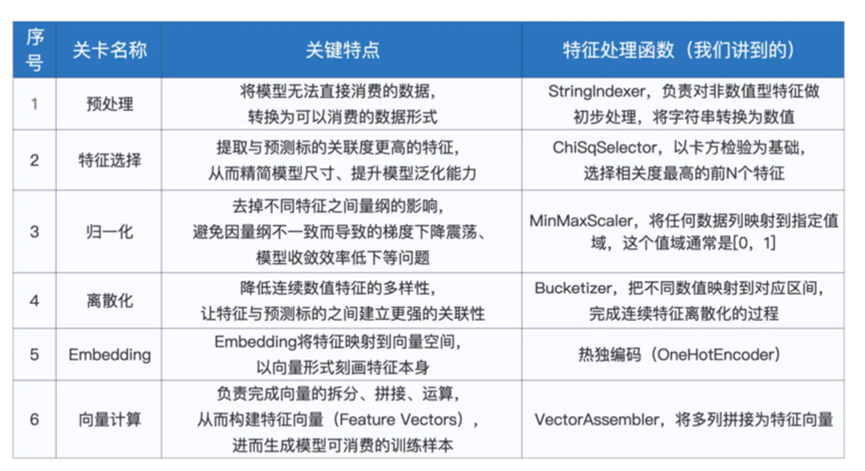
特征工程相关函数
上一次我们简单构建了一个线性回归模型,虽然最后得到的预测效果并不很好
这一次,我们仍然讲解这个房价预测的模型,不过我们会在优化上面的计算过程中,展示不同的特征处理函数
这些不同的函数可以大致分类为
预处理
特征选择
归一化
离散化
Embedding
向量计算
首先我们大致说下特征工程的概念
上一次我们的模型之使用了四个特征,分别是LotArea,GrLivArea,TotalBsmtSF 以及 GarageArea
而上次的预测并不符合我们的预期,其主要原因就是我们选取的特征字段不对,买房者在买房的时候,绝对不会只考虑这四个属性
我们就需要考虑更多的属性,对应的流程就是先找到这些决定性的因素,然后再使用权重向量来量化不同因素对房价的影响。
首先是预处理
StringIndexer,负责将数据中非数值字段转换为数值字段,比如使用StringIndexer,可以将车库类型字段的字符串转换为数字

首先实例化StringIndexr对象
然后通过setInputCol和setOutputCol来指定输入输出列
最后调用fit和transform函数,完成转换
这里我们拿一个DataFrame测试
import org.apache.spark.sql.DataFrame 2
// 这里的下划线”_”是占位符,代表数据文件的根目录
val rootPath: String = _
val filePath: String = s”${rootPath}/train.csv”
val sourceDataDF: DataFrame = spark.read.format(“csv”).option(“header”, true).load()
对于StringIndexr的代码
// 导入StringIndexer
import org.apache.spark.ml.feature.StringIndexer
// 所有非数值型字段,也即StringIndexer所需的“输入列”
val categoricalFields: Array[String] = Array(“MSSubClass”, “MSZoning”, “Street”)
// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列”
val indexFields: Array[String] = categoricalFields.map(_ + “Index”).toArray
// 将engineeringDF定义为var变量,后续所有的特征工程都作用在这个DataFrame之上
var engineeringDF: DataFrame = sourceDataDF
// 核心代码:循环遍历所有非数值字段,依次定义StringIndexer,完成字符串到数值索引的转换
for ((field, indexField) <- categoricalFields.zip(indexFields)) {
// 定义StringIndexer,指定输入列名、输出列名
val indexer = new StringIndexer()
.setInputCol(field)
.setOutputCol(indexField)
// 使用StringIndexer对原始数据做转换
engineeringDF = indexer.fit(engineeringDF).transform(engineeringDF)
// 删除掉原始的非数值字段列
engineeringDF = engineeringDF.drop(field)
}
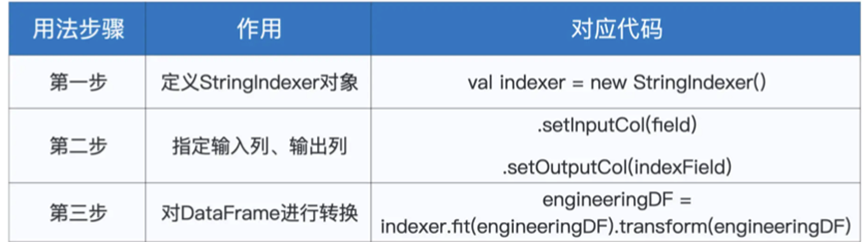
上面我们创建了几个新字段,然后利用map格式,for循环设置了input和output
之后利用fit ,transform进行了数据转换,然后删除了原始字段
最后我们多了数据列,正好就是原本数据列的对应

这样,我们以StringIndexer为例,讲述了Spark MLlib的预处理阶段,说明了特征工程的第一关
然后是第二道关卡,特征选择
我们要根据一定的标准,对特征字段进行筛选
ChiSqSelector,进行相关的字段进行筛选,在业务中,某些数据特征要高于其他的数据特征
就好比房屋格局这种数据特征要高于供暖方式这种特征,对于不同数据特征的选择,一般首先会按照相关业务经验进行筛选
当然还有一些统计手段去计算候选特征和预测标的之间的关联性,从而以量化的方式,衡量不同特征对预测标的的重要性,从而在人工之外,引入一些计算
Spark MLlib框架提供了多种特征器,背后封装了不同的检验方法,比如ChiSqSelector为例,背后就是卡方校验和卡方分布,即使暂不清楚两者的工作原理,但也不影响使用
我们来看看对应的使用流程
如果需要使用ChiSqSelector来选择数值型字段,需要进行两步走
1. 通过VectorAssembler创建特征向量
2. 基于特征想来难过,使用ChiSqSelector来完成特征选择
关于VectorAssembler我们上一次使用过,将多个数值捏合为一个特征向量
比如房屋的三个数值LotFrontage,BedroomAbvGr,KitchenAbvGr,就可以捏合为一个新的向量字段
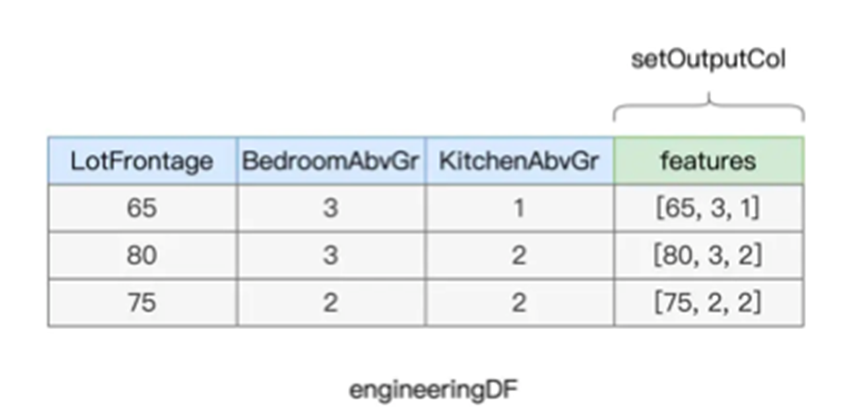
这里我们仍然使用其创建一个特征变量
val numericFields: Array[String] = Array(“LotFrontage”, “LotArea”, “MasVnrArea”,
// 预测标的字段
val labelFields: Array[String] = Array(“SalePrice”)
import org.apache.spark.sql.types.IntegerType 8
// 将所有数值型字段,转换为整型Int
for (field <- (numericFields ++ labelFields)) {
engineeringDF = engineeringDF.withColumn(s”${field}Int”,col(field).cast(IntegerType)
}
import org.apache.spark.ml.feature.VectorAssembler 15
// 所有类型为Int的数值型字段
val numericFeatures: Array[String] = numericFields.map(_ + “Int”).toArray
// 定义并初始化VectorAssembler
val assembler = new VectorAssembler()
.setInputCols(numericFeatures)
.setOutputCol(“features”)
// 在DataFrame应用VectorAssembler,生成特征向量字段”features”
engineeringDF = assembler.transform(engineeringDF)
我们创建了一个VectorAssembler实例,然后setInputCols传入所有的数值字段,然后使用setOutputCol进行输出,最后调用VectorAssembler的transform函数进行转换
之后就可以进行特征选择了
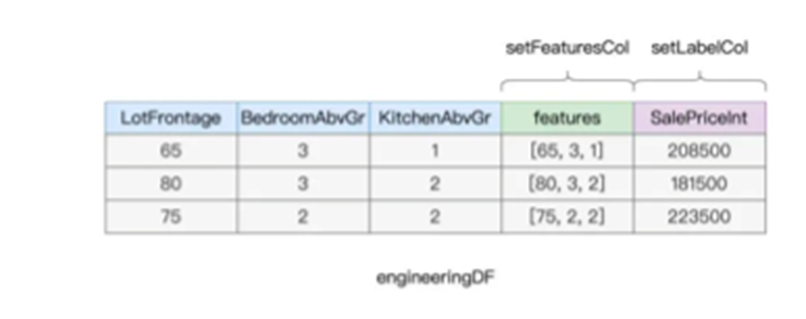
// 定义并初始化ChiSqSelector
val selector = new ChiSqSelector()
.setFeaturesCol(“features”)
.setLabelCol(“SalePriceInt”)
.setNumTopFeatures(20)
// 调用fit函数,在DataFrame之上完成卡方检验
val chiSquareModel = selector.fit(engineeringDF)
// 获取ChiSqSelector选取出来的入选特征集合(索引)
val indexs: Array[Int] = ç
import scala.collection.mutable.ArrayBuffer
val selectedFeatures: ArrayBuffer[String] = ArrayBuffer[String]() 19
// 根据特征索引值,查找数据列的原始字段名
for (index <- indexs) {
selectedFeatures += numericFields(index)
}
我们通过setFeaturesCol和setLabelCol来指定特征向量和预测标的,并且通过setNumTopFeature来声明挑选多少个特征
之后调用fit函数来进行卡方校验,得到模型之后,访问chiSquareModel.selectedFeatures
来获得入选的原始数据列
之后则是归一化
MinMaxScaler,将一组数值,统一映射到一个值域,比如将无论原本的值为1000,10000 都映射到[0,1]这个区间
对于归一化的原因,可以解释为,如果数据之间的量纲差异较大的时候,模型训练的梯度不稳定,不容易收敛,但是如果都在一个值域的时候,训练的效率必将大幅提升
Spark MLlib支持多种归一化的函数,比如StandardScaler MinMaxScaler等等,我们拿MinMaxScaler来看,对于任意的面积房屋,可以使用如下的公式进行归一化
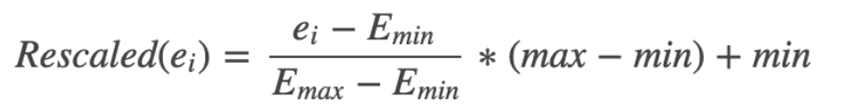
Max和min分别是上下限,利用一个区间,来映射到一个特定的范围
对于其使用方式,可以参考如下
首先创建VectorAssembler创建特征向量,然后使用MinMaxScaler完成归一化
// 所有类型为Int的数值型字段
// val numericFeatures: Array[String] = numericFields.map(_ + “Int”).toArray
// 遍历每一个数值型字段
for (field <- numericFeatures) {
// 定义并初始化VectorAssembler
val assembler = new VectorAssembler()
.setInputCols(Array(field))
.setOutputCol(s”${field}Vector”)
// 调用transform把每个字段由Int转换为Vector类型
engineeringData = assembler.transform(engineeringData)
}
我们把所有的数值型的字段,转换为了Vector向量类型
然后使用MinMaxScaler进行归一化
val vectorFields: Array[String] = numericFeatures.map(_ + “Vector”).toArray 5
// 归一化后的数据列
val scaledFields: Array[String] = vectorFields.map(_ + “Scaled”).toArray
// 循环遍历所有Vector数据列
for (vector <- vectorFields) {
// 定义并初始化MinMaxScaler
val minMaxScaler = new MinMaxScaler()
.setInputCol(vector)
.setOutputCol(s”${vector}Scaled”)
// 使用MinMaxScaler,完成Vector数据列的归一化
engineeringData = minMaxScaler.fit(engineeringData).transform(engineeringData)
}
我们分别给每一个Vector数据列条用setInput和setOutputCol创建minMaxScaler,并使用fit和transform函数来进行归一化
之后我们就有很多后缀为Scaled的数据列,其中就是归一化数据
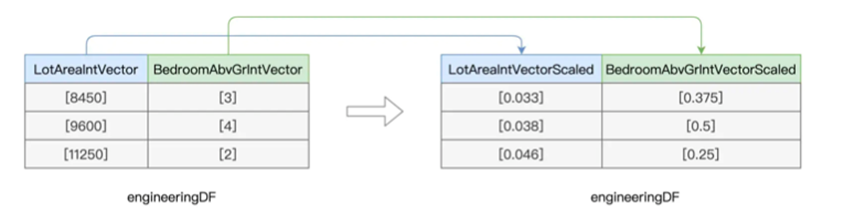
下一项是关于离散化的,离散化也是用来处理数值型字段的,用来把原本连续的数值打散,从而增加数据的多样性
至于为什么这么做,则是为了增加数据之间的区分度和内聚性,从而和预测标的产生更强的关联
就比如按照户型来分,对于两居室和三居室可能区别不大,但是一居室和两居室差别就很大了
所以我们需要进行离散化处理,增加其关联性
使用方式则和其他的特征处理函数类似
|
// 原始字段
val fieldBedroom: String = “BedroomAbvGrInt” // 包含离散化数据的目标字段 val fieldBedroomDiscrete: String = “BedroomDiscrete” // 指定离散区间,分别是[负无穷, 2]、[3, 4]和[5, 正无穷] val splits: Array[Double] = Array(Double.NegativeInfinity, 3, 5, Double.PositiveInfinity) import org.apache.spark.ml.feature.Bucketizer 9 // 定义并初始化Bucketizer val bucketizer = new Bucketizer() // 指定原始列 .setInputCol(fieldBedroom) // 指定目标列 .setOutputCol(fieldBedroomDiscrete) // 指定离散区间 .setSplits(splits) // 调用transform完成离散化转换 engineeringData = bucketizer.transform(engineeringData) |
我们创建了特征处理函数,然后指定了离散区间,以及对应的列,最后调用了transform进行转换,转换后的数据如下
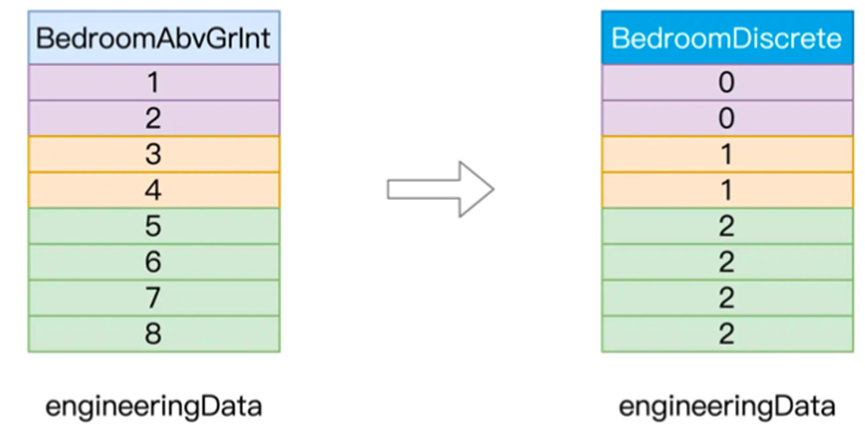
这样就完成了离散化的应用
之后是Embedding
Embedding指的是向量化,也就是把数据集合映射到向量空间,从而对数据进行向量化的过程
就比如我们的车库类型,他是一个字符串类型

对于这种非数字的字段,我们可以采用预处理的StringIndexer进行解析,但是这样用效果并不好,因为整数存在比较关系,但是车库类型并不存在
这时候我们就可以进行向量化,比如使用热独编码,我们进行解析成如下

我们直接将其映射到数组中的一个值,代表着一个纬度,这里我们演示下如何使用
|
import org.apache.spark.ml.feature.OneHotEncoder 2
// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列” // val indexFields: Array[String] = categoricalFields.map(_ + “Index”).toArray // 热独编码的目标字段,也即OneHotEncoder所需的“输出列” val oheFields: Array[String] = categoricalFields.map(_ + “OHE”).toArray // 循环遍历所有索引字段,对其进行热独编码 for ((indexField, oheField) <- indexFields.zip(oheFields)) { val oheEncoder = new OneHotEncoder() .setInputCol(indexField) .setOutputCol(oheField) engineeringData= oheEncoder.transform(engineeringData) } |
这样我们将所有的非数值特征,利用OneHotEncoder实例进行了转换,之后传入setInputCol和setOutputCol函数,最后调用transform,进行了转换
这样我们就完成了初步的转换
最后则是向量计算
在向量计算中,我们主要是构建样本集中的特征向量,主要由两部分,一部分是标的,对应过来就是房价,另一方面是特征向量,这可以来源于原始数值字段,或者归一化,离散化后的数值字段
我们这里仍然使用VectorAssembler进行拼接,构建特征向量,进行训练样本
|
import org.apache.spark.ml.feature.VectorAssembler 2
/** 入选的数值特征:selectedFeatures 归一化的数值特征:scaledFields 离散化的数值特征:fieldBedroomDiscrete 热独编码的非数值特征:oheFields */ val assembler = new VectorAssembler() .setInputCols(selectedFeatures ++ scaledFields ++ fieldBedroomDiscrete ++ oheFiel .setOutputCol(“features”) engineeringData = assembler.transform(engineeringData) |
上面我们指定了传入的字段
以及标的字段features
这样之后就有了新的字段,features
最后就可以进行了线性回归模型的计算
|
// 定义线性回归模型
val lr = new LinearRegression() .setFeaturesCol(“features”) .setLabelCol(“SalePriceInt”) .setMaxIter(100) // 训练模型 val lrModel = lr.fit(engineeringData) // 获取训练状态 val trainingSummary = lrModel.summary |
这样我们就进行了特征工程的使用
最后我们来一张图来进行展示
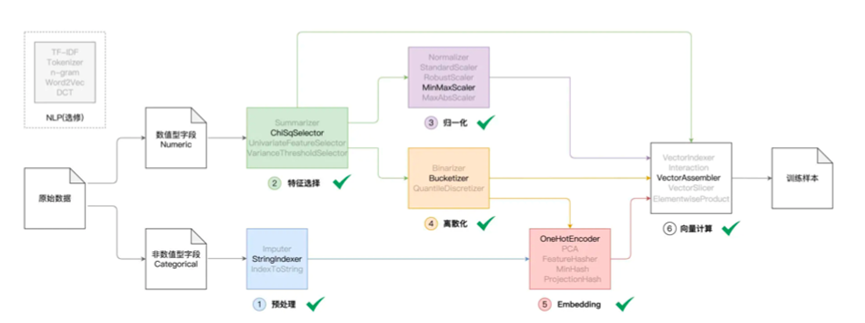
然后我们总结下涉及的6大特征初六函数