ZAB的领导者选举,就是选举了一个适合当领导者的节点,但是这时候,这个节点并不能直接投入使用,毕竟直接用这个可能出现集群的故障问题,所以还需要进行成员发现和数据同步的操作
那么我们就说下数据同步和成员发现的操作概述
1.确立领导的关系,成员发现阶段,领导者和大多数跟随者建立连接,并在此确认各个节点对自己当选领导者无异议
2.处理冲突数据,在数据同步的阶段,领导者以自己的数据为准,解决了各个节点的数据副本的不一致性
那么我们分别说下这两者的具体实现
新的领导者要确立自己的领导关系,作为唯一有效的领导者,领导各个备份节点一起处理读写请求
选举完成后,在成员发现阶段进行管理的确认
领导者会递增自己的任期编号,基于任期编号值的大小,来跟跟随者协商,建立领导者关系,在跟随者认同的时候,也只会认同任期编号比自己的节点,作为领导者
具体的例子可以看下面
假设有一个Zookeeper的集群,节点由A B C组成,领导者A已经宕机了,C是新选出的领导者,B是新的跟随者,B的最大事务是 <1,10> C是 <1,11> 1就是任期编号
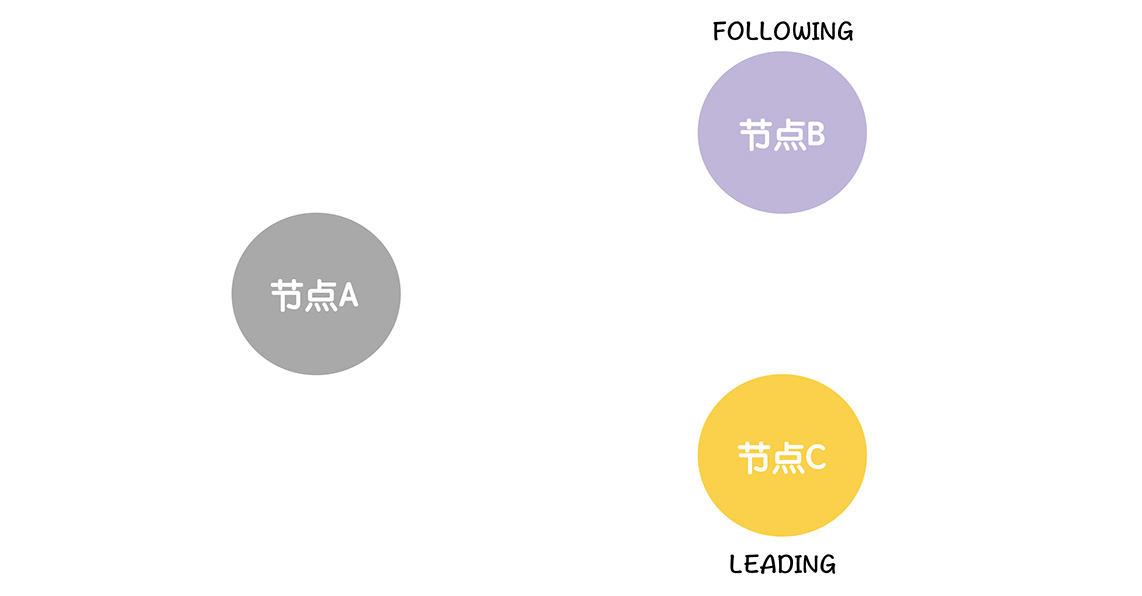
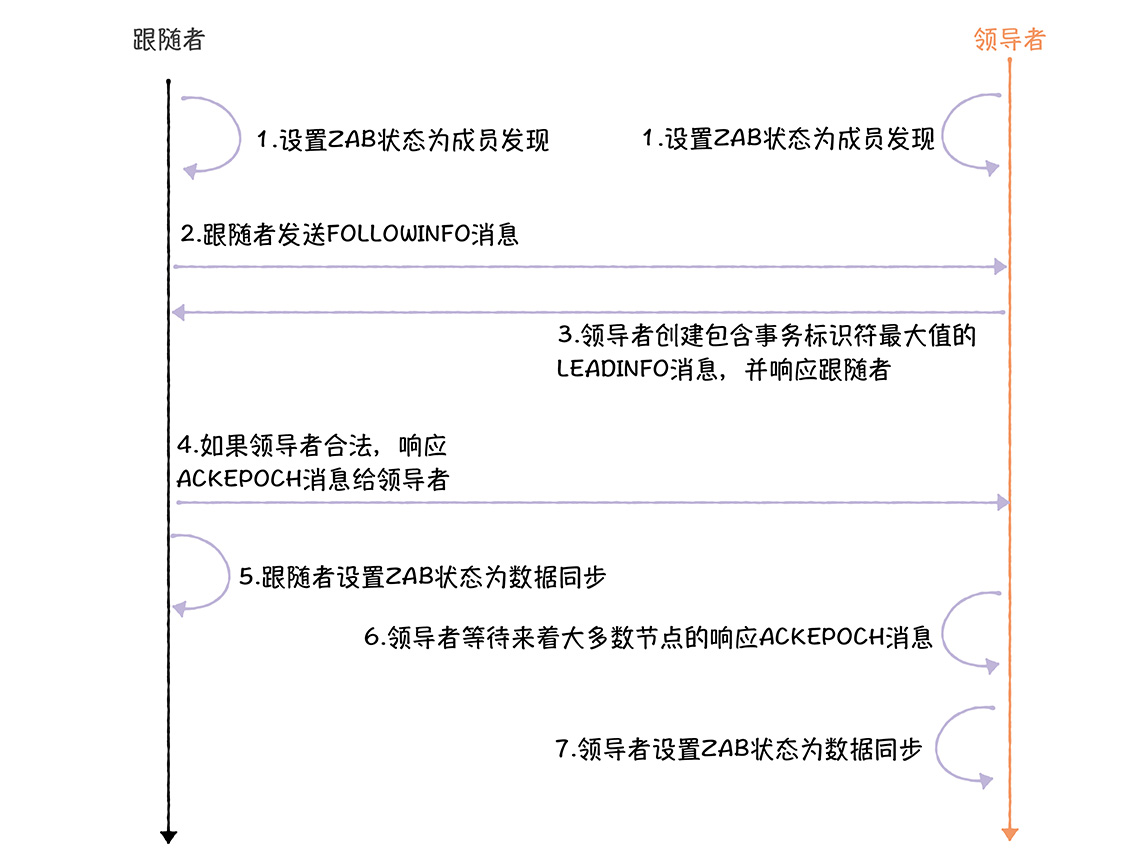
首先,B C双方将自己的ZAB状态设置为成员发现,DISCOVERY,说明选举ELECTION阶段结束了
ZAB定义了几种节点的运行状态
ELECTION 选举状态, 表明节点在进行领导者选举
DISCOVERY 成员发现状态,节点在协商沟通领导者的合法
SYNCHRONIZATION 数据同步状态,表示集群各个节点以领导者的数据为准,修复数据副本的一致性
BROADCAST(广播状态) 集群各个节点在正常处理写请求
我们的目的就是从成员发现到广播状态的一个转变
那么我们就说下选举状态的转变过程
首先B是会先联系C的,发送给它包含自己接受过的领导者的任期编号的最大值,也就是前领导者的A的任期编号1的FOLLOWINFO消息
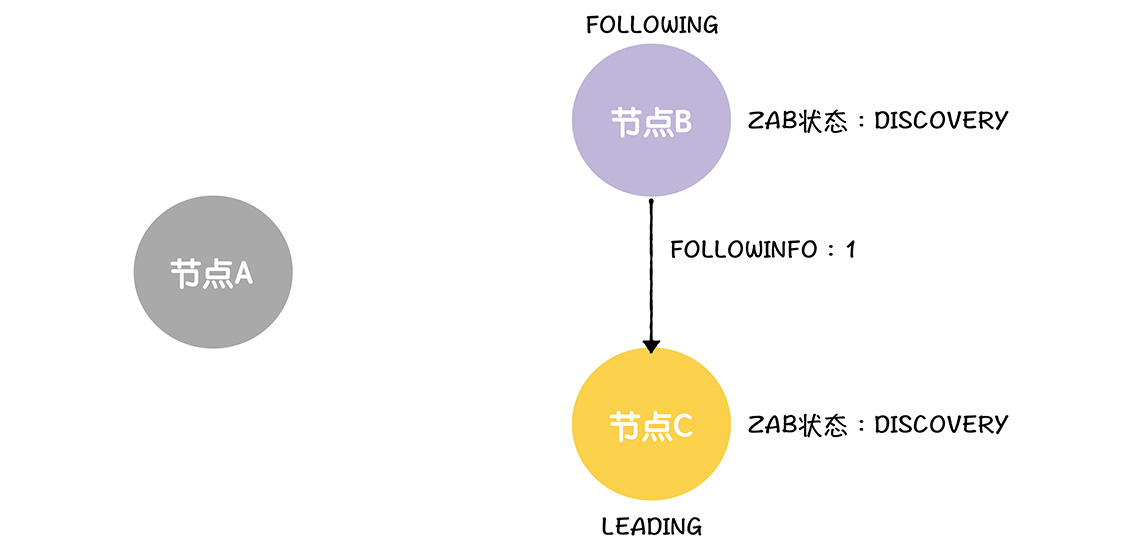
C会返回一个事务标识符最大值的LEADINFO消息发个FOLLOWER
领导者进入到成员能发现阶段后,会对任期编号加1,创建新的任期编号,基于新的任期编号,创建新的事务标识符<2,0>
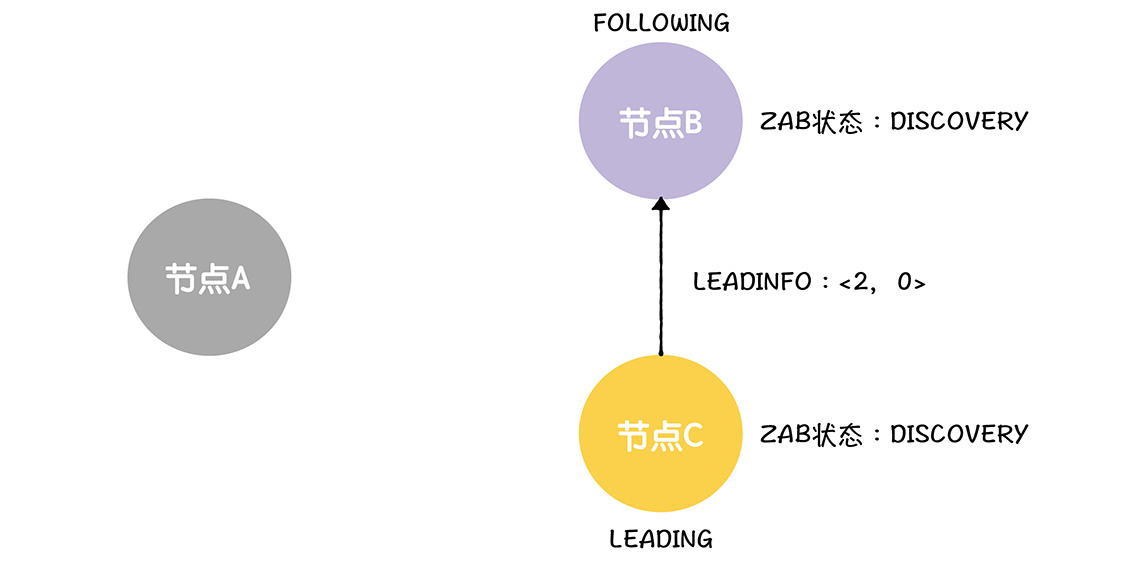
这个时候2>1,必然可以继续流程,如果小于等于了,那么就只能发起新的选举了,而这里,B将返回一个确认的ACK,设置自己的状态为数据同步
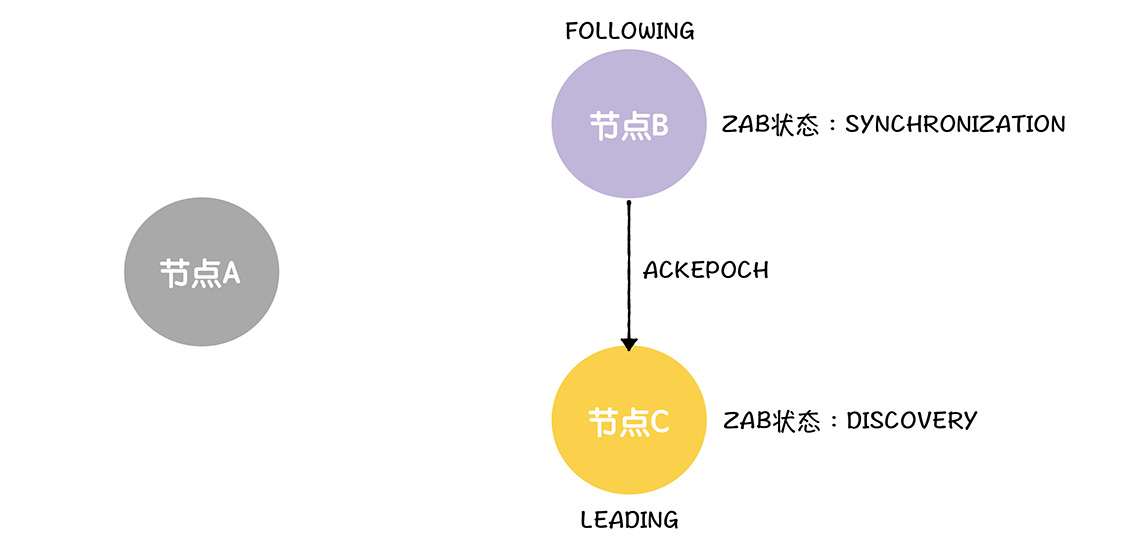
然后当领导者收到了来自大多数节点的ACKEPOCH消息的时候,就设置ZAB为数据同步,这样C完成了领导者确认步骤,进入数据同步
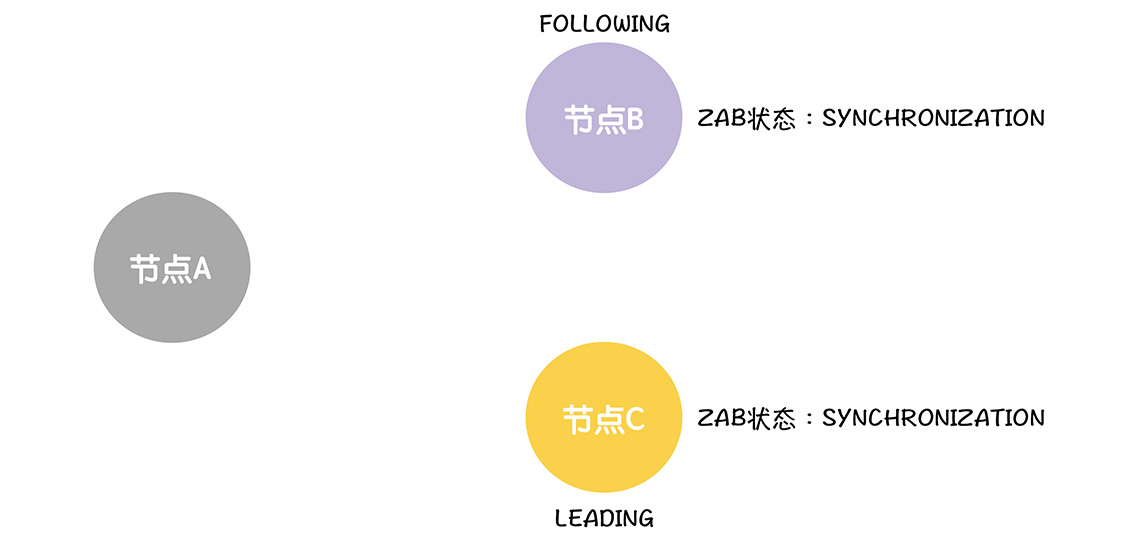
这样领导者实行领导者的职能,执行数据同步,解决数据冲突开始了
在解决的过程中,解决的方式有三种,DIFF TRUNC, SNAP三种
我们首先说,在这个场景,C的事务标识最大值是11,B是10,那么会使用DIFF方式修复不一致,返回差异数据给B
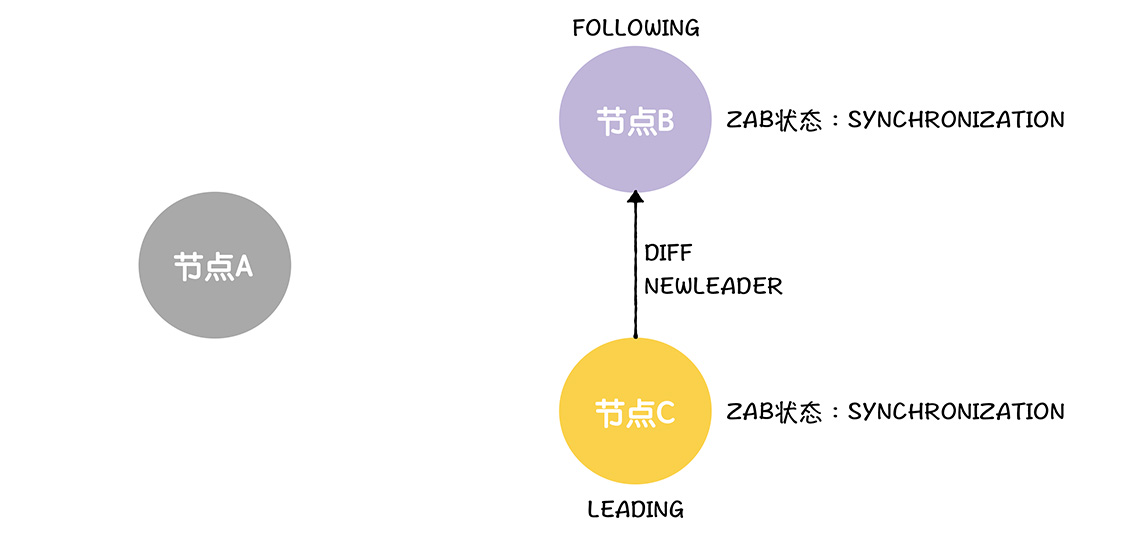
这里说的提交的提案的最大值,指的是其受到的最新提案的最大值,在Zookeeper实现中,节点退出跟随者节点的时候,会将未提交的提案进行保存
接下来,领导者收到了大多数节点的NEWLEADER消息的确认响应,将ZAB设置为广播,并且发送所有UPTODATE消息给所有跟随者,通知其数据同步完成了
当B收到了UPTODATE的消息的时候,就知道数据同步完成了,将ZAB设置为广播状态
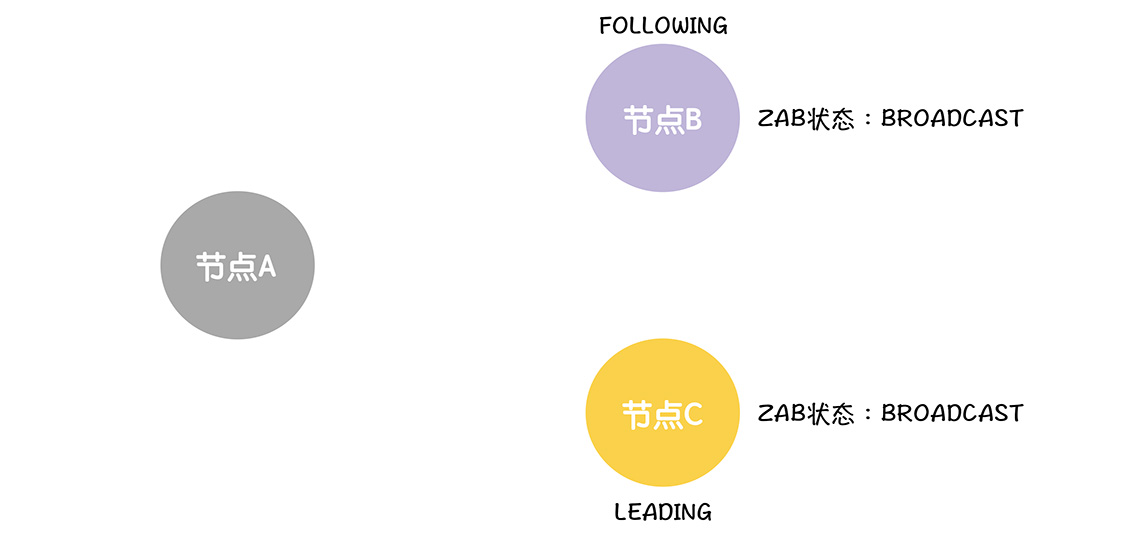
这就是整个的从选举到广播的流程,那么Zookeeper是如何实现的呢?
Zookeeper是如何恢复故障的?
我们看下Zookeeper的源码是如何实现的呢?
目标是确认大多数节点对领导者的领导关系没有异议,确立领导者的领导地位
流程类似上文讲述的流程
核心代码主要如下
选举后,各个节点会分别进入跟随者或者领导者状态,设置ZAB状态为成员发现
Follower.followLeader()函数中执行,设置ZAB状态为成员发现
self.setZabState(QuorumPeer.ZabState.DISCOVERY)
领导者进入了Leader.lead()函数中,设置ZAB为成员发现的状态
self.setZabState(QuorumPeer.ZebState.DISCOVERY)
然后跟随者联系领导者,发送自己现在的任期编号作为一个消息给领导者
//领导者建立网络连接
| // 跟领导者建立网络连接
connectToLeader(leaderServer.addr, leaderServer.hostname); connectionTime = System.currentTimeMillis(); // 向领导者报道,并获取领导者的事务标识符最大值 long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO); |
第三,接收到来自跟随者的FOLLOWINFO之后,在LearnerHandler.run()函数汇总,创建包含自己事务标示值最大的值的INFO信息,响应给跟随者
| // 创建LEADINFO消息
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, newLeaderZxid, ver, null); // 发送LEADINFO消息给跟随者 oa.writeRecord(newEpochPacket, “packet”); |
然后收到了这个LEADER的INFO之后,基于这个任期编号,判断领导者是否合法,不合法,就重新选举,合法就响应ACKEPOCH消息给领导者
| // 创建ACKEPOCH消息,包含已提交提案的事务标识符最大值
QuorumPacket ackNewEpoch = new QuorumPacket(Leader.ACKEPOCH, lastLoggedZxid, epochBytes, null); // 响应ACKEPOCH消息给领导者 writePacket(ackNewEpoch, true); |
跟随者设置ZAB状态为数据同步
| self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION); |
然后在整个LearnerHandler.run()函数之中,领导者会调用waitForEpochAck()函数,来阻塞和等待大多数的ACKEPOCH消息
ss = new StateSummary(bbepoch.getInt(), ackEpochPacket.getZxid());
learnerMaster.waitForEpochAck(this.getSid(), ss);
领导者收到了来自大多数的ACKEPOCH消息后,在Leader.lead()函数中,领导者将设置ZAB状态为数据同步
self.setZabState(QuorumPeer.ZebState.SYNCHRONIZATION)
然后是Zookeeper中的数据同步
就是通过跟随者和领导者交互来完成的,为了确保跟随者在节点上的数据和领导者节点上的数据是一致的,大概流程如下
第一,在LearnHandler.run()函数中,领导者调用syncFollower()函数,根据跟随者事务标识符的最大值,判断用哪种处理方式,进行同步
peerLastZxid = ss.getLastZxid();
boolean needSnap = syncFollower(peerLastZxid, learnerMaster);
同步的数据方式有三种
TRUNC DIFF SNAP,含义分别是什么呢?
这里需要说下peerLastZxid,跟随者节点上提案的事务标识的最大值
maxCommittedLog minCommittedLog,领导者节点内存队列中,以及提交事务的标识符的最大最小值,因为在Zookeeper中,为了高效的复制提案到跟随者上,会将一定数量的提交提案放在内存队列中,
那么TRUNC,就是当peerLastZxid大于maxCommittedLog时候,领导者会通知跟随者丢弃超过的那部分提案,就是peerLastZxid为11,领导者的maxCommittedLog为10,那么11会被丢弃
DIFF,当peerLastZxid小于maxCommittedLog,但大于minCommittedLog时候,会进行补完,比如peerLastZxid为0,领导者的maxCommittedLog为10,minCommittedLog为9,同步标示值为10的提案,给跟随者
SNAP:当peerLastZxid小于minCommittedLog时候,跟随者缺失提案比较多,就直接将整体数据同步快照数据给跟随者,然后覆盖本地的数据*
这就是上面说的,在失去领导者的时候,也会先保存下来,但是在这里同步过程中,会进行统一化的处理,让一切以领导者的数据为准,实现数据一致性
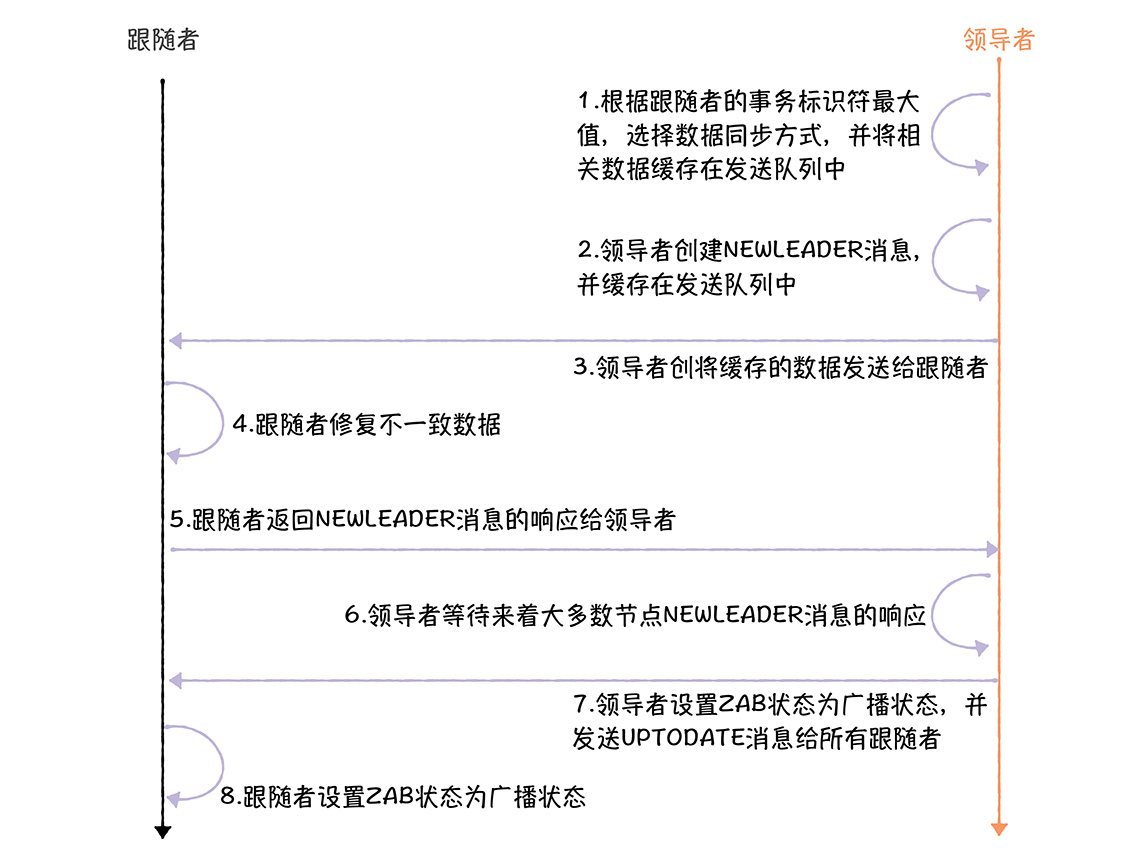
需要注意的是,在syncFolower()中,领导者只是将需要发送的差异数据缓存在了发送队列中,还没有真正的发送
| // 创建NEWLEADER消息
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, learnerMaster.getQuorumVerifierBytes(), null); // 缓存NEWLEADER消息到发送队列中 queuedPackets.add(newLeaderQP); |
在LearnerHandler.run()函数中,领导者使用了startSendIingPackets()函数,启动了一个新的线程,并经缓存的数据送给了跟随者
startSendingPackets();
跟随者利用syncWithLeader()函数,来进行处理领导者的数据同步
syncWithLeader(newEpochZxid);
然后跟随者收到来自领导者的NEWLEADER消息后,返回确认给领导者
writePacket(new QuorumPacket(Leader.ACK, newLeaderZxid, null, null), true);
然后在LearnerHandler.run()函数汇总,领导者等待来自大多数节点的NEWLEADER消息的响应
收到了大多数的NEWLEADER的消息后,领导者将自己的ZAB状态设为了广播状态
self.setZabState(QuorumPeer.ZabState.BROADCAST);
LearnerHandler.run中发送UPTODATE消息给所有跟随者,通知数据同步完成了
queuedPackets.add(new QuorumPacket(Leader.UPTODATE, -1, null, null));
然后跟随者收到了UPTODATE消息,就知道自己修复完了,可以处理写请求了,设置ZAB为广播
// 数据同步完成后,也就是可以正常处理来自领导者的广播消息了,设置ZAB状态为广播
self.setZabState(QuorumPeer.ZabState.BROADCAST);
这就开始正式处理写请求了
本章主要说了几个重点
1.成员发现,建立跟随者和领导者之间的领导者关系,通过任期编号来确认这个领导者是否是最合适的领导者
2.数据同步,通过以领导者的数据为准的方式,进行节点数据的副本一致,这个需要保证大多数原则
因为这个数据同步可能导致,处于提交的状态提案是可能改变的,为啥呢?
一个提案进入提交Committed状态,两种状态
复制到大多数节点,被领导者提交或者接收到来自领导者的提交的消息而被提交,提交的提案是不会被改变
在Zookeeper的设计中,节点退出跟随者,本地未提交的提案,注意的是,此时提交的天,可能未被复制到大多数的节点上,这种设计,会导致Zookeeper中,处于”提交”的提案可能被删除
那么就是这样的一个场景,写请求对应的提案,SET X =1 已经复制到大多数节点上,那么无论改变,都会被保存下
但是如果未被复制到大多数节点上,领导者广播消息中,领导者崩溃了,那么,提案 SET X =1,可以复制到大多数节点上,可能被删除,取决于新的领导者是否包含这个提案
提案提交的大多数原则和领导者选举的大多数原则,确保了复制到大多数节点的提案之后就不会发送改变,为什么呢?
少数节点为何我XID最大我不能成为领导者呢?