ZAB中,请求在主节点上执行,那么主节点一旦崩溃了,怎么办呢?
必然,选举新的领导者,新的主节点,如何选出呢?
整体的领导者选举,就是快速领导者选举协议 FastLeader Election.更能深刻的理解ZAB协议
首先是ZAB中支持的成员身份
分别是3种成员身份 ;领导者 跟随者 观察者
Leader:主节点,所有写请求的执行者
Follower:备份节点,响应心跳,进行存储,进行投票,可以处理读请求
Observer:可以存储和读请求,不能投票
还定义了4种成员状态
LOOKING:选举状态,这个状态下的节点认为当前集群中没有领导者,会发起领导者选举
FOLLOWING:跟随者状态
LEADING:领导者状态
OBSERVING:观察者状态
具体的选举过程如下
我们首先规定的投的投票信息的格式是
<proposedLeader,proposedEpoch,proposedLastZxid,node>,
proposedLeader,节点提议的,领导者的集群ID,集群配置指定的ID,
proposedEpoch,节点提议的,任期编号
proposedLastZxid,节点提议的,领导者事务标识符最大值
node:投票的节点,比如节点B
一个集群,其中由A B C组成 A是领导者, B C是跟随者,那么epoch是1,lastZxid是101和102,那么节点A如果宕机了,会如何选举呢?
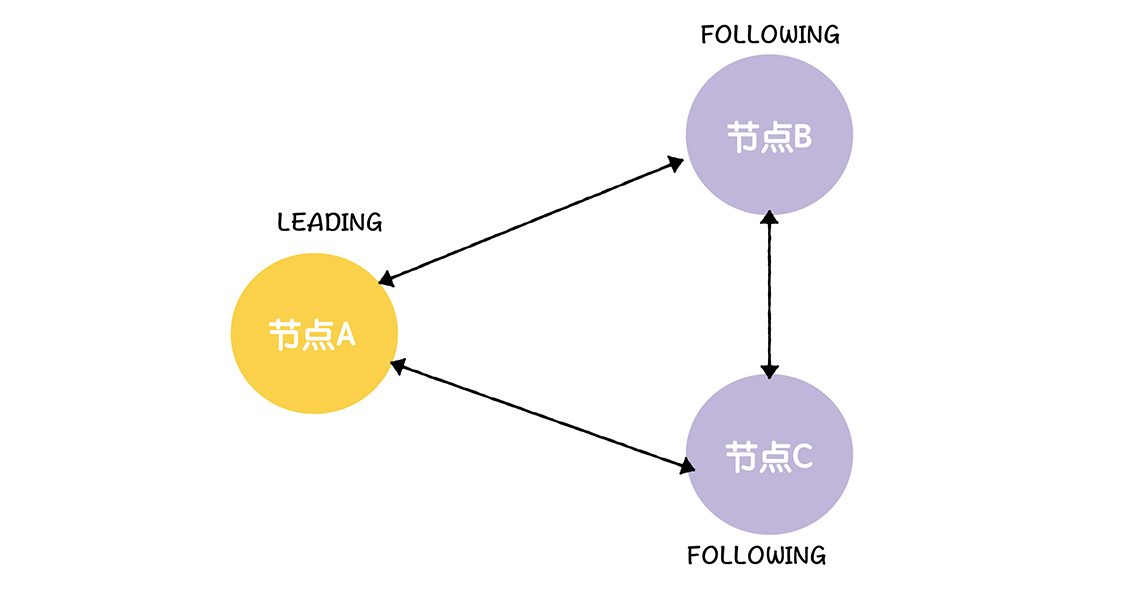
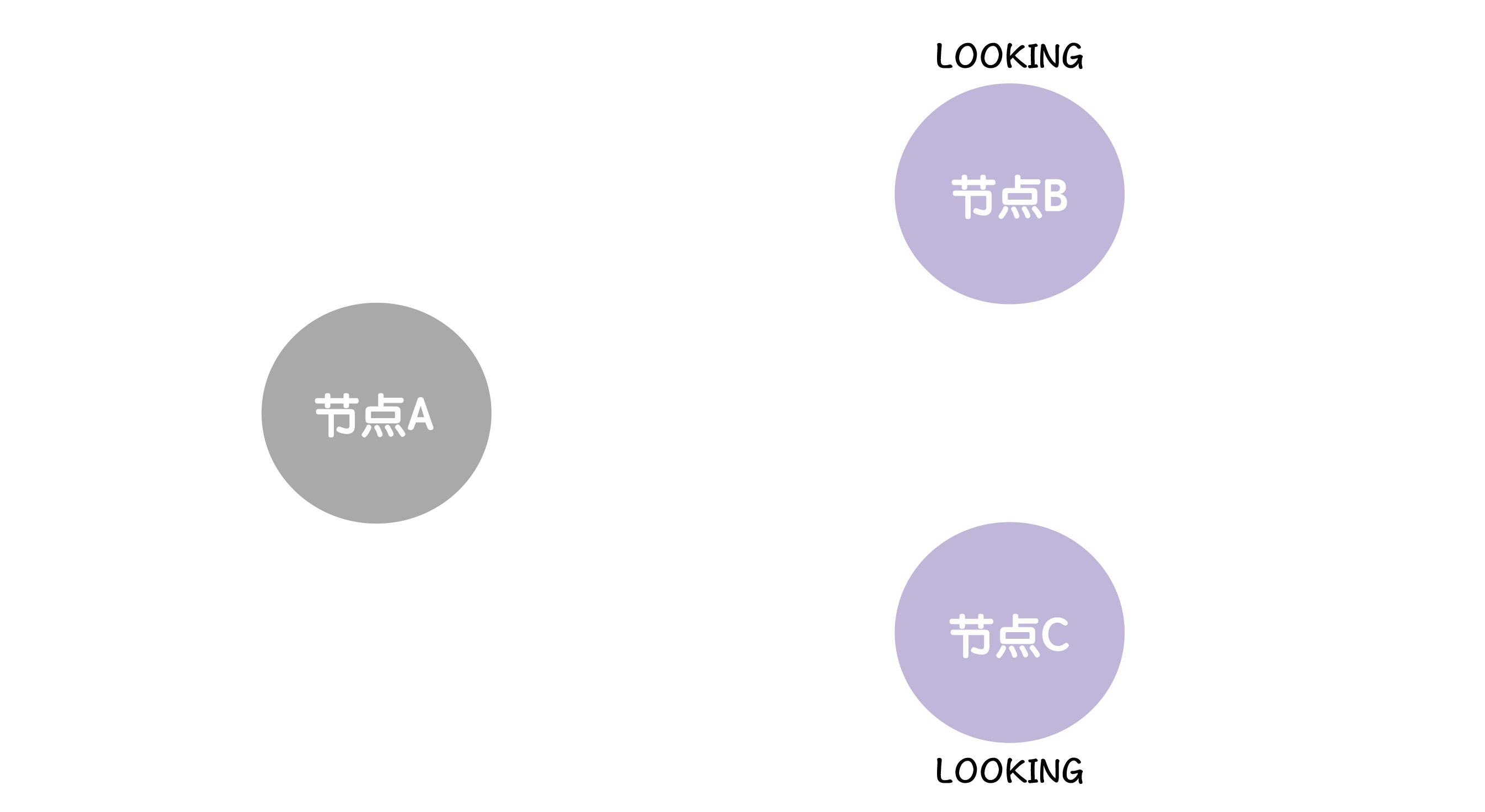
跟随者检测到领导者节点的读操作超时了,跟随者会变更节点状态,将自己的节点状态变更为LOOKING,然后发起领导者选举
我们这里为了模拟,假设B C同时发起选举
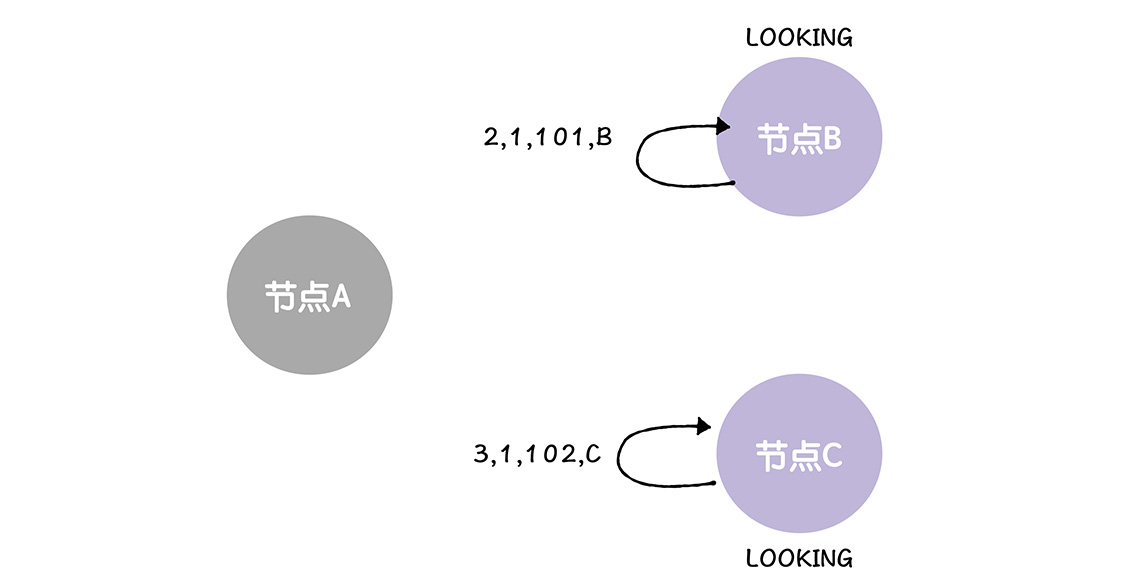
每个节点都会创建一张选票,这张选票首先给自己的,就是说,B C都推荐自己为领导者,分别创建了选票,<2,1,101,B > <3,1,102,C>
然后彼此进行广播
首先,节点会自己发给自己选票,然后进行自我投票,这一步必然通过
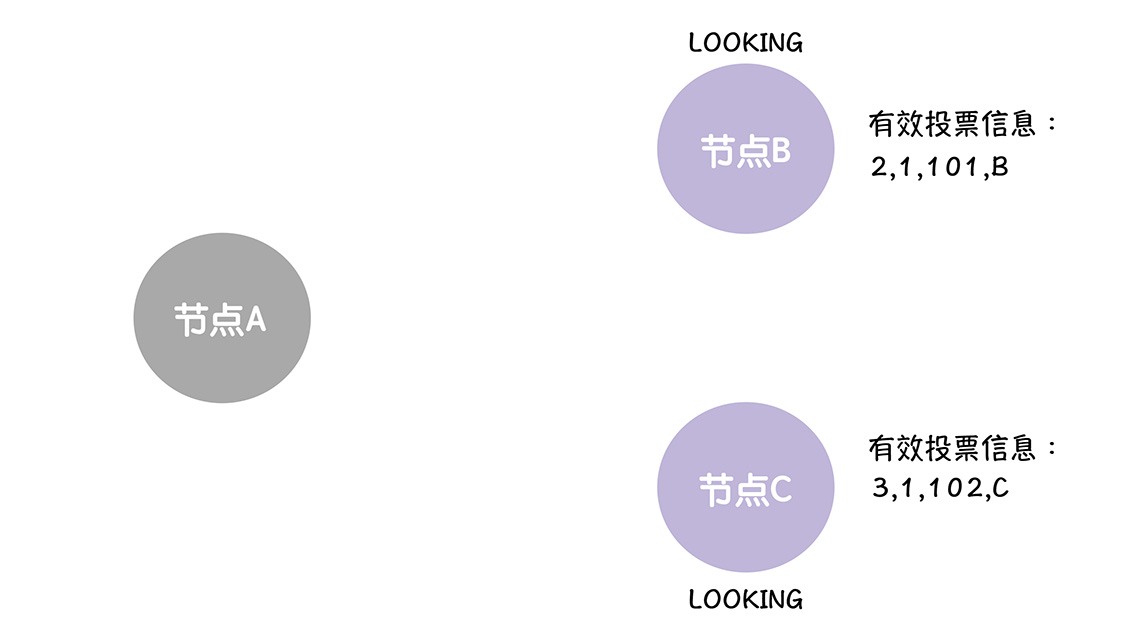
集群各个节点收到了选票后,为了选举出数据最为完整的节点,对于每一张收到的选票,都需要进行领导者的PK,PK的规则如下
首先检查任期编号,Epoch,任期编号大的节点为领导者
任期编号相同,就比较事务标识符中最大的值,值大的胜
事务标识符相同,那就比较集群ID,集群ID大的节点作为领导者
如果自己的提议失败了,就重新调整选票内容,将选票提议的领导者作为领导者
而且,收到的提议和自己的提议的领导者相同时,就不调整选票信息
接着节点B C 分别接受对方的选票,B接到来自C的选票,C收到来自B的选票
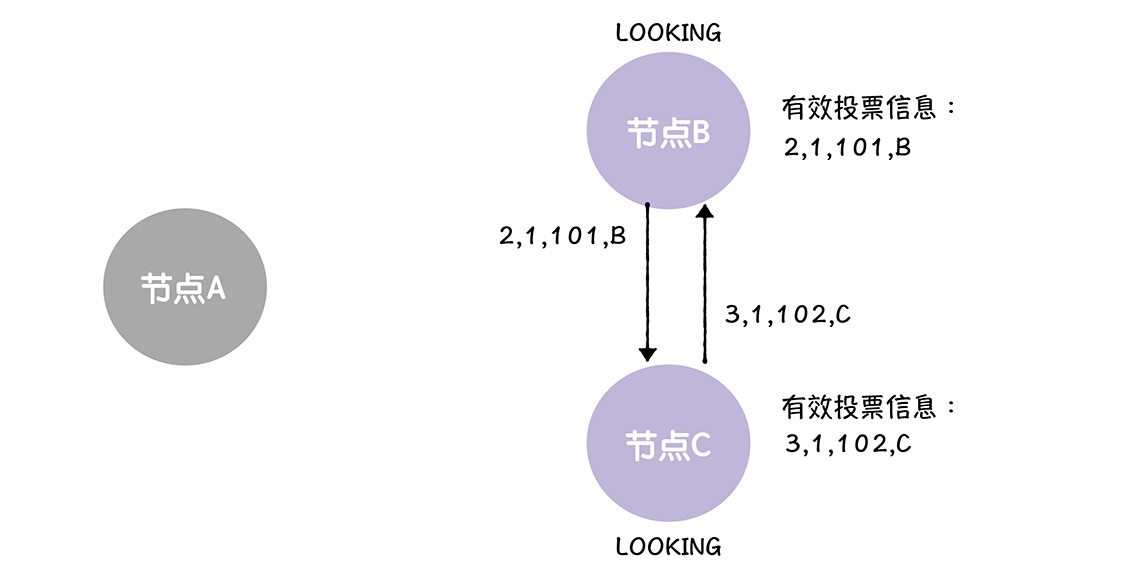
对于C来说,收到了<2,1,101,B>任期编号相同,那么比较事务标识符,因为C的事务标识符更加的大,那么C更加适合做领导者,C就不做任何的调整
对于C来说,收到了<3,1,102,C>任期编号相同,那么比较事务标识符,因为C的事务标识符更加的大,那么C更加适合做领导者,B就将自己的领导者重新设置为C,并且重新发送一次
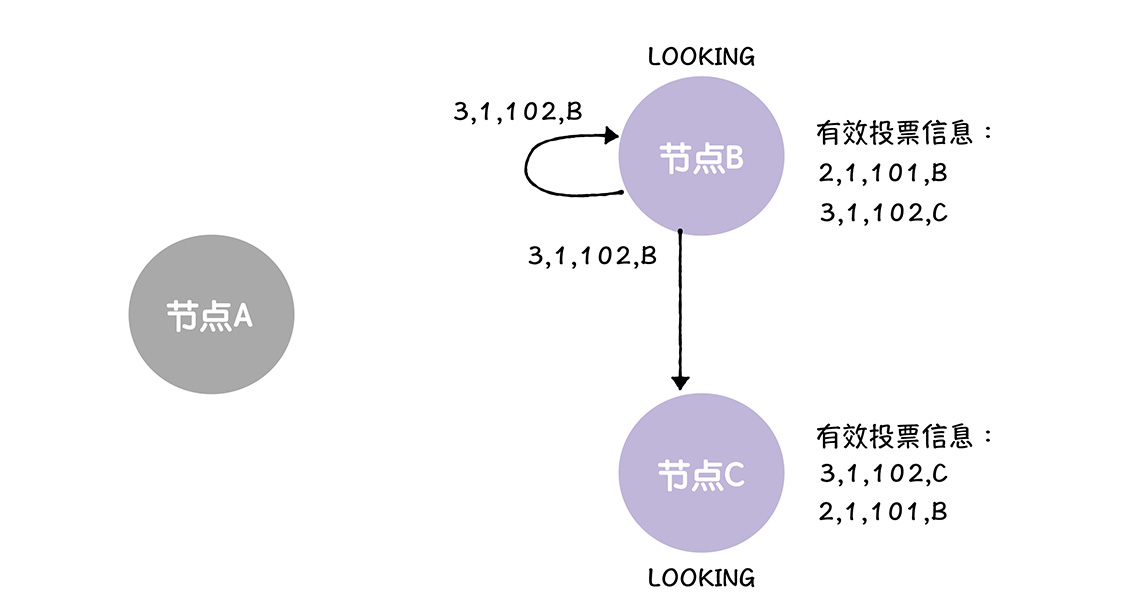
当节点B C收到来自节点B,新的选票的时候,因为这张选票 <3,1,102,B>提议的领导者,就是自己提议的领导者,所以不进行变化
最后,C赢得了大多数的选票,最后B C根据投票结果,变更节点状态,退出选举,因为C是Leader,B就是FOLLOWING
最后补充一点,逻辑时钟,会影响选举的有效性,具体来说,逻辑时钟大的节点不会接收来自值小的节点的投票,比如,节点A B 的逻辑时钟分别来自第一轮和第二轮,那么会拒绝第一轮的投票
而且领导者的选举目标是,大多数节点之中,数据最为完整的节点,事务标识符最为大的节点
接下来,我们看一下Zookeeper的源码
首先,在zookeeper之中,成员状态是QuorumPeer.java中实现的,是一个枚举
public enum ServerState{}
LOOKING,
FOLLOWING,
LEADING,
OBSERVING
}
没有定义成员身份,直接使用成员状态表示,这样也足够了
Zookeeper的领导者选举流程如下
是在FastLeaderElection.lookForLeader()中实现的
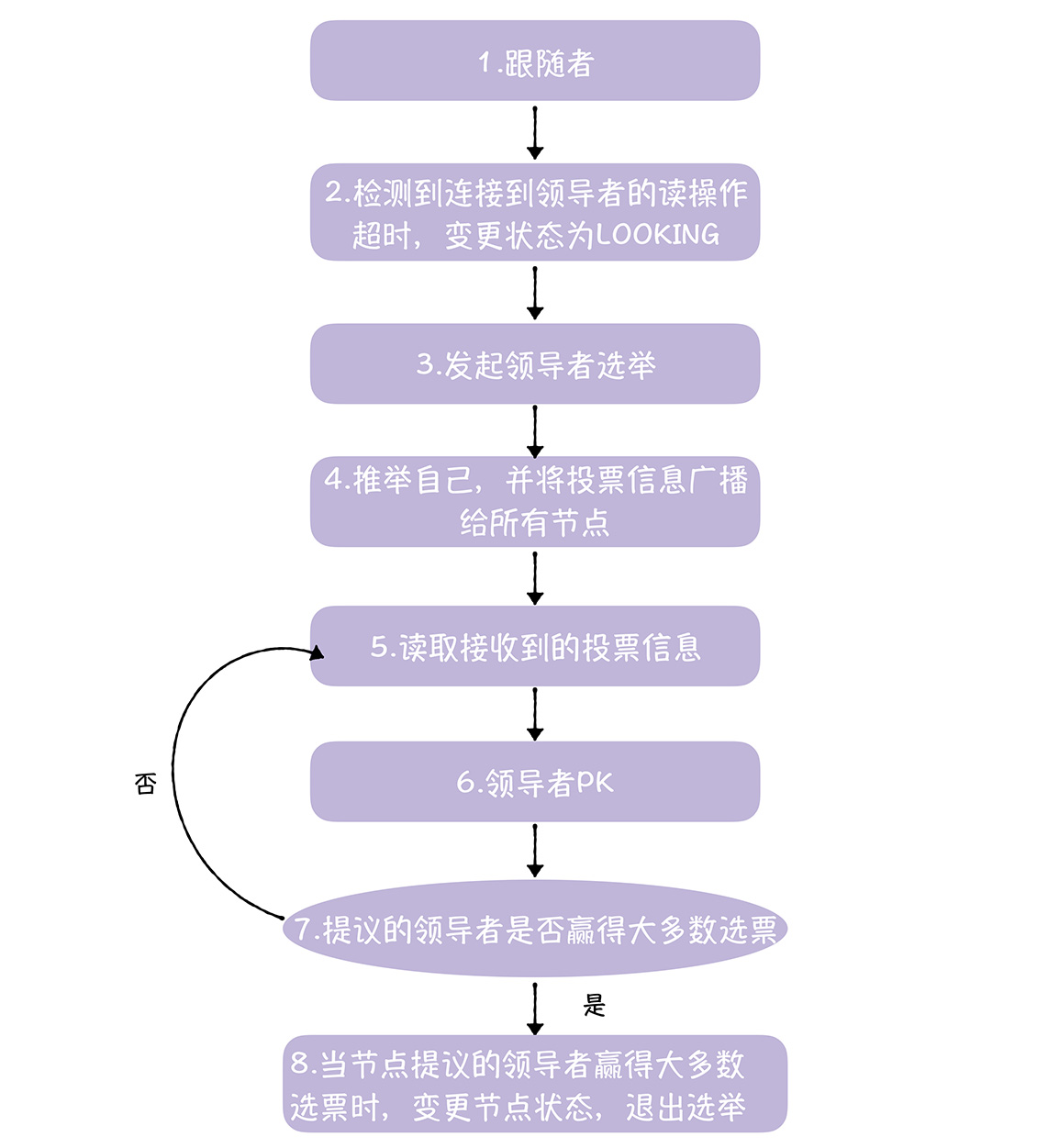
1.首先是在处于跟随者的节点,在Follower.followLeader()函数中,周期的处理数据包
| QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) { // 读取数据包 readPacket(qp); // 处理数据包 processPacket(qp); } |
然后跟随者检测到连接到领导者的读操作超时了,就会抛出异常,跳出循环体,将自己的状态更为选举状态
| public void run() {
case FOLLOWING: …… finally { // 关闭跟随者节点 follower.shutdown(); setFollower(null); // 设置状态为选举状态 updateServerState(); } break; …… } |
3,当节点处于选举状态时候,会调用makeLEStrategy().lookForLeader()函数,发起领导者选举
setCurrentVote(makeLEStrategy().lookForLeader());
4.在这个函数中,首先对逻辑时钟进行了增加操作,然后开启新一轮的领导者选举,然后创建投票提案,并进行广播
| synchronized (this) {
// 对逻辑时钟的值执行加一操作 logicalclock.incrementAndGet(); // 创建投票提案,并默认推荐自己为领导者 updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } // 广播投票信息给所有节点 sendNotifications(); |
5.节点处于选举状态,周期的从列表中读取接收到的投票信息,直到选举成功
| while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
// 从队列中读取接收到的投票信息 Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS); …… } |
6.接收到的新的投票信息,节点进行领导者PK,来判断谁更加适合当领导者,如果投票信息中节点比起自己更加适合领导者,那就替换
| else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
// 投票信息中提议的节点比自己提议的节点更适合作为领导者,更新投票信息,并推荐投票信息中提议的节点 updateProposal(n.leader, n.zxid, n.peerEpoch); // 将新的投票信息广播给所有节点 sendNotifications(); } |
7.如果自己的提议者赢了这次选举,就进行状态的变更,不然就继续从接受队列中读取新的投票信息
8.当提议的领导者获得大多数的选票的时候,根据投票的结果,跑到当前的节点的状态,是领导者还是跟随者,变更节点状态,退出选举
| if (voteSet.hasAllQuorums()) {
…… // 根据投票结果,判断并设置节点状态 setPeerState(proposedLeader, voteSet); // 退出领导者选举 Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch); leaveInstance(endVote); return endVote; …… } |
这样,我们就看了ZAB是如何选举领导者的?以及如何在Zookeeper中实现的
领导者选举的目标,是选举出大多数数据完整的节点,事务标识符最大的节点
以及选举时候,是根据什么样的顺序进行选举的
ZAB协议中,ZAB协议是通过快速领导者选举,来选举出新的领导者的,那么会出现选票会瓜分的情况吗?
必然可能啊,ZAB是一种脱胎于Multi-Paxos的算法,其本质上也是一种投票选举,那么对于这种投票选举,设置不同的选举时间是一种相对较好的选择
看到这个选举突然想到了网络环路中STP的算法解决