日常工作中,可能存在服务器故障的问题,这是需要替换集群中的服务器,对于这种问题,集群中的服务器的数量是会变化的
Raft是共识算法,对集群成员变更的,会不会因为集群分裂,出现2个领导者?
Raft的领导者选举,建立在了大多数的基础上,当成员变更的时候,集群的成员发生了变化,就可能出现有两个小集群同时存在的可能性,破坏了Raft集群的领导者唯一性
关于成员变更,不仅仅是Raft算法中比较难以理解的一部分,一开始都是使用的联合共识去进行的Raft成员变更,后来提出了一种改进的方法,单节点变更
我们了解下这个单节点变更的原理,如何借由Raft实现的
首先说下集群中的配置问题,首先说什么是配置,就是在集群中各个节点地址信息的集合,比如节点A B C组成的集群,集群的配置就是[A,B,C]集合
假设我们有一个节点A B C 的Raft集群,需要增加两个副本数,扩展为A B C D E 5个节点组成的新集群:
Raft算法如何保障集群配置变更的时候,集群能够稳定运行,不会出现多个领导者的呢?
首先说,可能出现多个领导者的原因,就是可能出现2个领导者,在进行变更的时候,AB 和 CDE进行了分裂,AB成为了一个大多数,CDE成为了一个大多数,那么节点C和节点D E中的新节点可能会选举出新的领导者,导致出现了2个领导者的问题
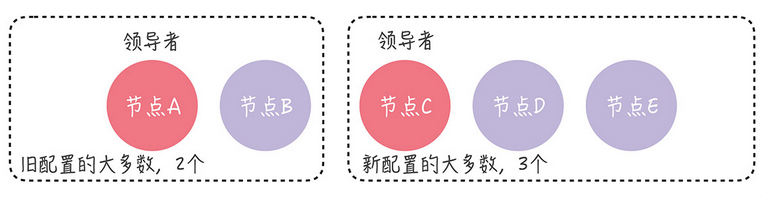
这种情况,就违背了领导者的唯一性的原则,影响到了集群的稳定运行
简单的处理方式就是,在启动集群的时候,因为配置是一定的,不会发生成员分裂的情况,于是Raft可以在集群新增的时候,先将整个集群关闭,再重新的启动集群
但是,如果每次变更都需要重启的话,势必会导致一定时间的集群服务不可用,太影响用户体验了
于是引出了单节点变更的方式
如何通过单节点变更来解决问题呢?
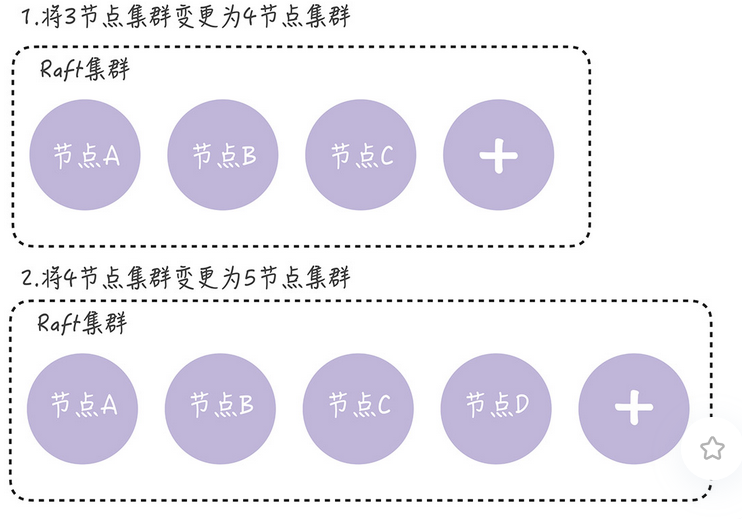
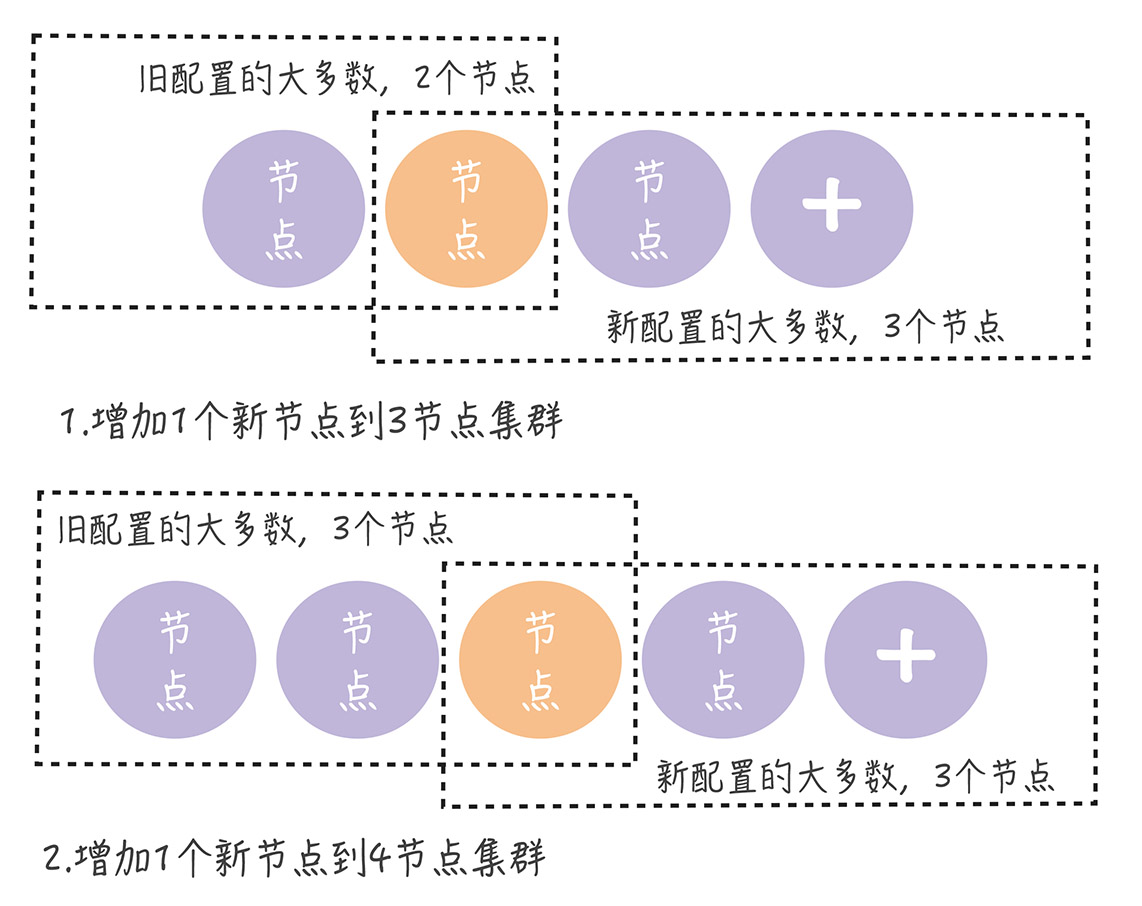
单节点变更,就是一次变更一个节点实现成员变更,如果需要变更多个节点,需要执行多次的单节点的变更,如果需要将3节点扩容到5节点,需要执行两次单节点的变更,先变更为4节点,在变更为5节点
我们假设节点A是领导者
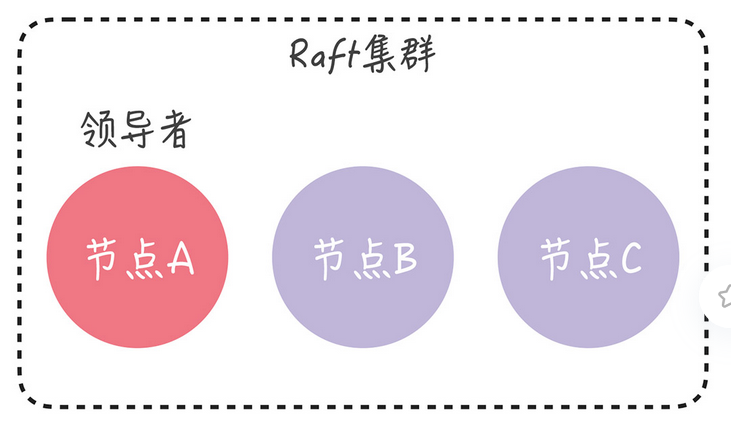
目前的集群配置是[A,B,C],我们会先向集群中加入节点B,这就变成[ A,B,C,D]
整体的加入流程如下
领导者 节点A 向 新节点D 同步数据
然后节点A 将新的配置 [A,B,C,D]作为一个日志项,复制到新配置中所有节点,然后将新的配置日志项应用到本地状态机,完成单节点变更
那么从四到五的时候,也是如此
整体的步骤如下
领导者向着新节点同步数据
领导者将新的配置作为日志项,进行复制到每一个节点上,然后应用到本地机上,完成单节点的变更
而且大多数情况下,无论旧的集群配置如何组成,旧配置的大多数和新配置的大多数都有一个节点会重合
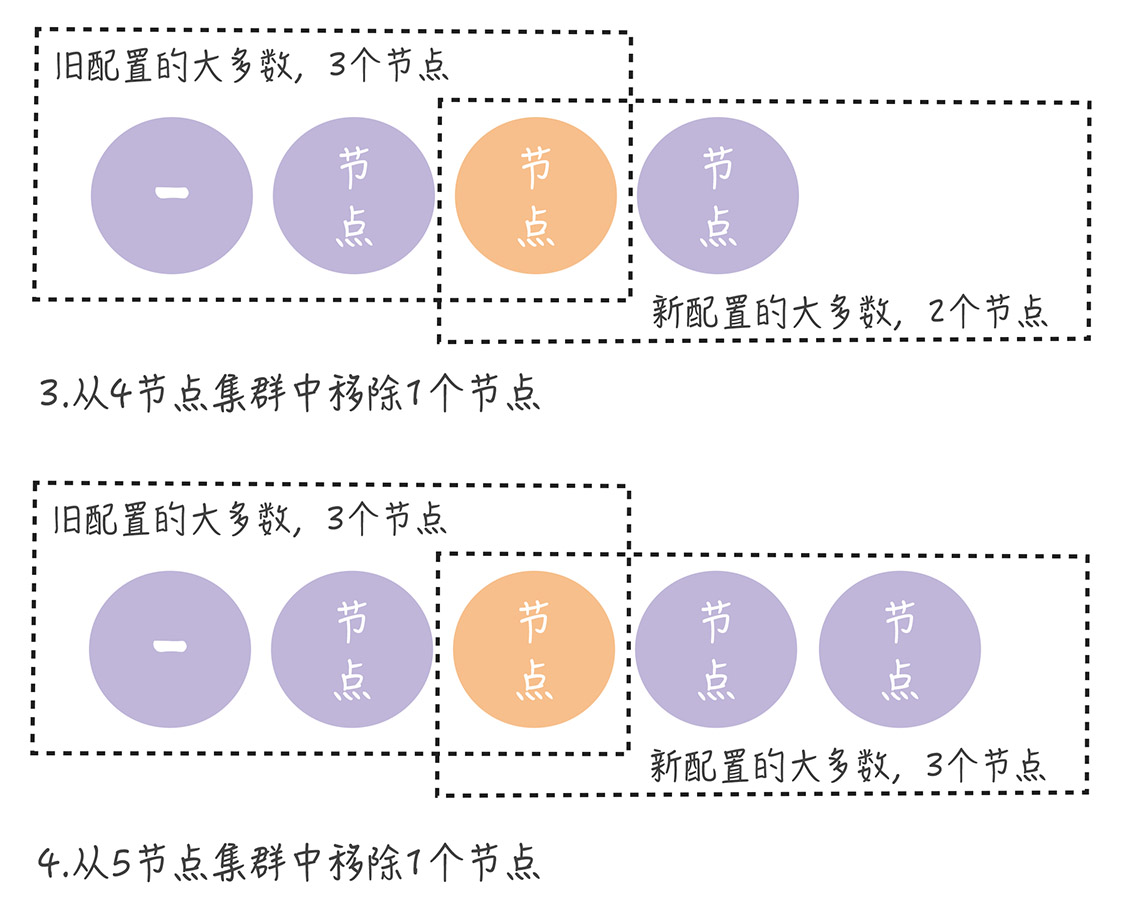
我们必须要保证有一个重叠,
那么只有在分区错误,节点故障的时候,并发执行单节点变更,才能出现一次单节点变更还没完成,新的单节点还在执行,导致集群出现脑裂的问题
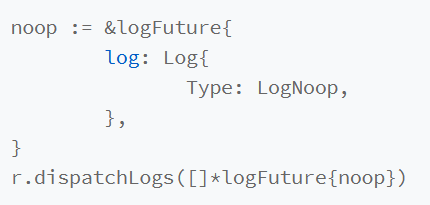
那么出现这种问题,可以考虑先创建一个NO_OP的日志项,当领导者将NO_OP日志项应用后,在进行执行成员变更就可以了
这样,就实现了单节点变更的方式,当然,还有一种已经被淘汰的联合共识的方式,这种比较难以实现,很少被Raft的实现采用,所以就不多说了
而且说一下本章的重点,成员变更的时候,因为可能存在新旧两个配置的大多数,破坏了Raft的唯一性原则
于是出现了联合共识和单节点变更的解决方案
单节点:一次变更一个节点,避免出现同时存在就配置和新配置的两个大多数的场景,避免了脑裂
联合共识,因为很复杂,不好实现,所以一般不会被采用,都是单节点变更的手段
最后总结一下,Raft并不是一致性的算法,而是一种共识算法,一种Multi-Paxos算法的实现,而Raft可以容忍少数节点的故障,虽然Raft可以实现强一致性,但需要客户端的支持,而且一般支持不同级别的一致性实现,在Consul中支持三种一致性的实现
default:客户端访问领导者节点执行读操作,领导者确认自己处于稳定状态时候,就直接返回本地数据给客户端,但是可能存在一种情况,就是领导者发生了网络错误,已经不再是领导者了,但是还是自以为自己是领导者,直接返回本地的数据了
consistent:客户端访问领导者节点执行读操作,领导者会和大多数节点确认过自己是领导者后,才会返回本地数据给客户端,不然就返回错误数据
stale:会从任意节点读取数据,不限于领导者,但是可能读到旧的数据
一般来说,default和consistent就够了,保证每次都读到最新值,可以帮助我们去实现幂等的操作,我们可以使用一个编号ID来标识一个操作是否执行,一旦执行过了,就可以下次再次执行就不再执行,防止了操作的重复执行
Raft可以保证了强一致性的问题,比如时序性数据库的其中配置中心,名字服务,和时序服务库的META节点,就采用了Raft算法,在设计 时序数据库的DATA节点一致性的时候,就基于水平扩展,性能和数据完整性考虑,没采用Raft算法,而是NWR,具有了失败重传,反熵等机制,满足了业务需求
课后斯安靠
强领导者会限制集群的写性能,如何突破呢?
可以参考MySQL的分库分表,利用一个字段,进行相关的集群拆分操作,然后在不同集群上进行读和写操作