这里我们简单说下,Spark UI,用于进行Spark中运行任务的分析,其提供了众多的Metrics,从而方便开发者进行定位Spark性能及代码相关问题
我们仍然拿小汽车摇号应用开发的代码来讲解Spark UI的使用
在启动代码的时候,我们需要设置如下的配置项

并利用shell脚本启动
./sbin/start-history-server.sh
之后启动spark-shell,并打开主节点ip的8080端口,从而打开Spark UI页面
接下来我们简单介绍下Spark UI中的常见主题页
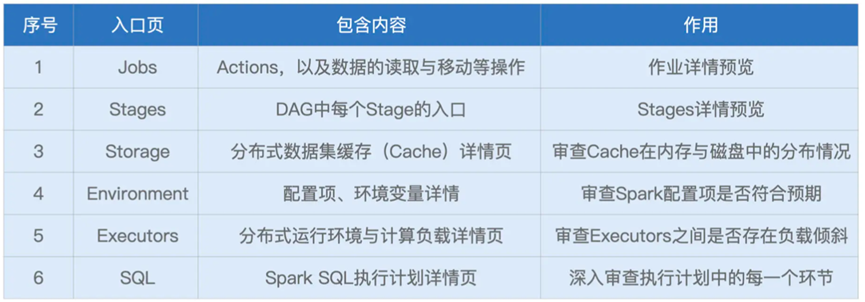
不过我们会进行乱序的介绍,从易到难,依次讲解
首先是Executors,主要记录了不同的执行节点信息
其中包含了Summary信息,代表着所有Executors度量指标的相加之和
其他还有着Executors信息,包含每一个Executor的详情,其中包含的指标主要如下
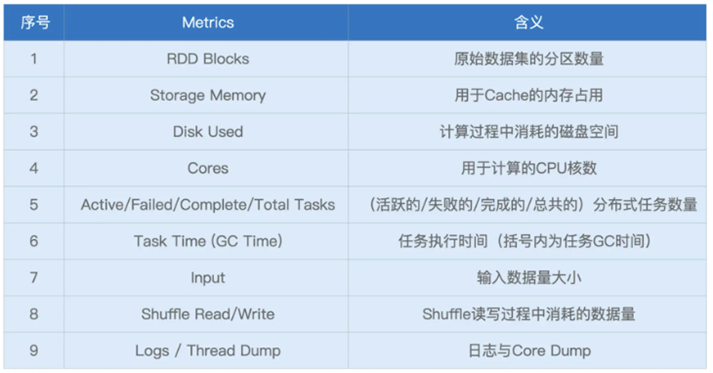
其中也是cpu,内存的使用情况,只不过统计级别是Executor
其次是Environment,记录了各种各样的环境变量和配置项信息
基本包含以下五类细腻下
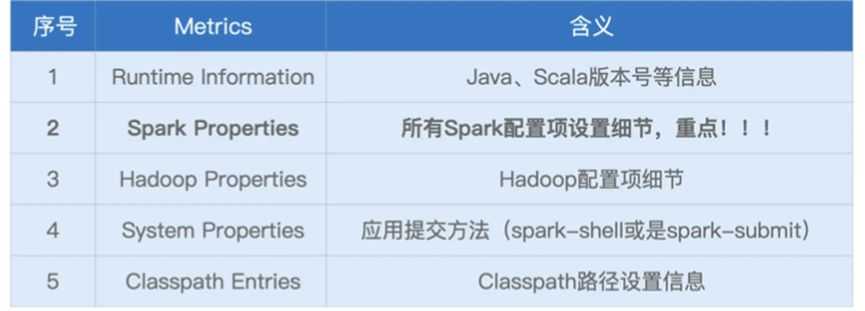
其中的Spark Properties是重点,记录了所有运行Spark配置项
然后是Storage页面
Storage详情页,记录着每一个分布式缓存 RDD Cache,DataFrame Cache
包含着缓存级别,缓存分区,比例,占据了磁盘和内存大小
然后是SQL页面
当我们执行DataFrame,DataSet或者SQL的时候,对应的执行详情就可以在这个页面看
其中分别包含着三个条目,分别是统计申请编号,统计中签编号和save,分别对应着的读取数据源,缓存数据,以及输出,其中的重点是输出这个条目
我们可以点击进去查看save详情
其中保存了一个执行过程的DAG图
我们可以分别查看不同阶段,不同算子的性能占用,比如Exchange,对应的就是Shuffle
Sort,排序操作,Aggregate 聚合操作
对于Exchange的信息主要如下

主要的信息如下

可以去根据其中额度Data Size total 来决定采用什么样的join方式,是否使用Broadcast
Sort也是类似

不过由于Sort并没有什么调优项,我们先且不表
Aggregate则是对应聚合算子的内存消耗
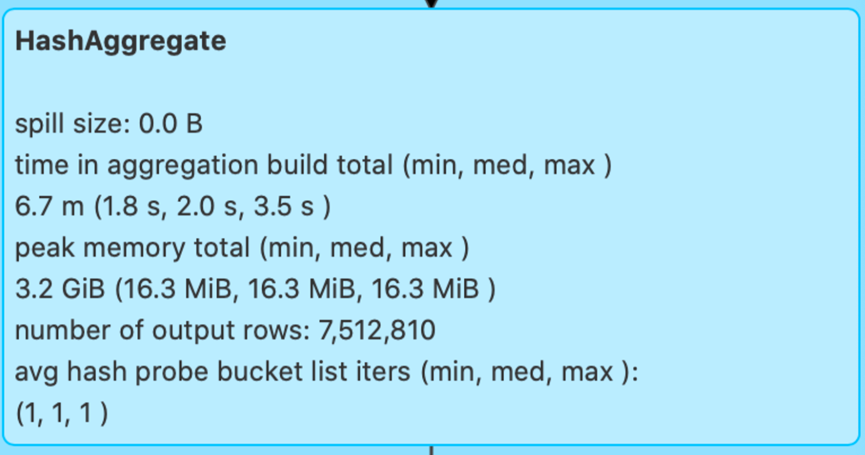
方便我们观察聚合算子的内存消耗
之后是Jobs页面
Spark UI通过Actions,记录每个Action对应的作业执行情况
不过我们进入其中,会发现其记录的是每个Stage的详细信息,那么其实和Stage页面的信息一致,那么我们就拿Stage页面的信息进行讲解
在Stage详情页中,主要就是三类信息,分别是Stage DAG,Event Timeline以及Task Metrics
对于Stage DAG,则是跟Job页面下的DAG展示一致
其次是Event Timeline
点击这个页面,会显示整个分布式集群中,不同计算环节的时间花小,每一个条带都是一个分布式任务
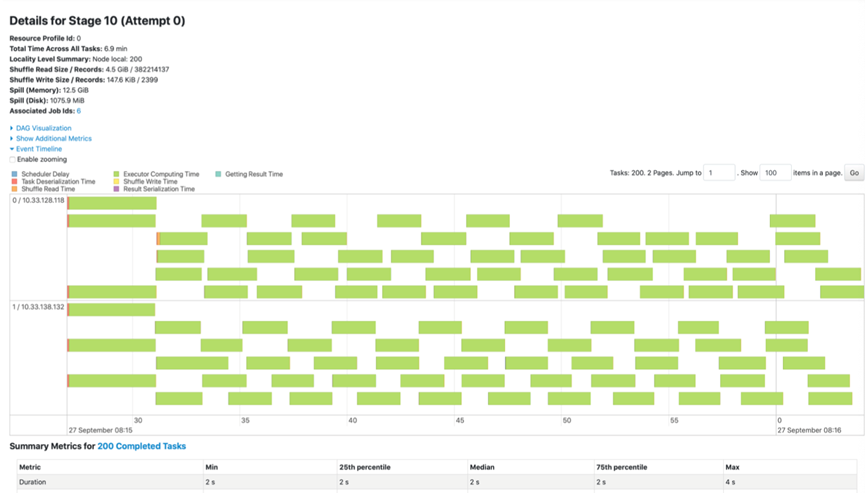
包含着不同的颜色
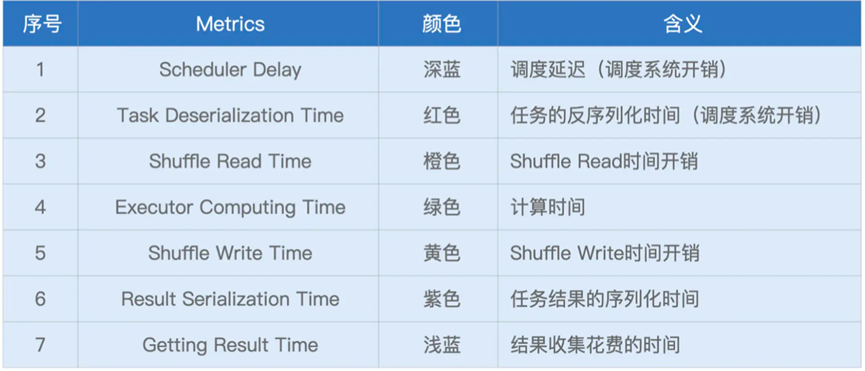
如果蓝色的过高,说明调度开销严重
如果黄色或者橙色的过高,就说明Shuffle负载过重,需要考虑修改Shuffle为Broadcast Join
其次是Task Metrics,其中Summary Metrics是所有Tasks执行的汇总
基本的指标如下
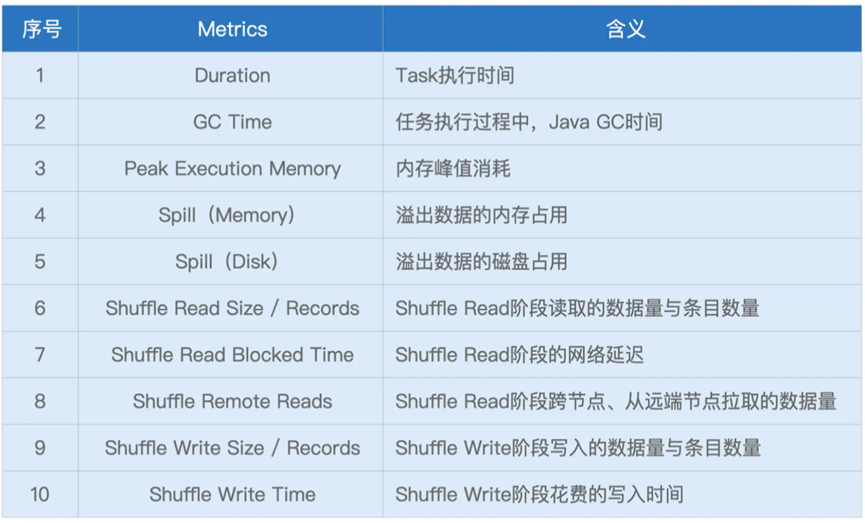
其中值得注意的是Spill的两个指标,指的是溢出数据的内存占用到的磁盘占用
除了Summary Task,还有着更加细粒度的Tasks提交,不过在其中大部分的Metric是重叠的,只有部分不重合
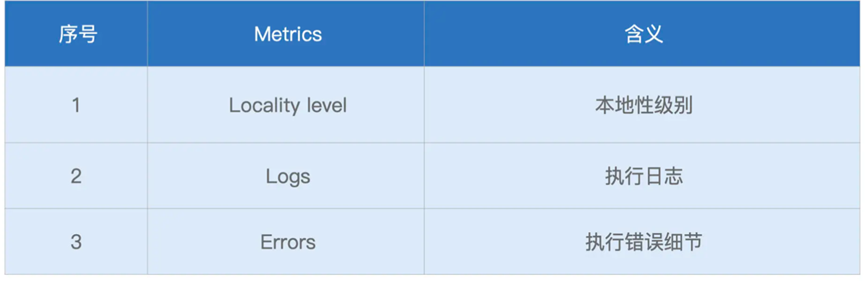
比如Log,以及Error错误信息,这些供我们在错误的时候定位问题所在。
那么我们到此就说完了Spark UI相关的信息,从Spark UI的六个部分,基本介绍了其可以覆盖的指标,可以进行什么样的监控