在这一章,我们直接从一个房价预测的小项目入手,来初步了解机器学习以及Spark MLlib的基本用法,主要展示Spark如何使用特征模型,以及对模型进行调优。
我们采用了Kaggle平台的House Prices 竞赛项目。一共有4个文件,分别包含如下
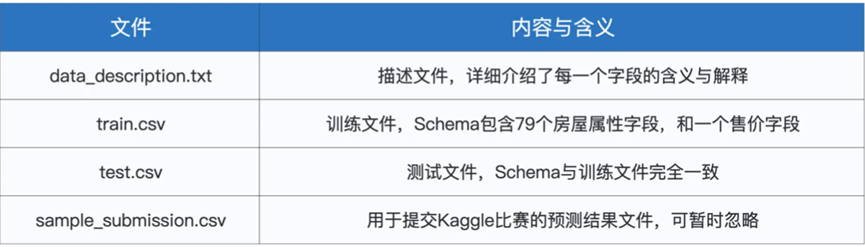
其中train.csv和test.csv的Schema完全一致,都包含79个房屋属性以及一个交易价格字段
其中train进行训练模型,而在test.csv用于验证模型效果,data_description.txt用于讲述字段含义
这里我们进行机器学习的Spark代码
不过在使用之前,我们先来明确机器学习的概念,机器学习就是根据一个特定的分布模型,来通过优化算法,自动的调整模型参数,从而让模型不断的逼近训练数据的原始分布
在模型训练完成之后,我们还会使用一份新的数据集,来测试模型的预测能力,在这个过程,我们称之为模型测试
那么我们直接回到这个数据集中,我们需要使用Spark MLlib机器学习框架,来完成房价预测
不过首先我们需要选择一个合适的分布式模型,按照不同的分类,模型可以分为不同种,比如按照拟合能力,有线性和非线性的模型,按照预测标的,可以有回归,分类,聚合,挖掘等,按照模型复杂度,可以有经典算法和深度学习,还可以分为广义模型,树模型,神经网络
这里我们拿一个比较简单的模型来进行拟合,也就是线性回归模型
选定了模型之后,我们需要给数据模型,选择相关的属性进行训练,比如对于房价来说,重要的因素有房屋面积,不重要的因素有路面类型等,这里我们选择的特定属性,称为数据特征
在这里,我们先利用SparkSession的read API,来从train.csv种读取为DataFrame,并观察样本构成
val trainDF: DataFrame = spark.read.format(“csv”).option(“header”, true).load(filePath)
在这一版的实现种,我们先关注Spark MLlib的基本用法,所以我们只选择地上面积,地下面积,车库面积进行选择
这样我们书写如下的代码,由于原本字段是String类型的,这里我们转换为Integer类型
val selectedFields: DataFrame = trainDF.select(“LotArea”, “GrLivArea”, “TotalBsmtSF“,, ” GarageArea” , ” SalePrice “)
val typedFields = selectedFields
.withColumn(“LotAreaInt”,col(“LotArea”).cast(IntegerType)).drop(“LotArea”)
.withColumn(“GrLivAreaInt”,col(“GrLivArea”).cast(IntegerType)).drop(“GrLivArea”) .
.withColumn(“TotalBsmtSFInt”,col(“TotalBsmtSF”).cast(IntegerType)).drop(“TotalBsmtSF
.withColumn(“GarageAreaInt”,col(“GarageArea”).cast(IntegerType)).drop(“GarageArea
.withColumn(“SalePriceInt”,col(“SalePrice”).cast(IntegerType)).drop(“SalePrice”)
typedFields.printSchema
这里我们准备好了DataFrame,然后进行训练样本的准备
val features: Array[String] = Array(“LotAreaInt”, “GrLivAreaInt”, “TotalBsmtSFInt”)
准备好捏合字段,然后我们进行特征向量的捏合
val assembler = new VectorAssembler().setInputCols(features).setOutputCol(“features”)
val featuresAdded: DataFrame = assembler.transform(typedFields)
.drop(“LotAreaInt”)
.drop(“GrLivAreaInt”)
.drop(“TotalBsmtSFInt”)
.drop(“GarageAreaInt”)
featuresAdded.printSchema
这样我们聚合了特征变量,并去掉了参与聚合的变量
这样我们整个数据集的格式如下
root
|– SalePriceInt: integer (nullable = true)
|– features: vector (nullable = true) // 注意,features的字段类型是Vector
这样我们把训练样本分为来那个烦恼,一部分用于模型训练,一部分用于初步验证
val Array(trainSet, testSet) = featuresAdded.randomSplit(Array(0.7, 0.3))
完成了这样的数据模型构建
我们就可以利用Spark MLlib进行回归模型,在Spark中,线性模型由LinearRegression类实现,然后是创建模型实例,最后利用fit函数进行训练
val lr = new LinearRegression()
.setLabelCol(“SalePriceInt”)
.setFeaturesCol(“features”)
.setMaxIter(10)
val lrModel = lr.fit(trainSet)
在上面我们创建了一个LinearRegression的实例,然后通过setLabelCol函数和setFeatureCol函数设置了预测字段和特征向量字段,然后利用setMaxlter来指定了迭代次数
在fit训练完成之后,我们就可以进行模型效果的评估
首先是获取其评估指标
val trainingSummary = lrModel.summary
这里我们获取的是summary的rootMeanSquaredError
RMSE结果为 45798.86
说明存在45798.86的预测误差,还是处于一个欠拟合的过程
这说明我们构建的模型还是太过于简单,我们需要更加丰富这个模型,不过这也只是我们对模型构建的初步了解,这样基本演示通就行
总结下这一章,我们看了如何使用Spark MLlib进行机器开发,主要利用了线性回归模型对房价进行了模型构建,并进行了测试,了解其开发的流程
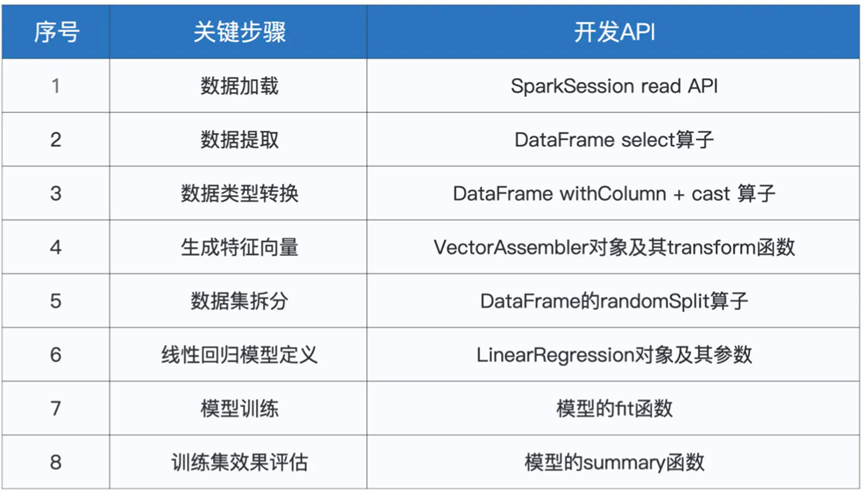
总体采用的算子如下