我们在学习ZK的时候,肯定是先尝试进行了一次写操作,再进行的读操作,比如先是create /geekbang 123 然后 get /geekbang
那么ZK是如何进行读写操作的呢?
在Zookeeper中,如何处理写请求,关乎着操作的顺序性,操作的顺序性影响着节点的创建,如何处理读请求,关乎着一致性,影响着客户端是否读到旧数据
然后,我们从Zookeeper系统的角度,分析整个读写的流程,透彻的理解背后的原理
在Zookeeper中,写请求必须在领导者上,如果跟随者接收到了写请求,必须将写请求转发给领导者,当写请求的提案被复制到大多数节点上的时候,领导者就会commit,并返回提交提案给跟随者,
读的操作可以在任何的节点上处理,而Zookeeper实现的是最终一致性
所以,我们理解了ZK的读写的不同处理方式,就可以合理的做资源规划了,对于读多的场景可以配置,5节点集群,而不是3节点集群
首先强调一点,在ZK之中,和领导者失联的节点,是不能处理读写请求的,比如,一个跟随者和领导者的连接发生了读超时,就会将自己的状态设置为LOOKING,此时其不能转发写请求给领导者处理,也不能处理读请求,只有找到领导者之后,才能继续处理
C和A B的网络不通了,那么C就会将自己的状态设置为LOOKING,此时既不能读操作,也不能写操作
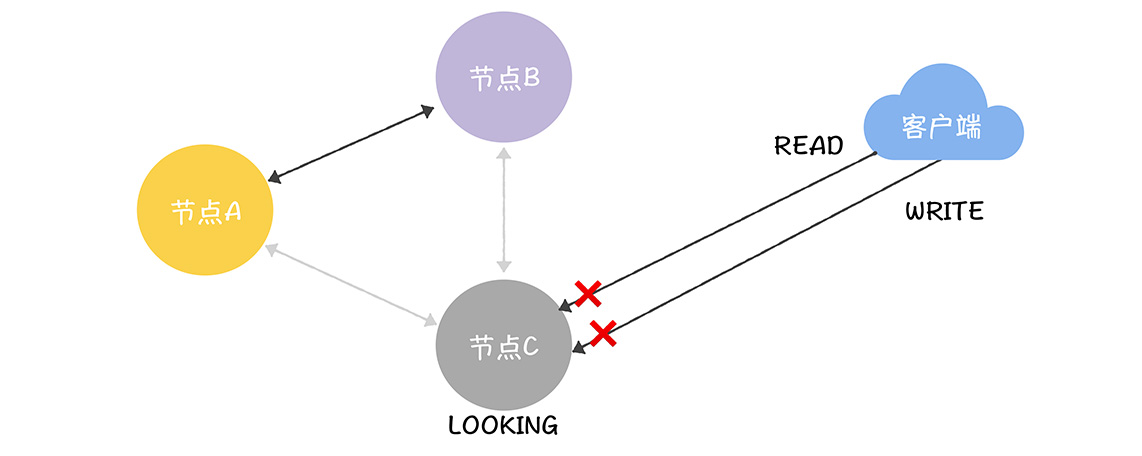
然后写请求时候,只有大多数的节点都进入广播阶段,才能继续接收写请求
因为,写请求都是在领导者节点上进行的,所以集群的写性能约等于单机
接下来我们,看下ZK的具体在代码上的实现
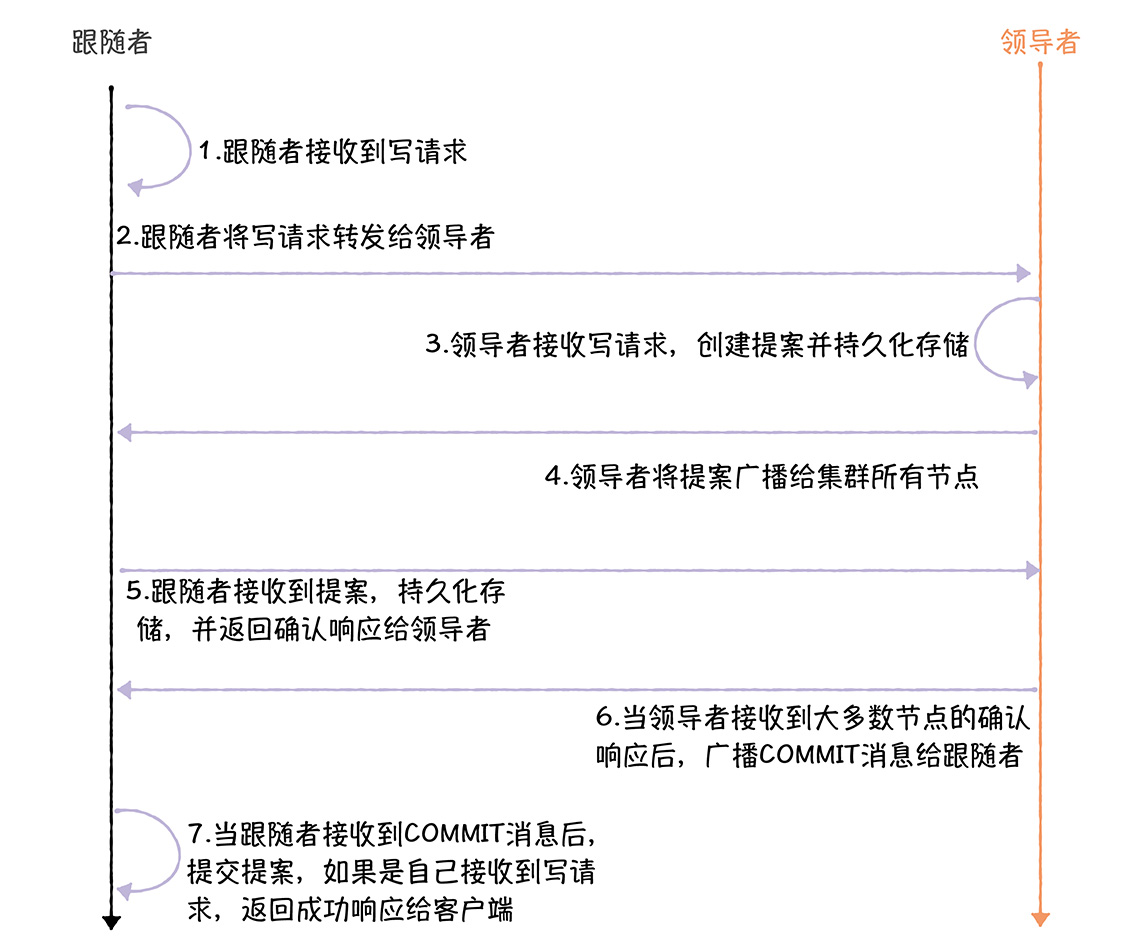
首先是写操作,在ZooKeeper代码中,流程基本如下图
整体流程如下
1.跟随者在FolloweRequestProcessor,processRequest()中接收到写请求,
系统会在ZooKeeperServer.submitRequestNow()中发送给跟随者
firstProcessor.processRequest(si);
| protected void setupRequestProcessors() {
// 创建finalProcessor,提交提案或响应查询 RequestProcessor finalProcessor = new FinalRequestProcessor(this); // 创建commitProcessor,处理提案提交或读请求 commitProcessor = new CommitProcessor(finalProcessor, Long.toString(getServerId()), true, getZooKeeperServerListener()); commitProcessor.start(); // 创建firstProcessor,接收发给跟随者的请求 firstProcessor = new FollowerRequestProcessor(this, commitProcessor); ((FollowerRequestProcessor) firstProcessor).start(); // 创建syncProcessor,将提案持久化存储,并返回确认响应给领导者 syncProcessor = new SyncRequestProcessor(this, new SendAckRequestProcessor(getFollower())); syncProcessor.start(); } |
但是在跟随者和领导者节点中的firstProcessor是不同的
当在submitRequestNow()中被调用时候,就分别进去了跟随者和领导者的代码历程
setupRequestProcessors()
我们分别创建了2条处理链,如下所示
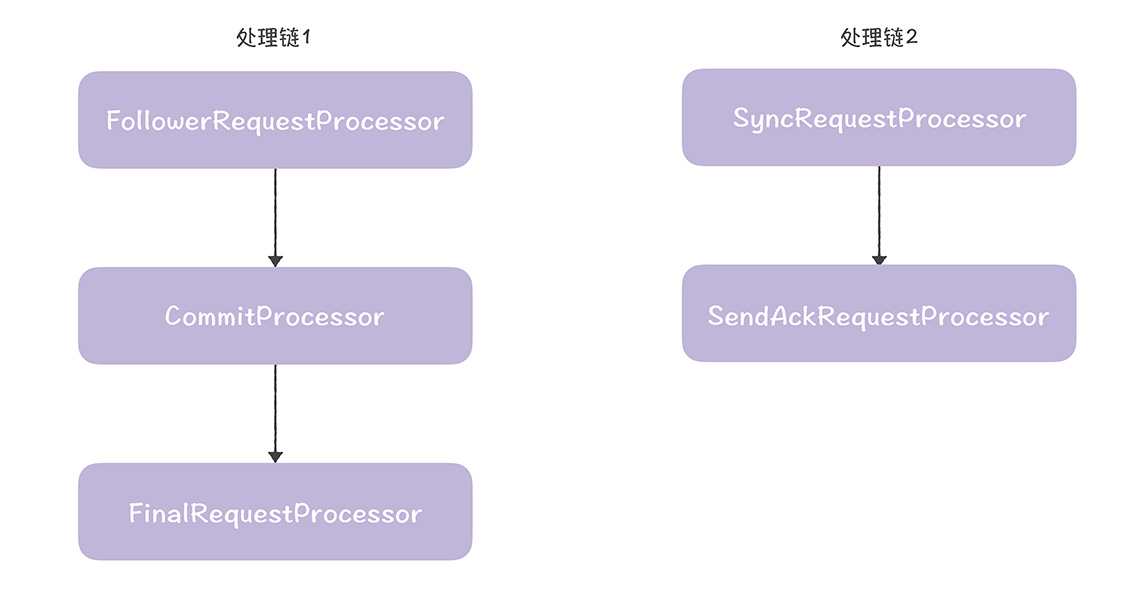 1,是核心处理链,实现了提案提交和读操作对应的数据响应,处理链实现了提案的持久化,返回确认响应给领导者
1,是核心处理链,实现了提案提交和读操作对应的数据响应,处理链实现了提案的持久化,返回确认响应给领导者
2.跟随者在FollowRequestProcessor.run()中将写请求发给领导者
// 调用learner.request()将请求发送给领导者
zks.getFollower().request(request);
3.领导者在LeaderRequestProcessor.processRequest()中接收写请求,并且最终调用pRequest()创建事务,并持久化存储
| // 创建事务
pRequest2Txn(request.type, zks.getNextZxid(), request, create2Request, true); …… // 分配事务标识符 request.zxid = zks.getZxid(); // 调用ProposalRequestProcessor.processRequest()处理写请求,并将事务持久化存储 nextProcessor.processRequest(request); |
写请求在ZooKeeperServer.submitRequestNow()发给领导者
firstProcessor.processRequest(si);
而firstProcessor,在LeaderZooKeeperServer.setupRequestProcessors()中创建的
| protected void setupRequestProcessors() {
// 创建finalProcessor,最终提交提案和响应查询 RequestProcessor finalProcessor = new FinalRequestProcessor(this); // 创建toBeAppliedProcessor,存储可提交的提案,并在提交提案后,从toBeApplied队列移除已提交的 RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader()); // 创建commitProcessor,处理提案提交或读请求 commitProcessor = new CommitProcessor(toBeAppliedProcessor, Long.toString(getServerId()), false, getZooKeeperServerListener()); commitProcessor.start(); // 创建proposalProcessor,按照顺序广播提案给跟随者 ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this, commitProcessor); proposalProcessor.initialize(); // 创建prepRequestProcessor,根据请求创建提案 prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor); prepRequestProcessor.start(); // 创建firstProcessor,接收发给领导者的请求 firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor); …… } |
在其中,也是创建了2条处理链,
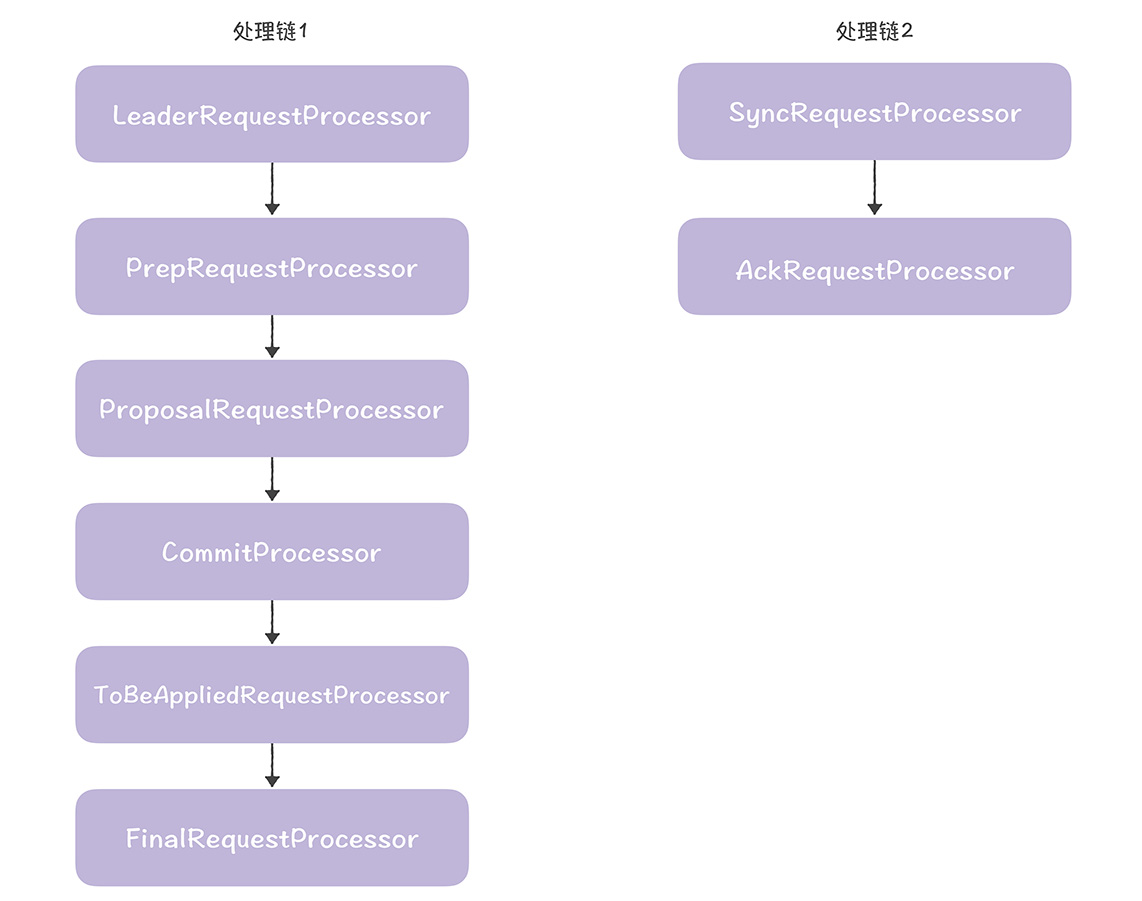
处理链1是核心处理链,最终实现了写请求处理和读请求对应的数据响应,处理链2实现了提案持久化存储,返回确认响应给领导者自己
4.领导者在ProposalRequestProcessor.prcossRequest()中,调用propose()将天给所有的节点
zks.getLeadere().propose(request);
5.跟随者在Follow.processPacket()中收到了提案,持久化存储,返回确认给领导者
// 接收、持久化、返回确认响应给领导者
fzk.logRequest(hdr, txn, digest);
6.领导者收到了大多数的响应后,在CommitProcessor.tryToCommit()提交提案,并广播COMMIT给跟随者
// 通知跟随者提交
commit(zxid);
// 自己提交
zk.commitProcessor.commit(p.request);
7.跟随者收到了COMMIT,在FollowerZooKeeperServer.commit()中提交提案,如果最初写请求是发给自己的,返回成功响应给客户端
| // 必须顺序提交
long firstElementZxid = pendingTxns.element().zxid; if (firstElementZxid != zxid) { LOG.error(“Committing zxid 0x” + Long.toHexString(zxid) + ” but next pending txn 0x” + Long.toHexString(firstElementZxid)); ServiceUtils.requestSystemExit(ExitCode.UNMATCHED_TXN_COMMIT.getValue()); } // 将准备提交的提案从pendingTxns队列移除 Request request = pendingTxns.remove(); request.logLatency(ServerMetrics.getMetrics().COMMIT_PROPAGATION_LATENCY); // 最终调用FinalRequestProcessor.processRequest()提交提案,并如果最初的写请求是自己接收到的,返回成功响应给客户端 commitProcessor.commit(request); |
这样,ZooKeerp就是完成了写请求的处理
那么就是读操作如何实现的?
写操作,读操作的处理简单很多了,接收到读请求的节点,查询本地的数据,响应数据给客户端就可以了,读操作的核心代码如下
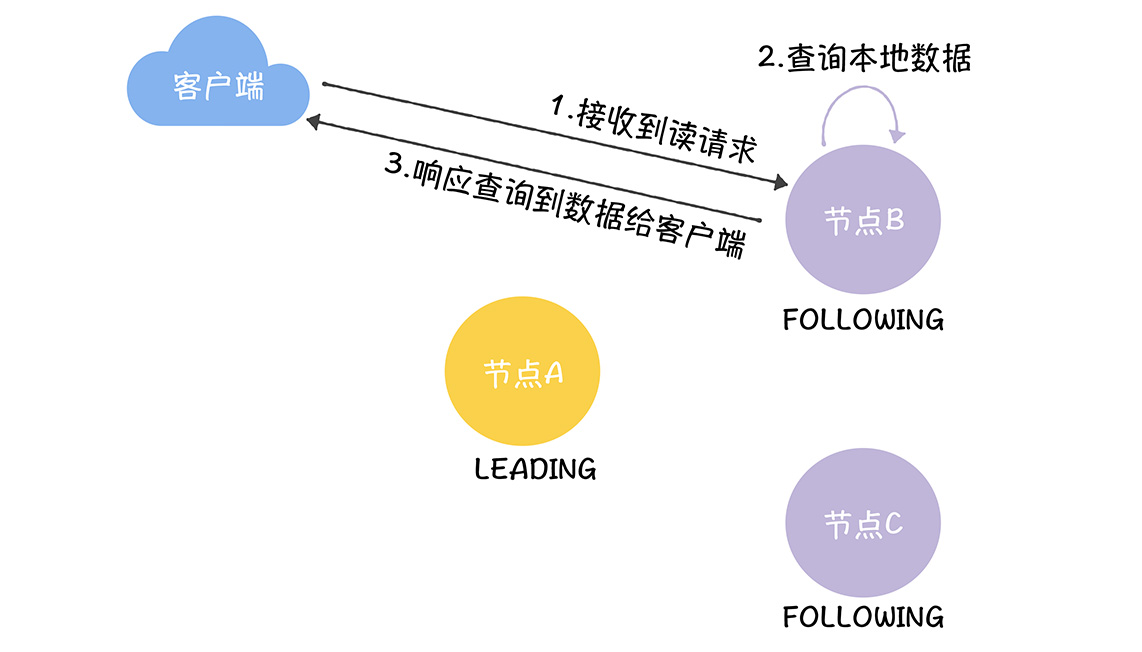
在代码中实现如下
1.跟随者在FollowerRequstProcessor.processRequest()中接收到读请求
2.在FinalRequestProcessor.processRequest()查询本地数据,dataTree中的数据
| // 处理读请求
case OpCode.getData: { …… // 查询本地dataTree中的数据 rsp = handleGetDataRequest(getDataRequest, cnxn, request.authInfo); …… break; } |
跟随者响应查询到数据给客户端
| case OpCode.getData : {
…… // 响应查询到的数据给客户端 cnxn.sendResponse(hdr, rsp, “response”, path, stat, opCode); break; } |
然后就完成了ZK的读数据
我们主要了解了ZK中的代码实现和核心流程,在其中
1.和领导者失联的跟随者,是不能处理写请求或者读请求的
2,ZK中,写请求只能在领导者节点上处理,读请求可以在所有的节点上处理,实现的是最终一致性
接下来,我们说下ZAB协议中的一些术语
提案 Proposal 进行协商的基本单元,可以认为是操作,指令
事务,可以指的是提案.经常出现代码中,未提交的事务经常被存储在事务日志中,并不是在数据库中常见的事务
接下来,我们会所下Raft和ZAB中的相同之处和不同之处
比如ZAB协议要实现操作的顺序性,而Raft的设计目标,并不仅仅是操作的顺序性,而是线性一致性,这就需要两者都需要保证日志的顺序性
而不同之处,
领导者选举,ZAB采用的时候见贤思齐,互相推荐的领导者选举之几,Raft选举是一张选票,先到先得的自定义算法,Raft必然发送的消息更少,选举就更加的快
日志复制,Raft和ZAB相同,都是领导者的日志为准,实现了日志的一致,日志必须连续的,必须按照顺序提交
读操作和一致性,ZAB的设计目标是操作的顺序,在ZooKeeper实现最终一致性,Raft是强一致性,而且Raft可以设置提供最终一致性
写操作,Raft和ZAB一致,写操作都在领导者处理
Raft的设计更加的简洁,并没有引入类似ZAB成员发现和数据同步的节点,而是当节点发起选举时候,递增任期编号,选举结束后,广播心跳,建立连接,然后向着各个节点同步日志,实现副本的一致性,ZAB的成员发现,可以和领导者选举合在一起,类似Raft,直接进入领导者阶段,数据同步阶段也可以先避开,毕竟没有要求先实现数据副本的一致性,才处理写请求的
而且,读操作可以在任何的节点上执行,读操作访问的是备份节点,为何没法保证每次都读到最新的数据呢?
虽然领导者向着大部分的跟随者节点发送了commit请求,但是并不会等待跟随者响应完成写入再返回客户端,而是直接发送了一个完成消息给接收到客户端请求的节点,这就导致,客户端去读取的时候,可能读取到的节点是没有数据生效的节点,所以没法保证每次都读到最新的数据