在简单说Redis缓存问题上
可以常见的缓存策略有,Read/Write Through 和 Cache Aside 几种更新缓存的策略,都存在着缓存穿透的可能,如果缓存没有命中,就穿透缓存去访问数据库
我们需要做好缓存预热 缓存的命中率很高,Redis的缓存就即为有效
那么,在超大的系统中,缓存会面临什么样的问题,采用何等的策略来更新缓存呢?
首先是缓存穿透的问题,为了解决缓存穿透的问题,最好的方式就是讲的大量乃至所有的数据都缓存在Redis中,然后直接从Redis中读取数据,但是这带来了一个新的问题,就是缓存中的数据如何更新呢?
比如说订单服务这种商城的核心的业务,一个可行的方法是,启动一个更新订单缓存的服务,接收订单变更的MQ消息,然后更新Redis中缓存的订单服务
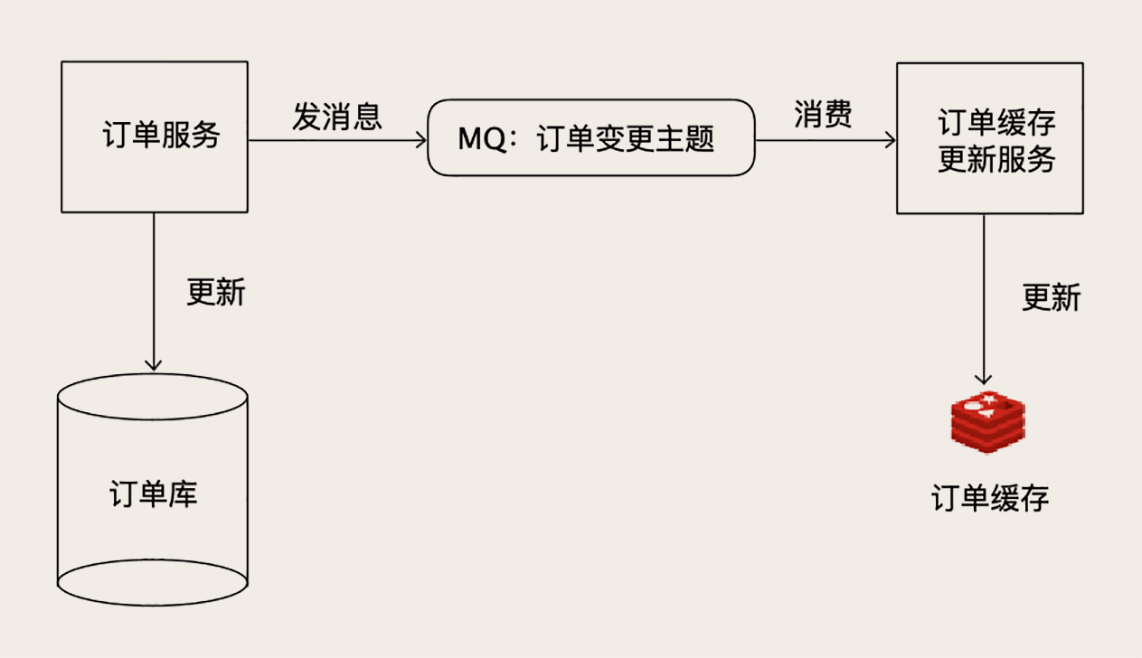
利用MQ的消费机制来保证数据可达和不丢失,这样更新缓存还是不错的选择,实现起来比较简单
或者是利用Binlog来更新缓存
我们可以采用另外的架构设计,因为如果MQ服务挂了怎么办
数据服务只负责处理业务的逻辑,更新数据库,并不关心更新缓存,缓存的更新和MySQL交互,伪装为MySQL的从节点,从MySQL中接收Binlog,解析Binlog之后,得到实时的数据变更信息,然后更新Redis缓存
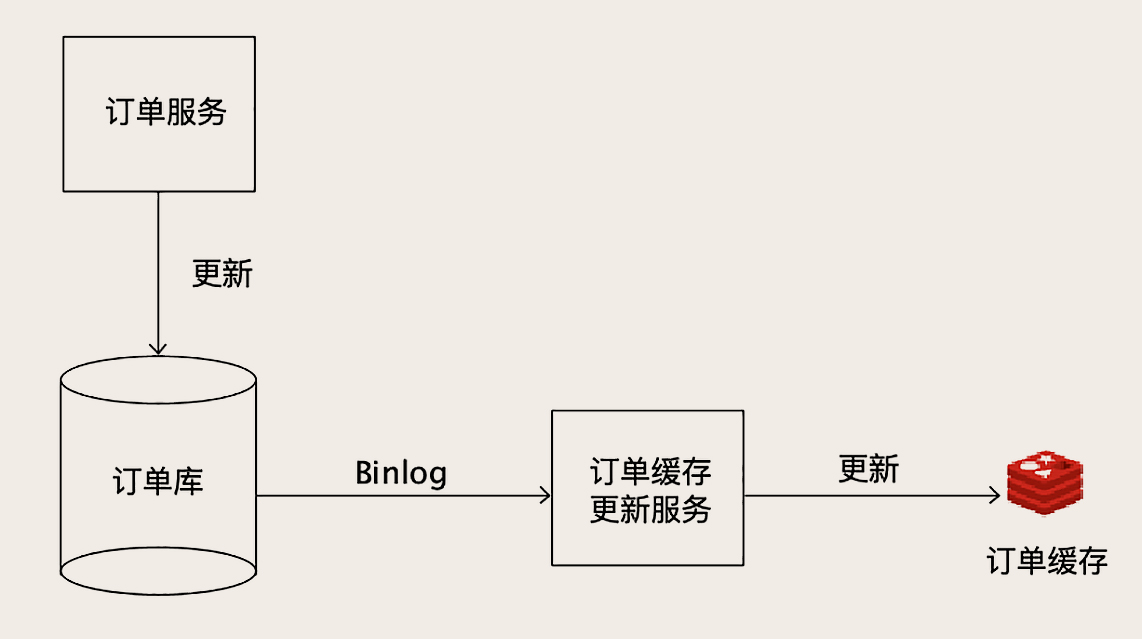
这样,本质上也是异步的订阅数据变更,然后更新Redis,不过读取Binlog,通用性更强了,但是需要我们了解并解析Binlog
很多开源的项目提供了订阅和解析MySQL binlog的能力,比如开源项目 Canal,
就是伪装为一个MySQL的从节点,向主节点发送dump请求,MySQL收到后,推送BinLog给Canal
Canal解析BinLog为结构化数据,给下游程序使用
我们做一个简单的示例
首先下载并解压Canal
| wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz
tar zvfx canal.deployer-1.1.4.tar.gz |
配置MySQL,在MySQL配置文件中开启Binlog
| [mysqld]
log-bin=mysql-bin # 开启Binlog binlog-format=ROW # 设置Binlog格式为ROW server_id=1 # 配置一个ServerID |
然后查看相关的binlog文件和配置
show master status;
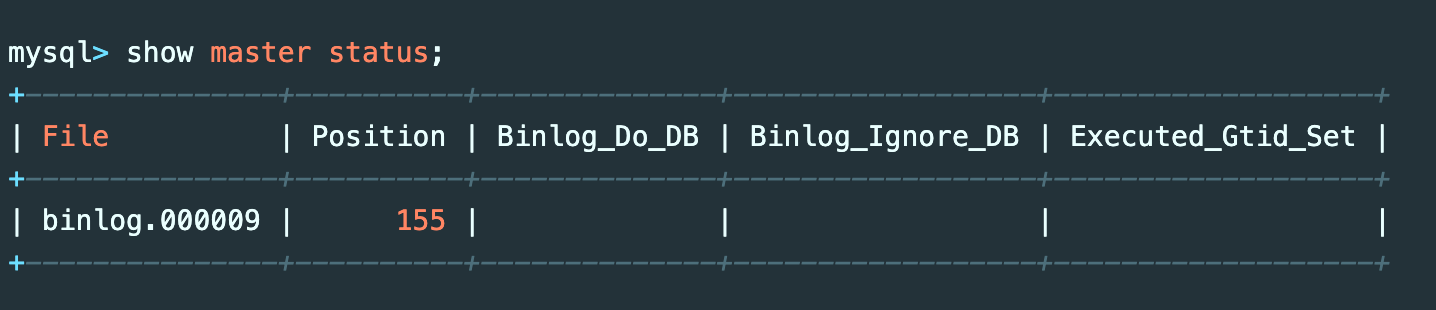
了解了File和Position两列的值,配置Canal,编辑Cancel的配置文件
canal/conf/example/instance.properties,方便连接到MySQL
| canal.instance.gtidon=false
# position info canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name=binlog.000009 canal.instance.master.position=155 canal.instance.master.timestamp= canal.instance.master.gtid= # username/password canal.instance.dbUsername=root canal.instance.dbPassword=root canal.instance.connectionCharset = UTF-8 canal.instance.defaultDatabaseName=test # table regex canal.instance.filter.regex=.*\\.. |
我们配置了MySQL的连接地址,库名,用户名和密码,配置了
对应的binlog位置和position的行数
然后就可以启动Canal服务了
canal/bin/startup.sh
然后查看对应的log文件,canal/logs/example/example.log,查看里面是否有报错
然后启动之后,开启一个端口11111等待连接,客户端连接Canal之后,之后Canal服务拉取数据,之后写入Redis之后,给Canal返回处理成功的相应,确认消费之后,才能拉去下一批数据,不然拉取的还是同一批数据
接下来进行Redis相关更新程序的编写,就是利用Java编写的
| while (true) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据 long batchId = message.getId(); try { int size = message.getEntries().size(); if (batchId == -1 || size == 0) { Thread.sleep(1000); } else { processEntries(message.getEntries(), jedis); } connector.ack(batchId); // 提交确认 } catch (Throwable t) { connector.rollback(batchId); // 处理失败, 回滚数据 } } |
拉取数据,只要能拉取数据,就更新缓存,不然就睡会,然后每次获取到,返回一个响应成功
这样,我们就完成了数据自动同步到Redis中,Demo在此
我们处理超大规模并发的场景时候,并发的请求数量非常大,不能有任何的缓存穿透,可能打崩数据库引发雪崩效应
对于数据更新,我们可以考虑使用