之前我们通过SparkSession read API 从分布式文件系统中创建了DataFrame
然后通过创建临时表的方式执行SQL,或者DataFrame API 来进行各种各样的数据转换
这里全部利用的Spark SQL这一框架,但是除了直接使用,Spark SQL另一个经典的场景是和Hive集成,构建的分布式数据仓库
那么这一章,我们就看下Hive 和 Spark的集成方式,主要有两种,一种是Spark为主角,称为Spark with Hive,另一类是Hive出发,称为Hive on Spark
那么在说这两个集成方式之前,我们先说下Hive的架构
Hive是Hadoop社区用于构建数据仓库的核心组件,大致的功能可以概述为接收用户提交的SQL查询,然后Hive解析后,转换为分布式任务,最后交付给Hadoop MapReduce执行
其整体架构如下
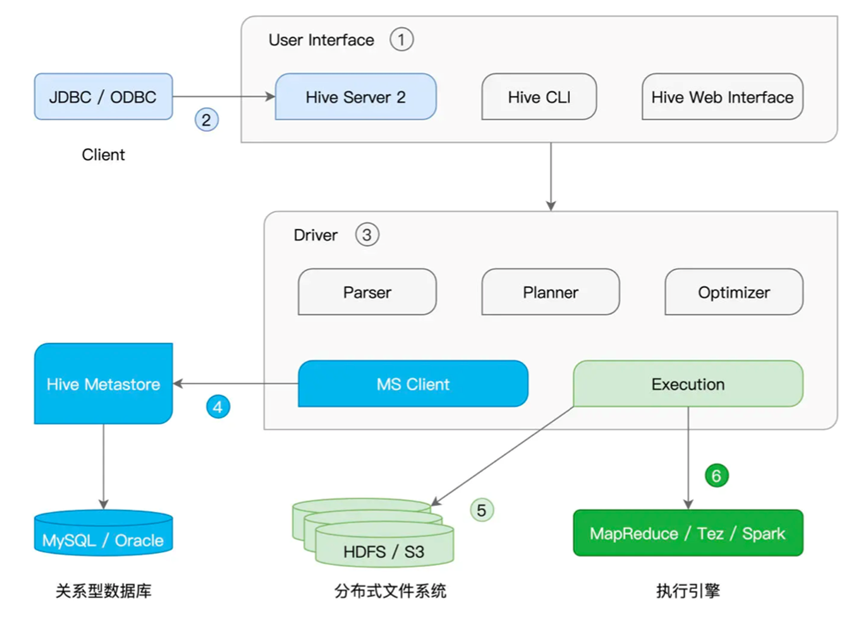
核心部件是User Interface负责为开发者提供SQL接入服务,从而提交SQL
可以通过CLI,Web页面以及Hive Server2(通过JDBC) 链接
Driver,负责处理SQL,将SQL转换为语法树,生成执行计划并优化后交给更下层的计算引擎除此外,Hive还有着Hive Metastore,负责存储元数据信息,帮助计算引擎定位并访问分布式文件系统中的数据
而在我们说的不同主角里
HIve做主角,其实就是Spark作为Hive的底层执行引擎,叫做Hive on Spark,
Spark做主角,则是Spark只将Hive作为一种元信息的管理工具,这种情况叫做Spark with Hive
这里我们先说Spark with Hive
这里是Spark 通过访问Hive MetaStore来获取到更多的数据访问来源,这种情况下,我们仍然直接使用Spark,Hive Metastore只不过是Spark用于扩充数据来源的辅助工具
这种情况下的集成方式有三种,分别是创建SparkSession 访问本地或者远程的Hive Metastore
获取是通过spark-sql CLI,访问本地的Hive MetaStore
最后是通过Beeline客户端,访问Spark Thrift Server
通过Spark Session 访问很简单,直接在创建Spark Session的时候,通过config函数来指定hive.metastore.uris参数
这里我们给出一段示例代码
|
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame val hiveHost: String = _ // 创建SparkSession实例 val spark = SparkSession.builder() .config(“hive.metastore.uris”, s”thrift://hiveHost:9083″) .enableHiveSupport() .getOrCreate() // 读取Hive表,创建DataFrame val df: DataFrame = spark.sql(“select * from salaries”) df.show |
在创建SparkSession的时候,通过config指定了hive metastore地址,然后就直接通过sql访问Hive存在的salaries表
通过这种方式,我们访问到了Hive数据,但是由于只用了MetaStore这一环节,对于Hive的其他组件并未涉及
至于通过Spark-sql CLi访问Hive Metastore,则是需要将hive的hive-site.xml放在Spark安装目录的conf下
不过这种情况下,要求spark-sql CLI和Hive Metastore在一个计算节点上,所以并不考虑这种集成方式
最后是Beeline客户端,通过客户端去链接Spark Thrift Server,从而访问Hive表
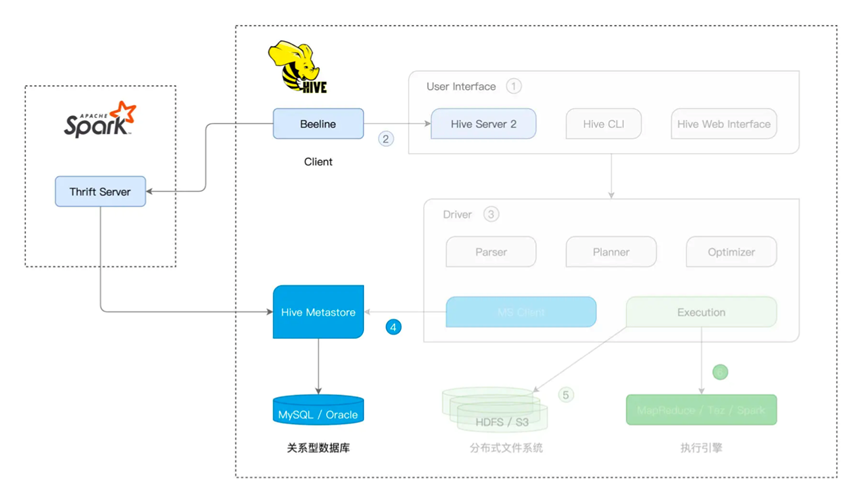
Beeline本来是Hive客户端,通过JDBC接入Hive Server2,由于Hive Server2实现采用了Thrift RPC,所以也被称为Hive Thrift Server2,整体处理为,接收查询请求,然后进行解析优化后交给Hive的计算引擎进行执行处理,最后返回给Beeline客户端
而在Spark上有着Spark Thrift Server,脱胎于Hive Server2,逻辑基本一致
Spark 发出一个SQL 查询,则是先经过Spark Thrift Server中一系列对SQL的优化,最后交给Spark Core进行执行
也就是我们先启动一个Spark Thrift Server,利用Spark的start-thriftserver.sh脚本
. /start-thriftserver.sh (别忘了配置相关的hive配置)
然后我们就可以直接访问Beeline来执行SQL语句处理Hive,这种情况下,实际执行者还是Spark
beeline -u “jdbc:hive2://hostname:10000”
到此我们说完了Spark with Hive,所有的处理都是Spark做主角
接下来我们看看Hive on Spark
由于Hive架构中的很多组件都是可插拔的,尤其是执行引擎,默认是Hadoop Reduce,同时支持Tez和Spark,所谓的Hive on Spark,其实就是Spark作为后端的分布式执行引擎
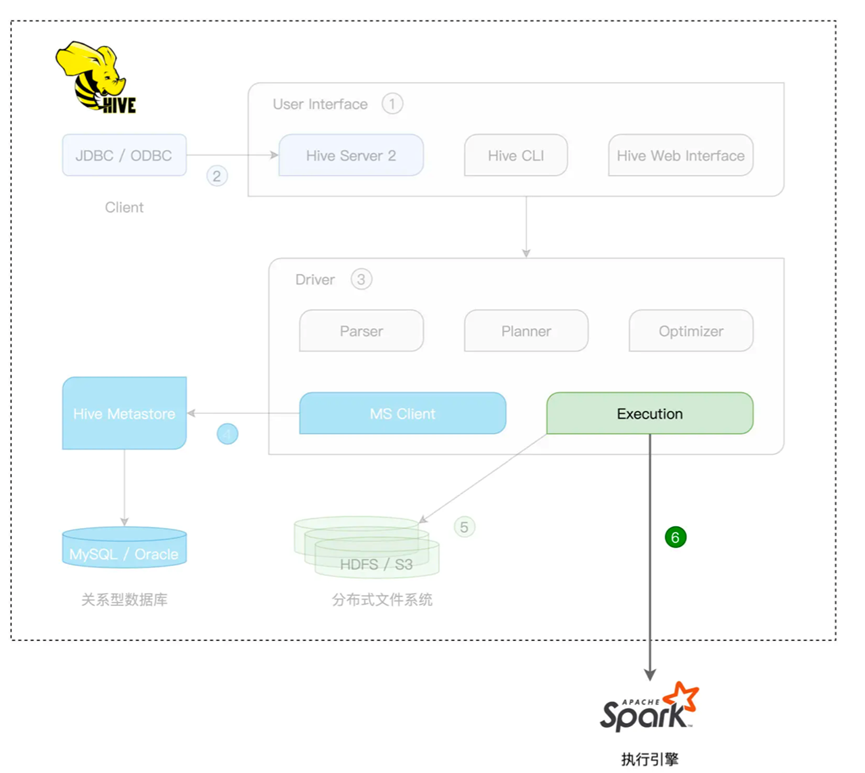
在这种模式下,真正的计划生成,是由Hive的Driver来完成的
在这种集成方式下,Hive将SQL语句翻译为RDD下的DAG,最后交付给Spark Core执行
而且由于是外部集成,所以性能并不如Spark SQL和Spark Core集成那么好
那么我们看下如何进行集成
首先我们需要修改hive相关的配置项
hive.execution.engine 指定后端的执行引擎 value设置为spark
spark.master 设置spark部署模式
spark.home 设置Spark安装目录
配置完成参数之后,我们再向Hive SQL提交请求,就会最终转换为Spark的执行计划,进行分布式的执行
那么我们总结一下今天的内容,我们说了Spark和Hive的两种集成方式,Spark with Hive和Hive on Spark,前者由Spark 主导,后者由Hive主导
一个是Spark简单的利用Hive metastore
一个是Hive将Spark作为后端计算引擎