我们说下如何进行分库分表,本质上就是延续上述的分片的思想,将1TB的数据拆分成每个10GB,降低单库的存储压力,知道了如何去做
那就考虑分库分表的规划问题了
是分库还是分表,分库是将数据拆分到不同的MySQL库中,分表就是讲数据拆分到同一个库的多张表中,
首先说,能不拆分就不拆分,因为越复杂的设计,维护和出问题的难度就越大
那么我们需要想一下,什么时候适合分表,什么时候不得不分库
分库分表的目的是为了避免数据量大,在数据量大的时候,分表可以解决问题
然后就是避免高并发导致的系统崩溃,如果想要避免高并发模块,可以将并发请求分散在不同的实例中,解决高并发需要分库
总结下就是数据量大就分表,并发高,就分库,其次就是越简单的设计可靠性就越高
然后是选择分片依据的问题
如何选择合适的列或者属性,作为分表的依据,这个属性一般称为Sharding Key,选择出来的重要考虑参数是我们的业务如何访问数据的
比如订单表,我们可以使用时间作为sharding key,查询条件上带着这个时间,这样程序就知道如何去哪个库/表上查询数据
或者按照订单ID作为Sharding Key来拆分订单表,拆分后,如果按照订单ID来查订单,可以先根据订单ID进行hash计算,来查出订单在哪个分片上,然后去查询
但是,用订单ID来分片有个问题,就是查询条件往往是用户ID,我们无从得知订单在哪个分片上
如果强行查询,需要每个分片上都查询一边
如果将用户ID来进行查询,也会有同样的问题,因为存在使用订单ID来查询的时候,没法找到订单ID在哪个分片了,所以,如何办呢?
我们可以在订单Id中加上用户的Id,这样,就可以在查询订单ID的时候,根据订单ID中的用户ID找到分片
类似,还有商铺相关的查询,对于商家查询自己店铺的订单,只能考虑借助第三方的存储系统,在其他的存储中解决问题,比如HDFS,或者利用大数据来解决问题
所以,有了分库分表,就需要考虑很多的查询问题,故分库分表一直是一种终极手段
如何选择分片算法呢?
常见的可以有按照范围查询
比如按照订单时间来进行查询,因为分片后,经常出现查询只落到一个分片上,比如落到当月,导致出现热点问题
所以范围分片的一个缺点在这里,但是范围分片适合数据量特别大,但是查询并不常见的ToB系统,比如电信运营商的监控,采集所有人的信号
更加常用的是哈希分片算法,比如,分24个片,sharding Key是用户ID的hash值,这样就可以满足很多要求了
但这要求我们计算哈希算法要能够分散的足够均匀,不然还是会出现热点
最后是查表法,利用一张表来决定sharding Key在哪个分片上,根据一张表维护数据的均匀
这个好处就是灵活,怎么分配都可以,人为的将数据分配均匀了,分片可以随时改变的
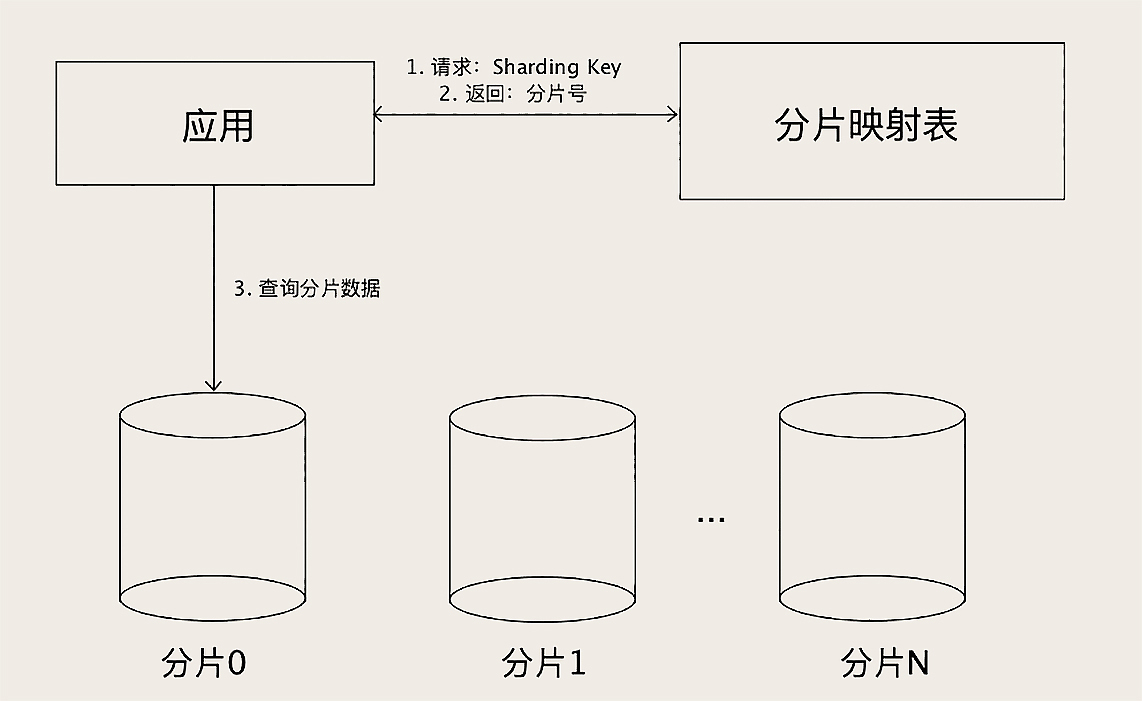
但是分片映射表本身的数据不能太多,不然可能导致这张表称为数据的热点
而且需要二次查询,实现起来更加复杂,不过可以利用缓存来加速查询,对于性能也不会太慢
分库分表往往是我们的最终手段,因为分库分表后,会对数据查询有很大的限制
分为多少个库需要估算,使用什么作为Sharding Key也需要估算,一定要根据业务,让查询尽量落在一个分片汇总,实在无法解决的,可以利用第三方存储来解决