学习完了前面几讲,可能有一些疑问,我们通过Raft算法实现了KV存储,领导者模型简化了算法实现和共识协商,但是由于只能在领导者上进行处理,导致集群接入的性能约为单机,随着业务发展,集群的新能可能就扛不住了
如果是进行分集群,可能考虑使用Proxy层的hash处理了
哈希算法是一个办法,但是有一个明显的问题,就是需要集群的节点进行变动的时候,数据的迁移成本高的,如何解决哈希算法,数据迁移成本高的痛点呢?可以考虑使用一致哈希的问题
为了更好的理解如何通过哈希寻址实现KV的分布式集群,我们先看看一般哈希的迁移成本高的问题
我们先看下如下的一个场景
我们有着A B C三个节点(此处节点代替的就是集群)的KV服务组成,我们可以将不同的节点存放不同的KV数据
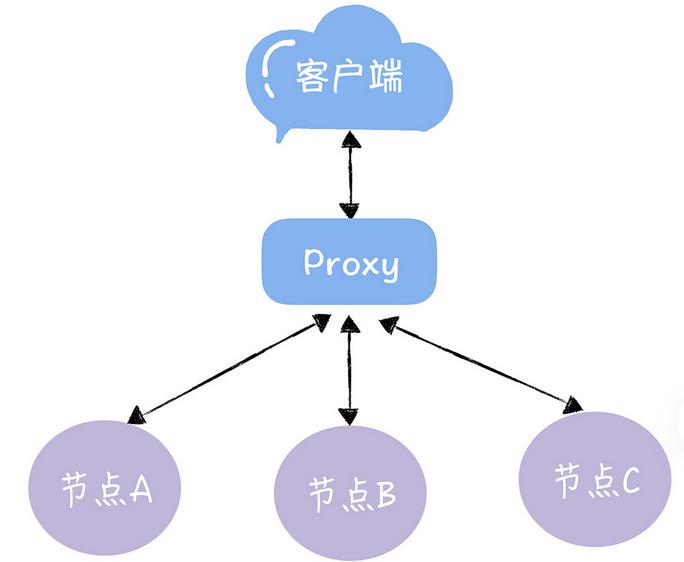
那么,如何使用哈希算法实现哈希寻址呢,有啥问题呢?
一般来说,查询时候没有啥问题
每一个key都可以找到对应的服务器,比如,查看key是key-01,计算公式 hash(key-01)%3,经过计算寻址到编号为1的服务器节点A,这都没问题
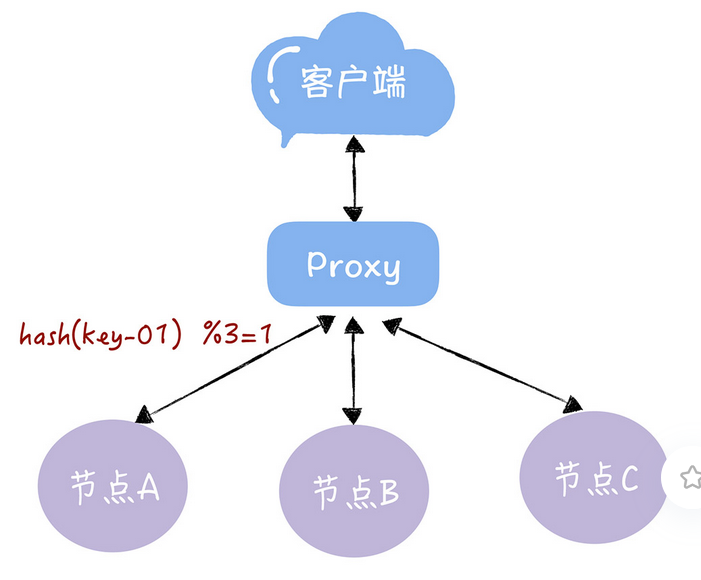
服务器的数量发生了变化,基于新的服务器数量来执行哈希算法的时候,就会出现路由寻址失败的情况,无法找到了,因为这时候的节点数量变化了,导致之前的key的取模运算,得到的值发生了变化,这时候再次查询,可能就找不到数据了,因为key-01对应的数据,存储在节点A上,而不是节点B了
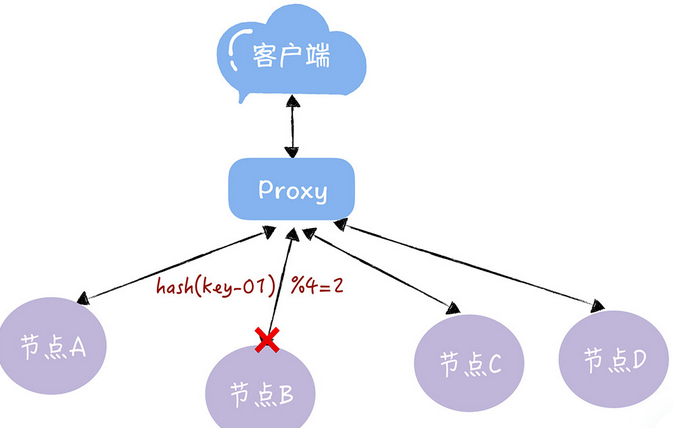
而且,我们需要下线一个服务器节点的时候,也会存在类似的找不到数据的问题,因为要解决这个问题,要进行数据迁移和节点映射,但是,一般的hash的数据迁移成本很高
对于1000万的key存储的3节点,增加一个节点,变为4节点,需要迁移75%的数据
从实例代码的输出,可以看出,迁移的成本是很高的,这在实际上是无法接受的,如何通过一致性哈希解决呢?
如何使用的一致性哈希实现哈希寻址呢?
和哈希算法不同的是,哈希算法对节点的数量进行了取模运算,而一致哈希算法是对2^32进行取模运算的,一致哈希算法,是将整个哈希空间组织成了一个虚拟的圆环,就是哈希环
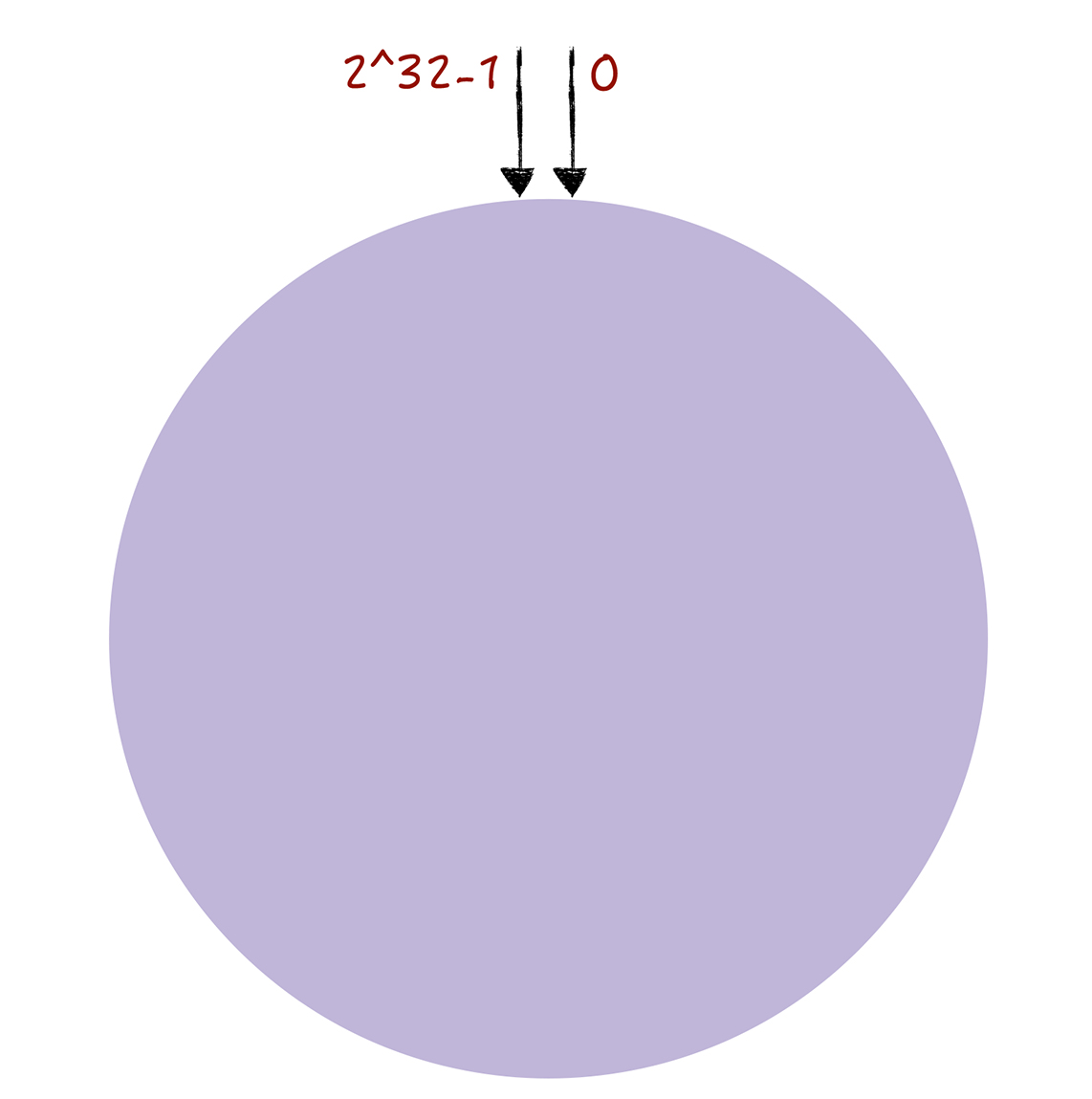
整个哈希环的空间是按照顺时针的,圆环上方的点代表0,从0右侧第一个点代表1,依次类推 2 3 4 直到2^32-1
这样的话,我们可以执行哈希算法,将服务器的节点映射到哈希环上,比如选择节点的主机名作为参数执行c-hash(),每个节点就能确定其哈希环上的位置了
对指定的key的值进行读写的时候,可以进行2步的寻址操作
首先,将key作为参数进行执行c-hash()计算哈希值,并且确认此key在环上的位置
然后这个位置按照顺时针走,遇到的第一个节点就是key对应的节点
就好比下图,有三个节点,进行结算后,节点在哈希环上的位置如下所示
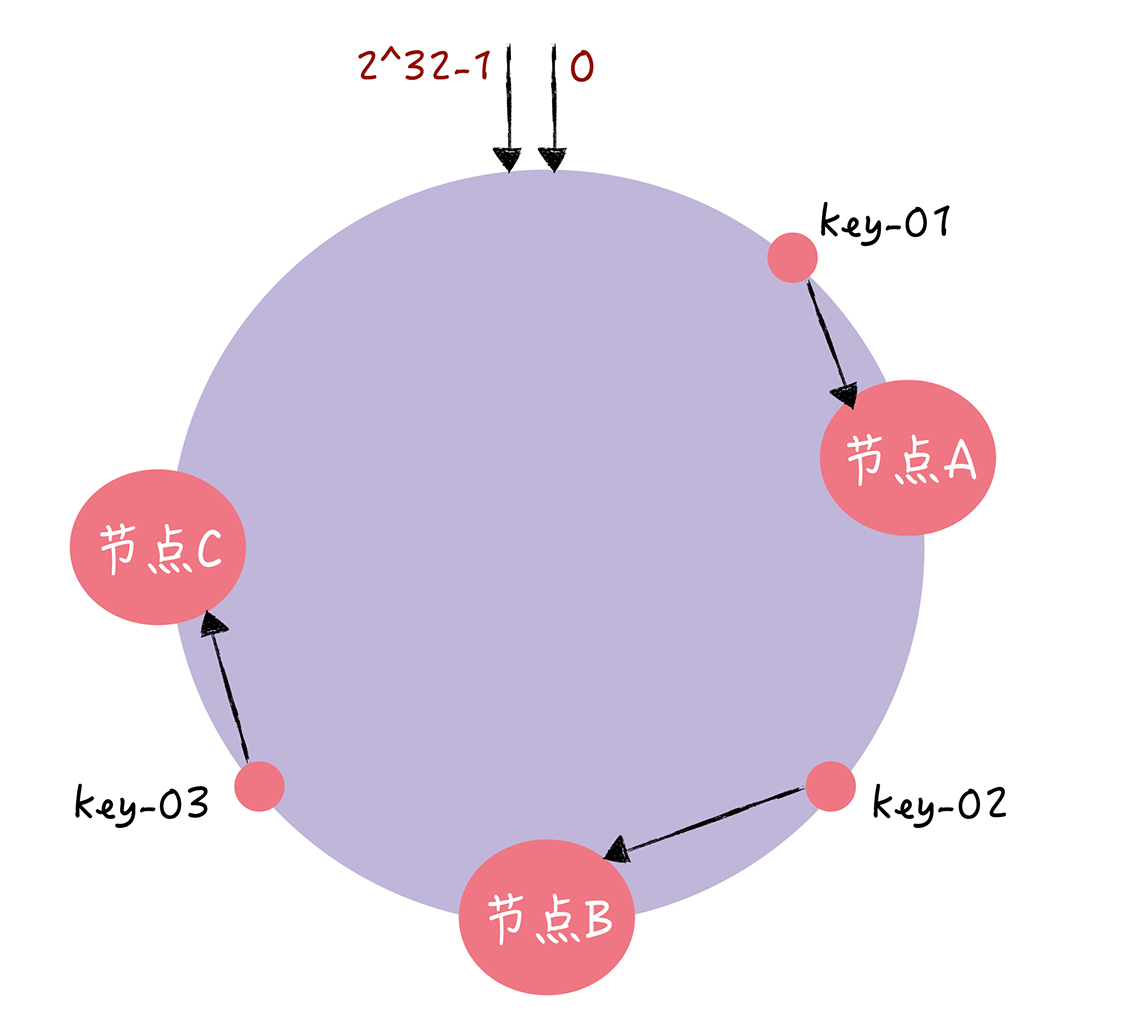
然后根据一致性哈希算法,key-1会找到节点A,key2找到节点B,这样就可以找到对应的value了
那么这个算法是如何避免哈希的节点扩容问题的呢
比如,我们现在有一个节点故障了,比如节点C故障了
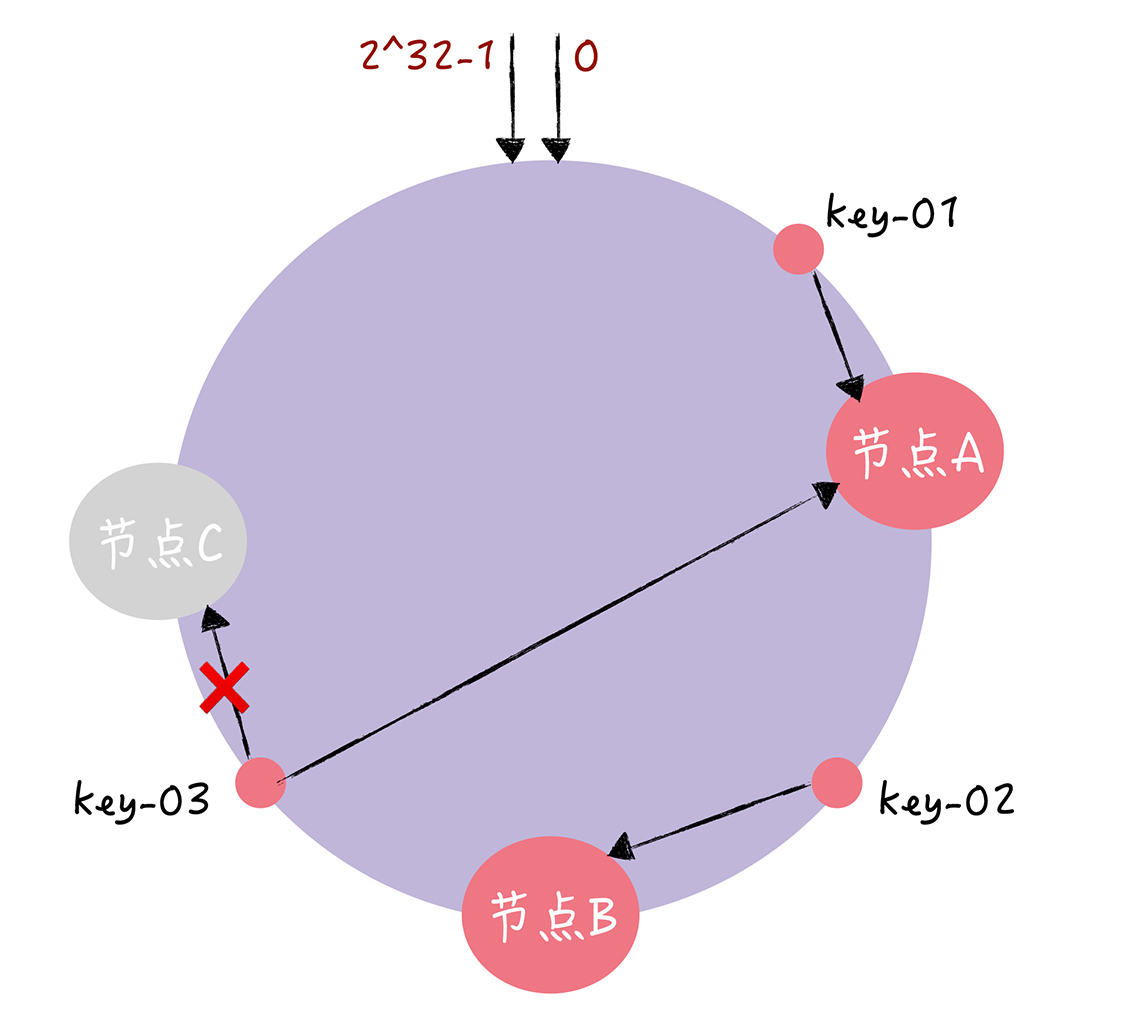
那么key-01 key-02不会受到影响,不过key-03的寻址会被定位到A,那么一致性哈希算法中,只有某个节点宕机不可用了,受影响的数据仅仅是,此和后两个节点之间的数据,
同理,如果需要扩容一个节点的话
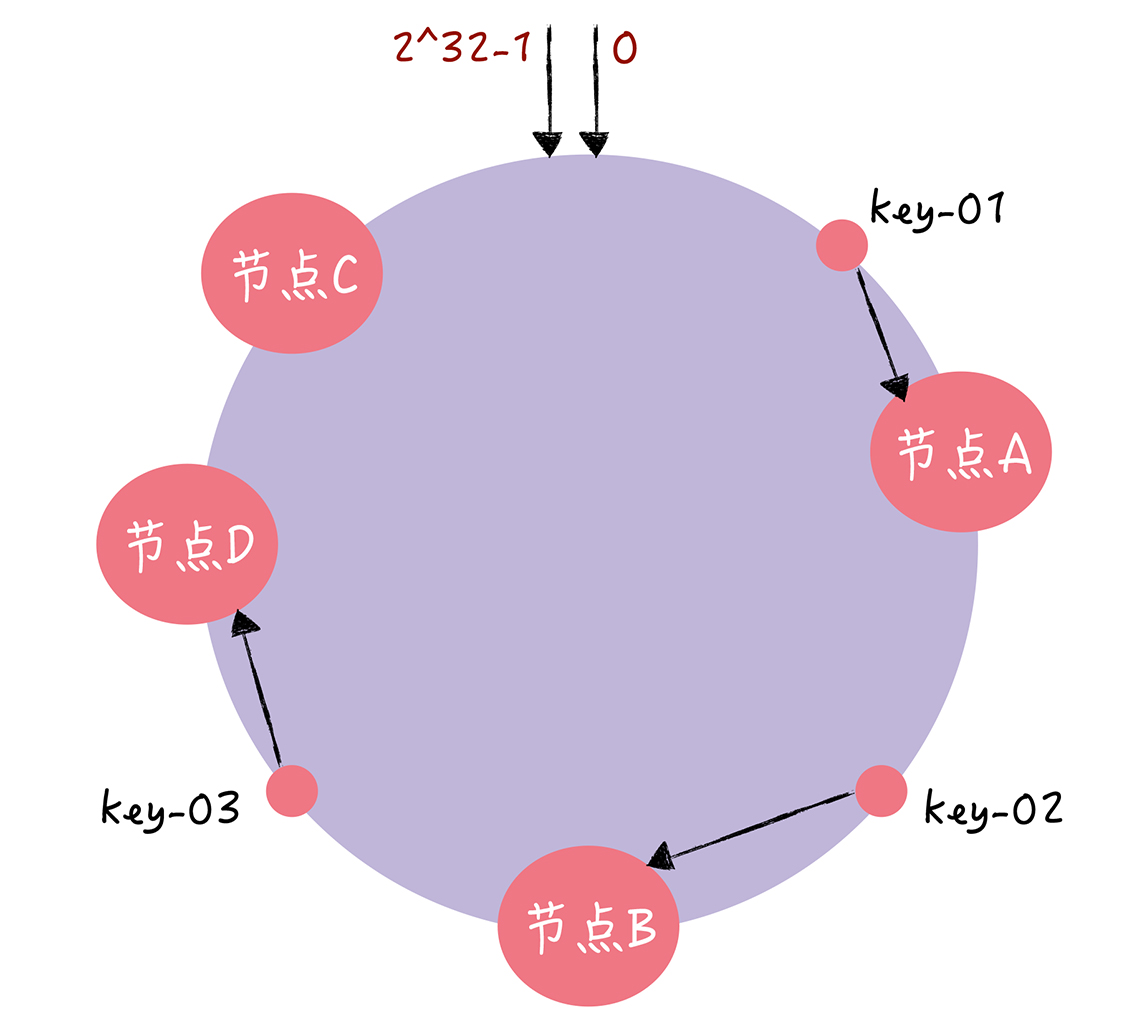
那么上面会显示出了key-01和key-02不会受到影响,而只有key-03的寻址被重新定位到新的节点D,一般来说,在一致性哈希算法中,如果增加一个节点,受到影响的,只有新节点和前一节点的数据
使用了一致性哈希去计算迁移数据的话,只需要迁移三分之一的数据量
那么一致性算法在扩容和缩容的时候,都只需要一部分数据,具有良好的扩展和容错性
而且一致性哈希还有着避免数据访问集中的解决方案,在一致哈希中,如果节点比较下,会导致因节点分布不均匀而数据访问不均的问题,大部分的数据访问集中某几个节点上

对于这个问题,我们可以通过虚拟节点来进行解决,
就是对于一个服务器节点,计算多个哈希值,放在多个位置上,然后将这些虚拟的节点映射到实际的节点上,可以再主机的后面加上编号,分别为Node-A-01 Node-A-02 Node-B-01 Node-B-02
Node-C-01 Node-C-02
形成多个虚拟节点
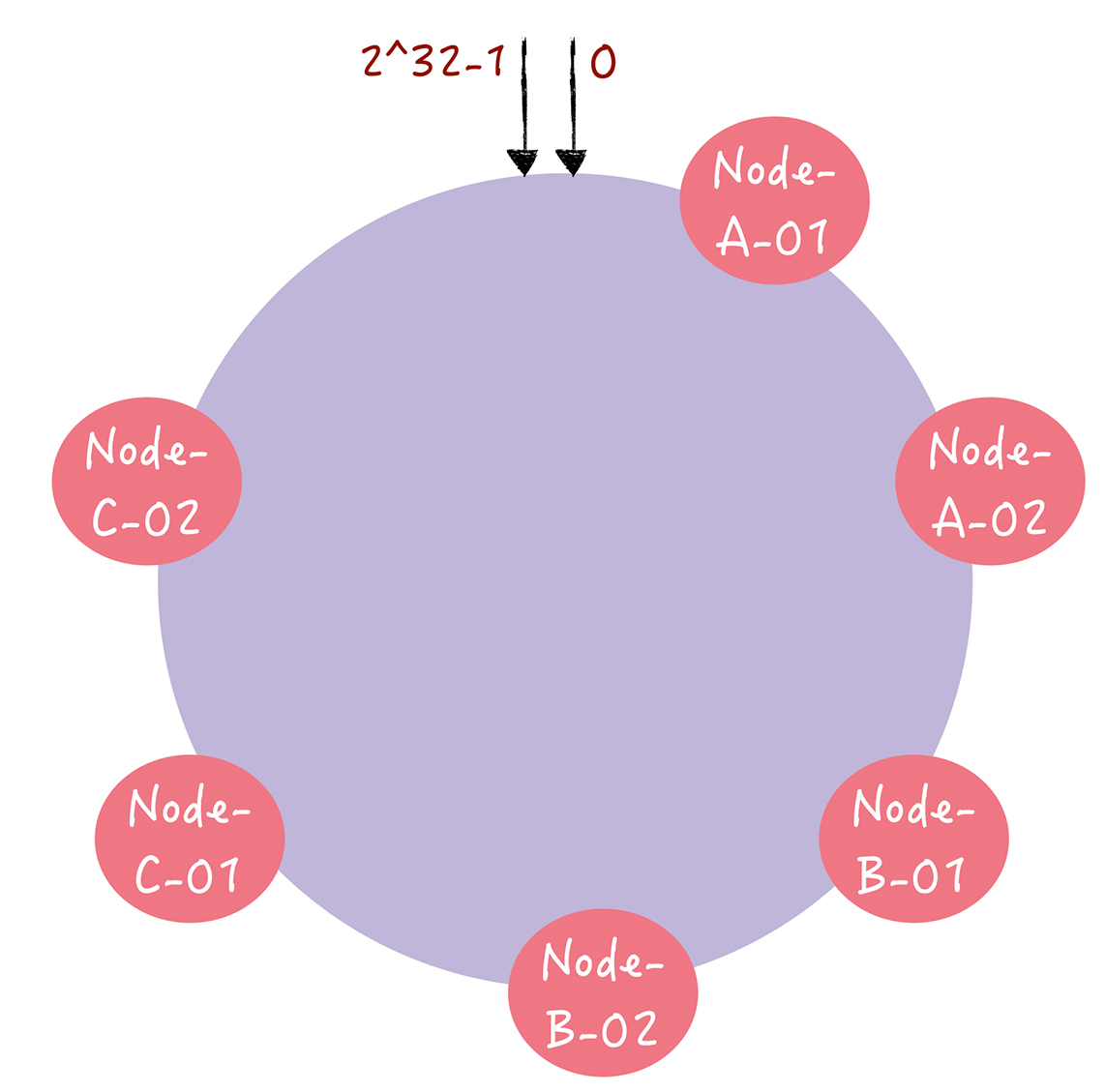
这样的话,节点在哈希环上的分布就均匀多了,如果有人访问到Node-A-01这个虚拟节点,就会被定位到节点A
而且节点数越多,迁移时候的数据就越少,和哈希中,迁移的数据多正好相反
$ go run ./hash.go -keys 10000000 -nodes 3 -new-nodes 4
74.999980%
$ go run ./hash.go -keys 10000000 -nodes 10 -new-nodes 11
90.909000%
$ go run ./consistent-hash.go -keys 10000000 -nodes 3 -new-nodes 4
24.301550%
$ go run ./consistent-hash.go -keys 10000000 -nodes 10 -new-nodes 11
6.479330%
上面我们着重讲解了一致性哈希的好处
一致性好戏是一种特殊的哈希算法,在使用一致性哈希算法后,节点增减的变化只影响到部分数据的路由寻址,只需要迁移部分数据就可以实现集群的稳定性
节点数比较少的时候,会出现节点在哈希环上不均匀的情况,这样每个节点实际占据的环的区间不一致,导致业务对节点访问冷热不均,这个问题可以通过引入更多的虚拟节点解决
Raft集群具有容错能力,能够容忍少数的节点故障,多个Raft集群构成的KV系统中,如何设计一致性哈希,实现当某个集群的领导者节点出现故障,能够选举出新的领导者,整个系统稳定运行的呢?
这个影响并不在于领导者的选举问题啊,而是数据能否再次获得问题,一个领导者节点挂了,能不能再拿到这个领导者在整个一致性hash系统的数据,如果能够拿到,那就相当于一次细微的迁移,并不会对整个系统的稳定运行产生什么影响,不能拿到,那才是真正的出问题了