元数据,这个元数据就是集群所有节点的主从信息,以及槽和节点关系的映射表
整体架构基本如下
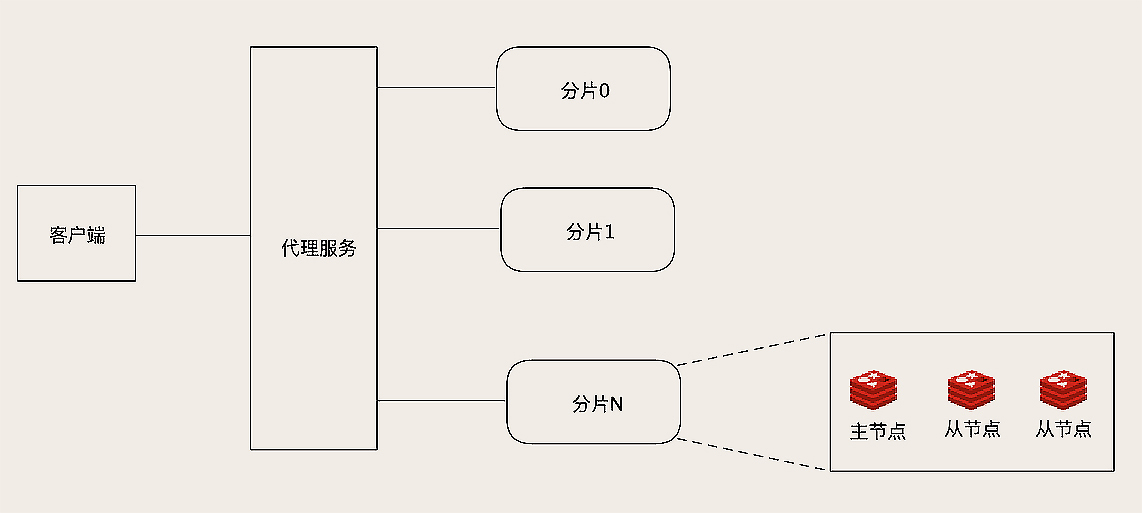
开源的Redis集群方案twemproxy和Codis就是这种架构
这个结构的有点就是对客户端透明,从客户端的视角看,整个集群和超大容量的单节点redis是一致的,并且分片算法是代理服务控制的,扩容更加方便,新节点加入后,直接修改代理服务的元数据
当然,这增加了一层代理转发,带来了新的性能消耗
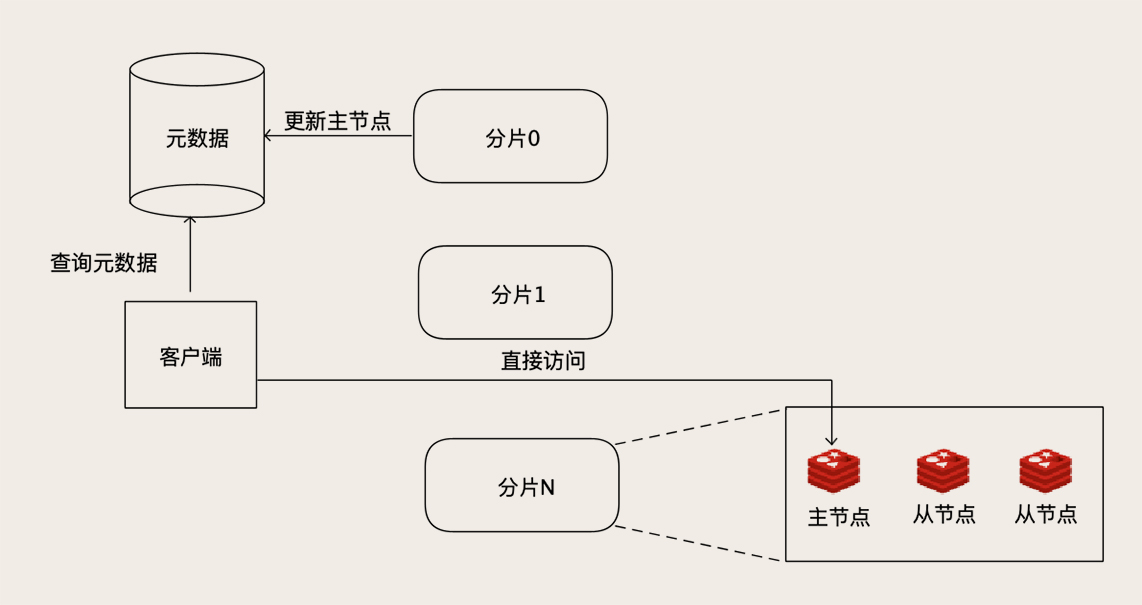
或者将代理服务的功能前移到客户端去,客户端发起请求之前,先查询元数据,获取集群信息
这个元数据虽然是一个单点,但是数据量并不大,访问量并不大,客户端还可以进行缓存元数据
但这个架构比较复杂,需要专门的定制化Redis客户端,只有规模较大的企业做得好些
我们说了三个Redis集群的部署方式
小规模的集群建议使用Redis Cluster,节点数量不多的时候,各方面都不错
大一些的可以考虑代理的集群架构
还有些定制客户端的方式,性能更好