13.Spark Sql的架构
我们上一节说了在Spark SQL框架下做应用开发的一般模式,首先是读取成DataFrame,其次是利用提供的算子来完成DataFrame之间的转换
那么Spark SQL为什么要提供自定义的算子,为什么要提供DataFrame
这两者的来源,主要原因可以总结如下
在之前的RDD相关的算子中,很多比如map算子中,都要求传入一个函数,由于传入的是一个函数,所以引入了一个问题,就是由于是开发者自己提供算子,所以对于Spark,Spark并不知道开发者要做什么,因此无法带来什么优化空间,只能将函数简单的打包后发给Executors中。
如果我们能够增加一些限制呢,让开发者在有限的算子中进行选择,是否可以对其进行优化呢?
这就是Spark SQL的核心概念,Spark SQL的核心就是定义了一套DSL算子,比如之前用的selct,filter,agg,groupBy,以及DataFrame格式
其次Spark SQL的架构并没有脱离原本的Spark架构,其是运行在Spark Core之上,由Spark SQL接收到用户的代码,进行优化,之后转换为Spark Core可以理解的方式进行执行
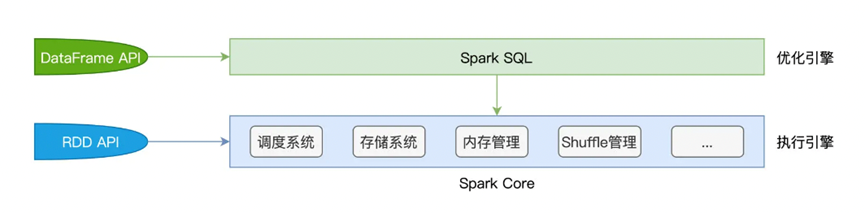
而在Spark SQL内部,则是由两个核心组件 Catalyst优化器和Tungsten
对于Catalyst优化器,主要负责创建并优化执行计划,将用户提交的代码形成语法树并优化其涉及的逻辑阶段和物理阶段,Tungsten则是负责和Spark Core进行执行
先说Catalyst优化器,其主要是创建并优化执行计划
首先是生成语法树,然后对这个语法树进行优化
我们还是拿之前说的倍率分析进行查看,看下如何进行构建语法树的
按照之前的代码执行,我们会生成一个如下的语法树
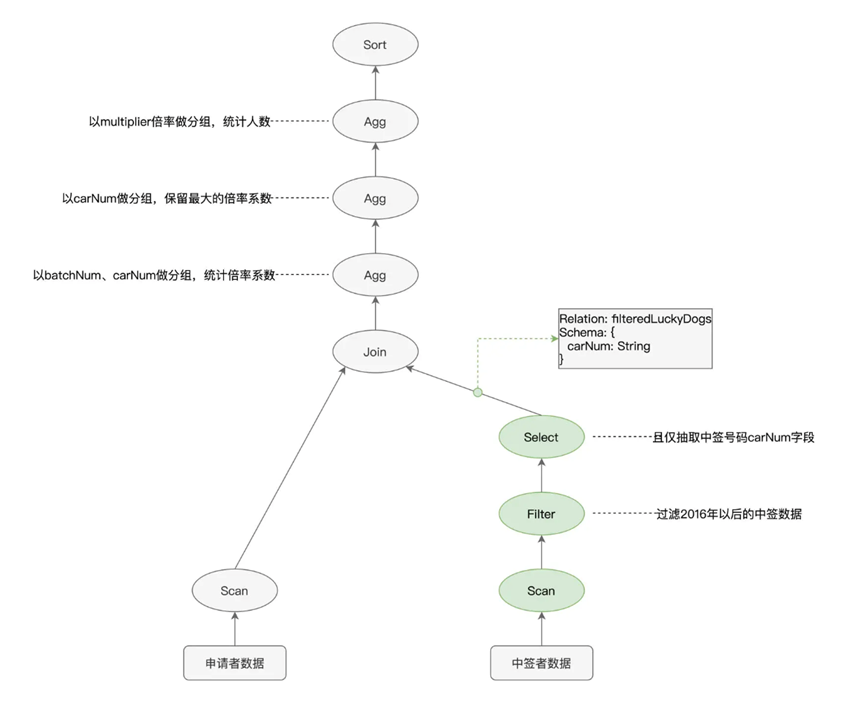
其中各个节点是各式各样的操作算子,比如filter,select,agg,边则是不同的DataFrame,记录了对应的Schema信息,比如字段名,字段类型等等
既然生成了这样的一个语法树,那么理论上可以直接发给Spark Core执行,但是Spark SQL的高明之处就在这里
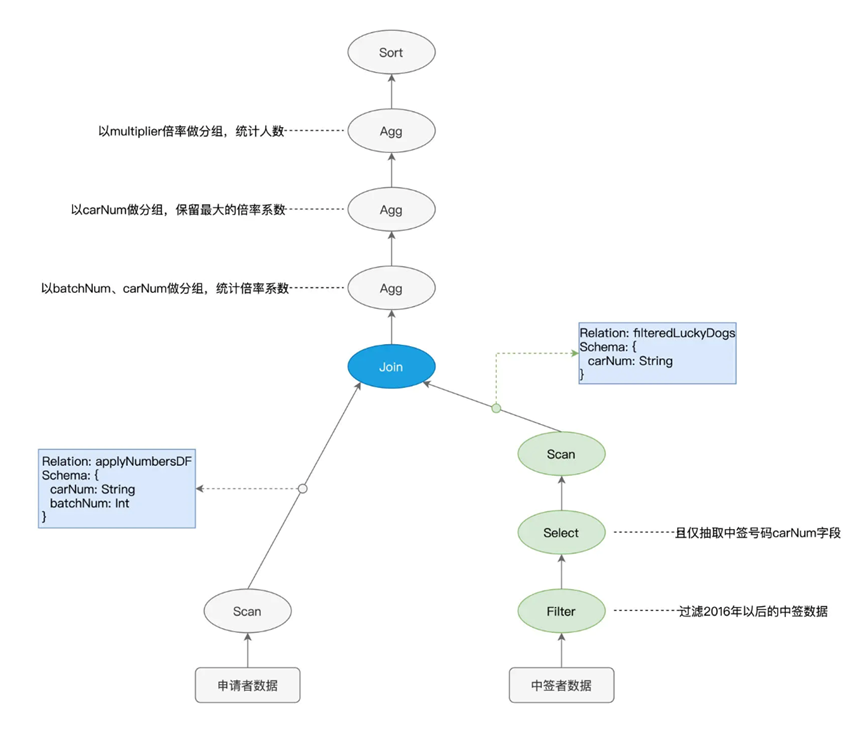
由于我们的数据是存储在Parquet文件中的,其支持谓词下推和列剪枝的特性
所以我们可以将原本的scan filter select流程改为 select+filter> scan
也就是在扫描过程中只选取符合条件的carNUm字段,而剪掉其他数据文件

那么由于这种谓词下推和列剪枝的特性,都可以被称为启发式的规则和策略,对应的就是逻辑优化阶段的优化,在这之后逻辑计划的优化为
然后就是物理阶段的优化,这一阶段的优化,可以说是依赖于各种的统计信息,比如数据表的尺寸,数据缓存,Shuffle中间文件,就好比,我们声明了join节点,交代了applyNumbersDF和filteredLuckyDogs需要做关联,但是实际上的物理实现有很多种,比如可以使用
NLJ嵌套循环链接 Sort Merge Join 排序归并链接,Hash join 哈希链接
并且分发的时候还有着Shuffle join和Broadcast join可供选择
在这里进行完成物理优化,就交给了Tungsten,继续进行打磨
Tungsten并没有将数据作为Java Object存储,而是设计为了Unsafe Row,本质上是字节数组,以极其紧凑的方式来存储DataFrame的每一条数据
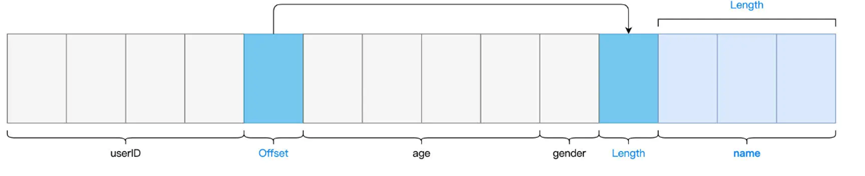
利用这种方式进行优化了对象存储,最后按照代码,划分为了不同的Stage,方便进行执行,将生成的代码交给了Spark Core进行执行
那么总结下,Spark SQL是一个在Spark Core之上的独立框架,其主要职责是在用户代码交付Spark Core之前,对用户代码进行优化
而优化交给了两个核心组件,分别是Catalyst和Tungsten