Join的内部实现
上一节我们说了,在Join中可以选择的匹配机制有三种,分别是Hash Join,Sort Merge Join以及Nested Loop Join,而在数据分发的角度,数据关联的实现机制又有Shuffle Join和Broadcast Join两个大类,这样两两结合,就可以有6种结合策略。
我们首先说下数据关联的实现机制
分别是Shuffle Join和Broadcast Join,两者的目的一致,就是服务于Join的时候,要join字段相同的数据坐落在同样的Executors进程里
而这个数据的分发阶段,可以选择的手段主要有两种,分别是Shuffle和Broadcast
Shuffle Join的具体流程和原本的Shuffle流程一致,就是根据Join Keys计算哈希值,然后按照哈希值对并行度进行取模,最后进行分发,完成之后就可以保证字段值相同的数据在一个Executors中
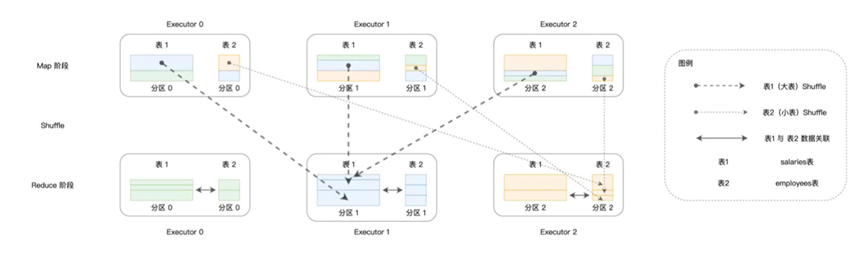
上面可以看出来Shuffle的过程,而且在Spark中使用Shuffle进行分发是默认情况
不过Shuffle流程中,会消耗大量的CPU,内存,磁盘
其次就是Broadcast Join
在Broadcast Join中
我们会尝试将数据集封装为广播变量,如果将小的表作为广播变量,进行关联,其实速度是最快的,只不过要占用更多的内存,我们看下以显式的方式进行关联的方式
|
val bcEmployees = broadcast(employees)
// 内关联,PS:将原来的employees替换为bcEmployees val jointDF: DataFrame = salaries.join(bcEmployees, salaries(“id”) === employees(“id”) ,”join” ) |
获取如下的流程
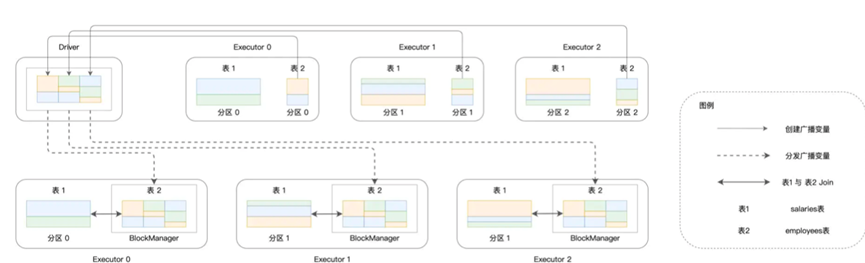
然后我们结合来看,对于数据的匹配机制,可以有HJ, SMJ,NLJ三种类型,集合上面说的Shuffle Join或者Broadcast Join,一共会有6种Join策略
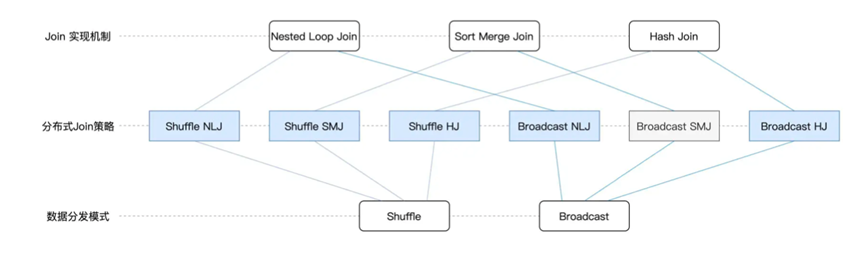
对于这6种策略,Spark支持其中5种,用于面对不同的关联条件

对于等值关联,则首先考虑Broadcast HJ,Shuffle SMJ ,Shuffle HJ
对于不等值查询,则是实用Broadcast NLJ Shuffle NLJ
可以看出,对于on id_a> id_2这种不等值查询,只能使用NLJ算法
对于等值查询,首先使用broadcast HJ,对于不等值查询,则是Broadcast NLJ优先级高
这也是说明了Broadcast的性能更快,不过这个要求是Broadcast Join的前提成立
那么Broadcast Join的前提就是我们可以将基准表的全表放入到Driver以及Executors的内存
而当无法使用广播Join的时候,则是只能考虑Shuffle进行分发,而在等值查询种,虽然同样有着Shuffle SMJ和Shuffle H J,不过由于Shuffle在进行计算的时候,可以就同时排好序,所以一般采用Shuffle SMJ,而基本不会用Shuffle HJ
那么接下来我们回到广播Join这一个策略中,我们上面演示了使用broadcast函数来强制广播基表,那么Spark SQL不会自动的采用Broadcast Join策略吗?
其实是需要开启相关的配置项,从而让Spark 采用自动优化的手段,选择Broadcast Join
首先第一个,我们先要确保Join的时候,选择较小的表作为基表
然后有一个配置项,设置了采用Broadcast Join的阈值

当基表小于这个设定值,就会自动选择Broadcast Join策略
那么如何计算基表的大小呢?需要分情况进行讨论
如果是直接存储在磁盘中,那么就直接获取存储大小,如果是来自于DAG计算的中间环节,那么就需要获取到执行计划中的统计值,然后进行对比
可以参考如下代码
|
val estimated: BigInt = spark
.sessionState .executePlan(plan) .optimizedPlan .stats .sizeInBytes |
然后Spark SQL还提供了动态优化,名叫做AQE机制,全名是Adaptive Query Execution
自适应查询,主要应对三个方面,Join策略调整,自动分区合并,自动倾斜处理
开启他的配置为
spark.sql.adaptive.enabled 设置是否开启AQE,默认为FALSE
我们分别讲下三个方面
Join的策略调整,原本的机制中,只会按照运行之前的统计信息,进行优化,就好比磁盘存储
而在AQE之中,则是采用Shuffle中间文件的统计信息,进行重新计算,如果发现基表尺寸小于广播阈值,就会进行调整
就比如原本两个数据集都比较大,但是我们在join的时候进行了过滤,比如
Select * from a inner join b on a.id = b.id where a.age> 15 and a.age< 30
这种情况下,由于在filter之后就可以满足broadcast的阈值要求,就可以使用广播
说完了简单的Join策略调整,还可以说下AQE的剩下两个特性,自动分区合并和自动倾斜处理
都是对于Shuffle的优化
对于自动分区合并,主要的目标是Reduce阶段过小的分区合并在一起,其应对的就是在分区key在选取的时候,可能会选取诸如user_id item_id这种容易产生倾斜的字段,导致过多的小分区的出现
其设定值有两个
spark.sql.adaptive.adivsoryPartitionSizeInBytes 合并后的分区大小
spark.sql.adaptive.coalescePartitions.minPatitionNum 合并后的最小并行度
然后是自动倾斜处理
用于讲倾斜严重的大分区拆分为小分区,对应的设定值有三个
spark.sql.adaptive.skewJoin.skewedPartitionFactor 倾斜分区的比例系数
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 倾斜分区的最低阈值
spark.sql.adaptive.adivsoryPartitionSizeInBytes 倾斜分区的拆分单位
整体的拆分流程为,首先对所有分区进行排序,获取中位数,然后乘以设定的比例系数,然后得到判断值,最后选取大于判定值的分区为倾斜分区,然后按照拆分单位,将大于判定值的拆分为小分区
那么到此,我们首先说了Join中的数据分发两种实现
其次是关于boardcast join的优化
以及Spark为了能够使用boradcast join的努力,也就是AQE机制
对应的就是Join策略调整,自动分区合并,自动倾斜处理