我们来说一下Gossip这个协议,顾名思义,这个协议就好比流言蜚语,利用一种强传染性的方式,将信息进行传播,在一定的时间内,将系统中所有的节点数据进行统一
为了吃透Gossip协议,需要知道支持这个协议的三板斧,也就是Gossip协议的核心内容,最终一致性的常用三种实现方式
这三板斧分别是 直接邮寄, 反熵, 谣言传播
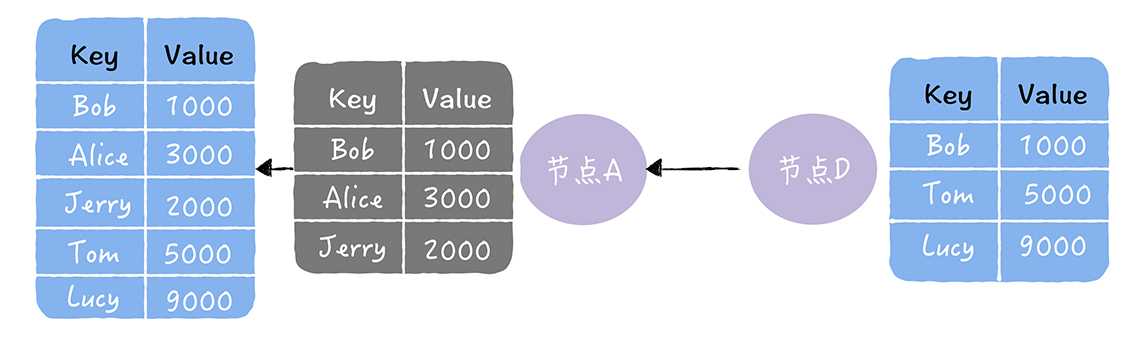
直接邮寄(Direct Mail) 直接发送更新的数据,当数据发送失败的时候,将数据缓存下来,然后重传,下面就是直接邮寄的一张图,下面可以看出节点A直接将数据发给了节点B D
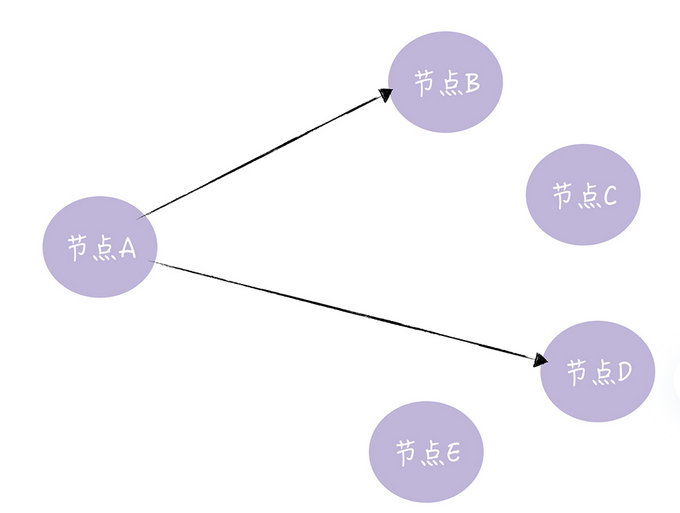
直接邮寄实现起来容易,数据同步很及时,但是如果缓存队列满了,丢了数据,也是可能的,只采用直接邮寄是无法实现最终一致性的
那么就是第二板斧,就是反熵,反熵就是通过异步修复实现最终一致性的手段,常见的最终一致性的系统,就实现了反熵功能
反熵就是集群中的节点,每隔一段时间就随机选择其他的节点,然后互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性
反熵中的集群节点,每隔一段时间就随机选择某个其他的节点,然后互相交换彼此的数据来消除两者之间的差异,实现数据的最终一致性
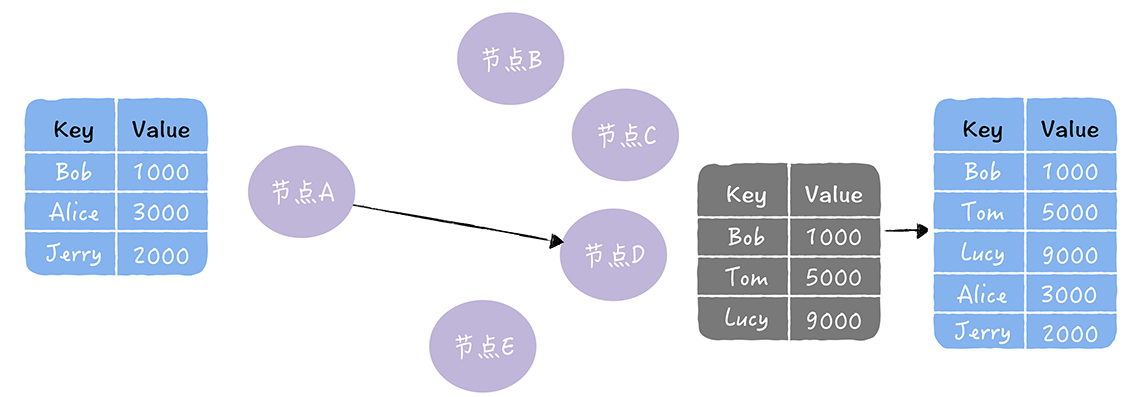
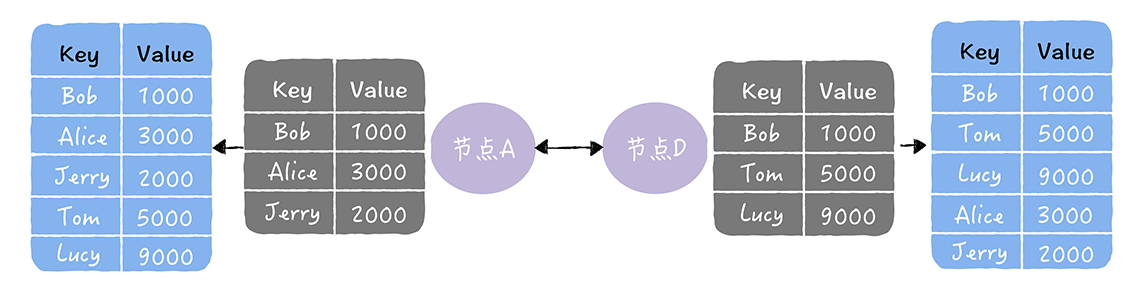
节点A通过反熵的方式,修复了节点D中缺失的数据
而且,反熵中,具有推 拉 推拉三种方式,我们通过修复如下的数据副本不一致,来进行了解
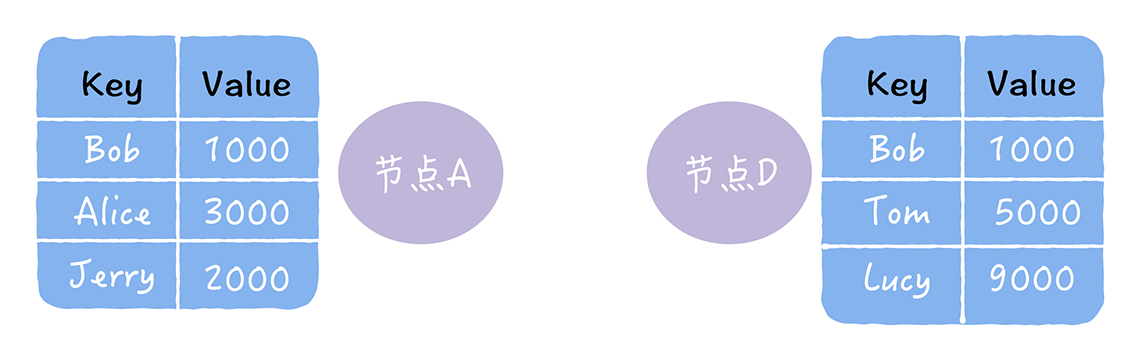
.
1,推:将自己的所有副本数据,推给对方,修复对方副本之中的熵
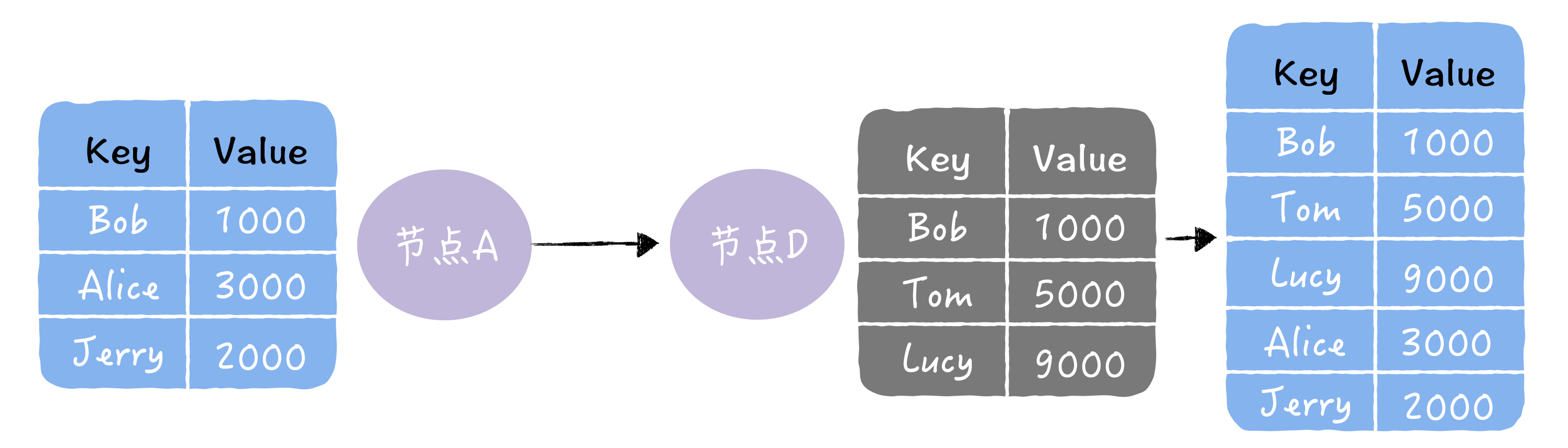
2.拉:拉取对方的所有副本数据,修复自己副本中的熵:
3.推拉,同时修复自己副本和对方副本中的熵
反熵是一个奇怪的名词,但是反熵中的熵可以理解为混乱度,反熵就是降低对应的混乱度,提高节点间的数据的相似度
不过,反熵需要节点之间两量交换并对比自己的所有数据,所以通讯成本很高,不建议在实际场景之中频繁的使用反熵,可以考虑使用校验等机制,降低对比所需的数据量和通讯消息
反熵很实用,但是执行反熵的时候,相关的节点都是已知的,而且节点不能数量过多,如果是一个动态变化或者节点数比较多的分布式环境,反熵就不适用了,这时候就是第三板斧
谣言传播
广泛的传播谣言,当一个节点有了新的数据,这个节点就会变成活跃状态,周期性联系其他节点向其发送新数据,知道所有的节点都有对应的数据
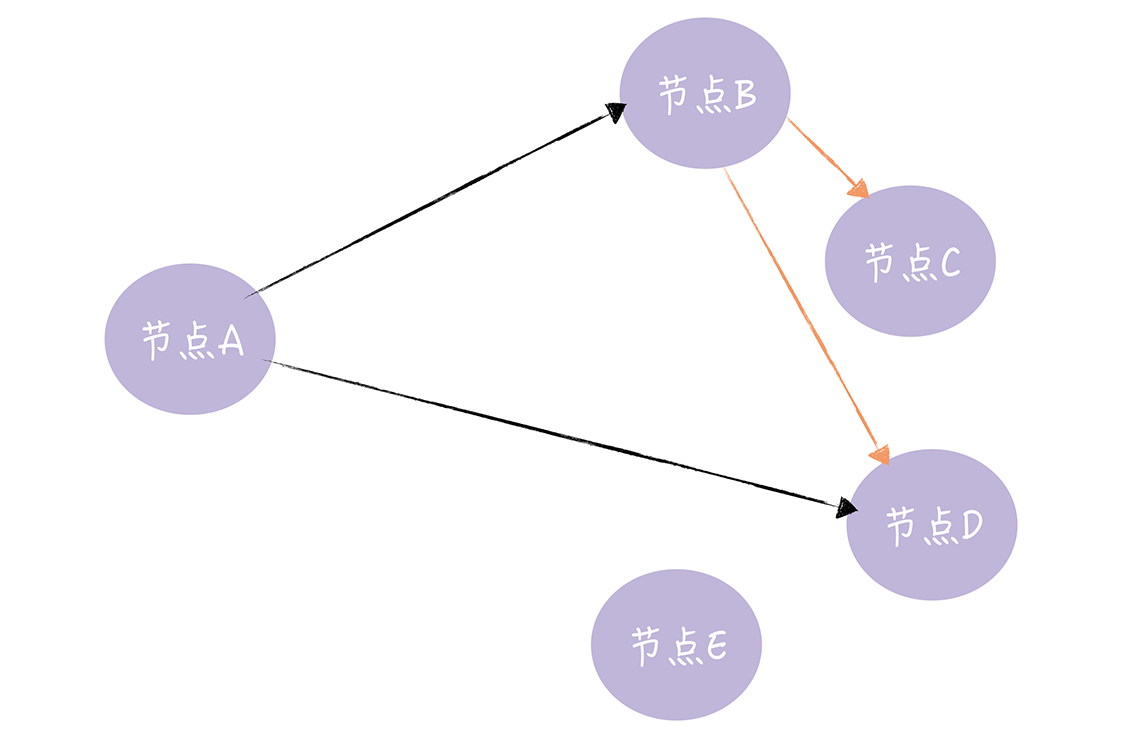
B节点收到了新的数据,会变成活跃的节点,然后一直发送新的数据给C D,这样就非常适合动态变化的分布式系统
如何使用Anti-entropy实现最终一致性
我们实现最终一致性,可以采用反熵的机制,那么如何在实际生产汇总运用反熵的机制呢?
一份数据副本可以分为多个分片,实现了数据分片
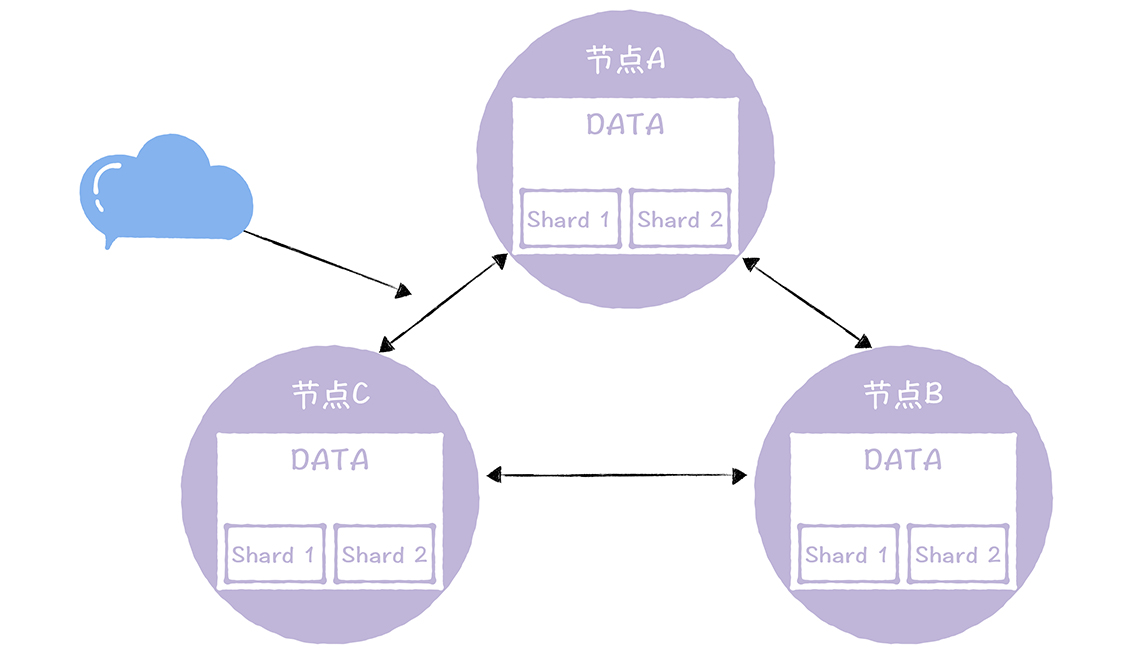
反熵的目标是保证每个分片的数据一致性,无差异,节点A具有分片Shard1和Shard2,而且,节点A的Shard1和Shard2和节点B的Shard1和Shard2,这些是一样的
可能存在问题在于上面呢?
将数据缺失,分为了两种情况
缺失分片,某个节点上整个分片都丢失了
节点之间的分片不一致,分片都存在,但是里面数据不一致,有数据缺失的问题
第一种,需要我们进行拷贝分片数据
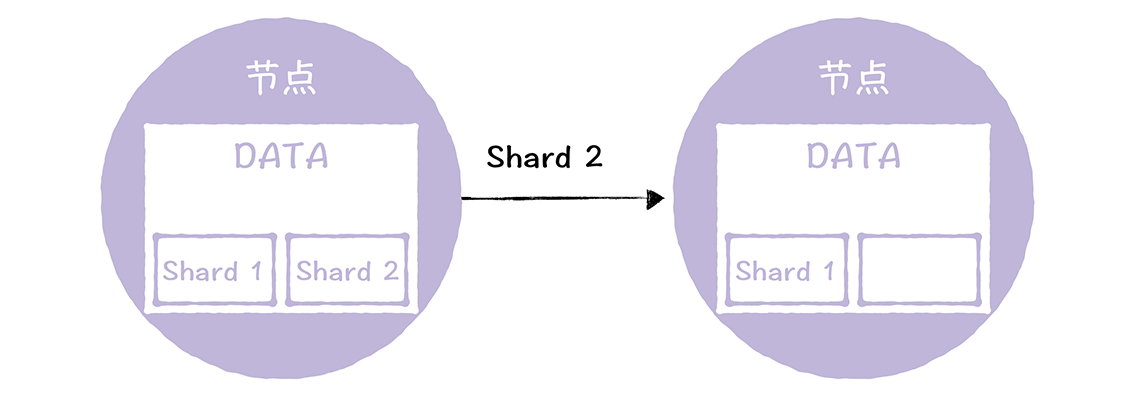
第二种,需要我们进行,进行一种近乎闭环的流程去进行修复
按照一定的顺序进行修复数据差异,随机选择一个节点,然后循环的修复,每个节点自己生成自己有,下一个没有的差异数据,进行通信修复
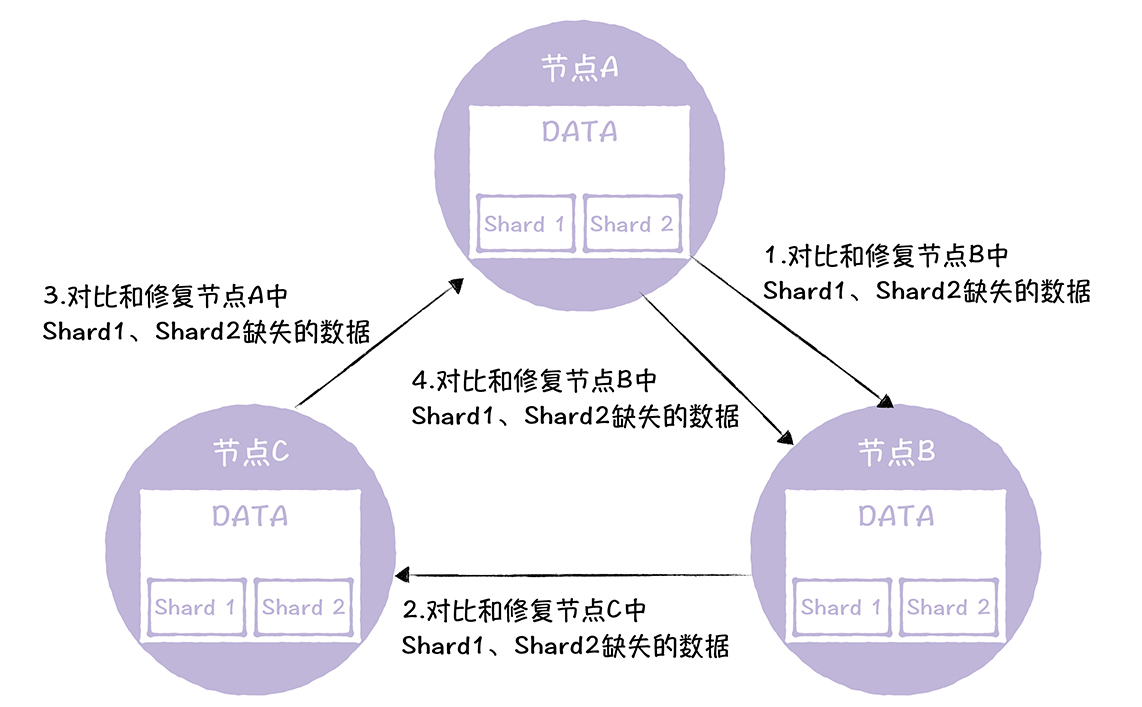
数据修复的起始节点为A,数据修复是按照顺时针顺序,循环修复的,最后节点A又对节点B的数据执行了一次数据修复操作,这样C 中的数据又同步到了节点B上
这样,我们利用一个闭环的流程,一次性的修复了所有节点的数据不一致的问题
而且,我们要注意问题,就是反熵需要进行一致性的对比,很消耗系统性能,随意对于是否开启反熵,已经反熵的检测时间间隔,做成可配置的,可以在不同的场景之中按需使用
本章我们主要说了Gossip协议,如何在实际的系统中实现反熵
作为一种异步修复,实现最终一致性的协议,我们使用的很广,比如Dynamo,InfluxDB,在实现最终一致性的时候,先考虑反熵
因为谣言具有传播性,一个节点传给了另一个节点,另一个节点又具有传播者的特性,传给其他节点,非常适合动态变化的分布式系统
在实际开发中,为了保底,一般直接邮寄的方式是需要实现的,然后对于节点已知的情景,反熵可以定时的刷新,而节点经常动态变化,可以采用谣言传播的方式,进行更新数据,实现最终一致性
课后思考
使用反熵完成最终一致性,需要通过一致性来进行检查副本的差异,但是每次做一致性检测都数据对比的话,是比较消耗性能的,如何降低性能消耗呢?
看了大佬们的留言后,我这里提议中,就是先利用序号或者哈希等方式,计算一个总体的值,利用这个值来判断反熵的是否启动.