我们基本上说完了Spark的常用算子和一些架构概念,可以面对一些开发任务了,但是Spark强大之处在于其还有很多更高层的计算框架,比如Spark SQL,Structured Streaming和Spark MLlib的常规开发方法,来面对不同的数据应用场景
那么,我们就首先从Spark SQL开始进行讲解
这次我们的示例是拿的北京市小轿车摇号来进行的讲解
目标是统计参与摇号的司机朋友,真正摇到号的时候的摇号倍率
究竟是在8倍的时候摇到号了?还是10倍的时候?
首先我们呢准备了一些数据,从11年到19年的摇号数据,其中目录结构如下
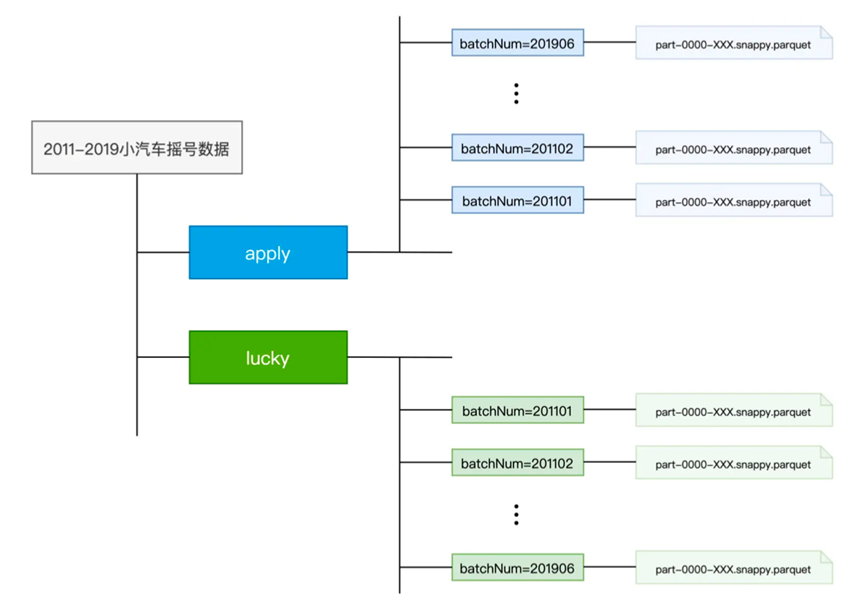
分为了apply和lucky两个目录,apply目录是所有申请号码,lucky则是所有中签号码
首先我们要做这样的一个需求,必须要将数据读入到Spark中,而在Spark SQL中,我们一般使用DataFrame进行数据读取
|
import org.apache.spark.sql.DataFrame
val rootPath: String = _ // 申请者数据 val hdfs_path_apply: String = s”${rootPath}/apply” // spark是spark-shell中默认的SparkSession实例 // 通过read API读取源文件 val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply) // 数据打印 applyNumbersDF.show // 中签者数据 val hdfs_path_lucky: String = s”${rootPath}/lucky” // 通过read API读取源文件 val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky) // 数据打印 luckyDogsDF.show |
我们分别读入了apply和lucky的数据,利用的SparkSession的read API进行的读取,读取之后形成了一个DataFrame,最后利用DataFrame的show,完成了数据展示
其中SparkSession是Spark在2.0之后提供的新一代接口,SparkContext通过textFile读取文件,而SparkSession则是通过read API将数据源转换为DataFrame
而这个DataFrame,比起RDD,则带有着Schema,可以简单的看作是数据库中的一张二维表
而我们show出来的结果就可以应验我们上面的说法
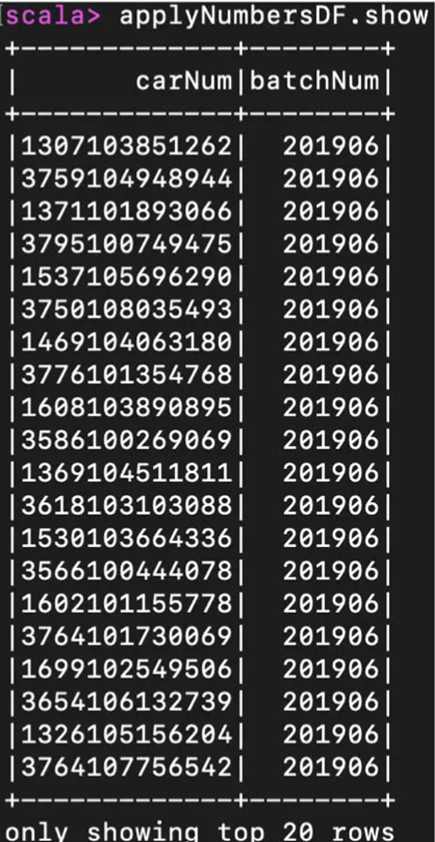
无论是哪个show,得到的结果都会是包含两个字段carNum,batchNum
carNum是申请号码,而batchNUm代表着摇号批次
那么有了这个样本之后,我们回到我们最初的需求,也就是计算中签率和中签时间的关系
也就是查看抽签者在什么倍率下抽到了签
那么首先第一步,我们要过滤16年之前的中签数据,因为那时候中签规则还没实施
|
// 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段
val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col(“batchNum”) >= “201601”) // 摇号数据与中签数据做内关联,Join Key为中签号码carNum val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq(“carNum”), “inner”) |
首先我们对luckDogsDF进行过滤,然后进行join
我们调用了join算子,完成两个算子的关联,join算子有三个参数,分别是另一个DataFrame,关联的字段,关联的形式,譬如inner作为内关联,left代表左关联
然后我们计算每个用户在摇到号的时候,是多少倍倍率了
也就是group之后count
| val multipliers: DataFrame = jointDF.groupBy(col(“batchNum”),col(“carNum”)) .agg(count(lit(1)).alias(“multiplier”)) |
通过groupBy来聚合号码,然后利用agg和count算子来聚合出现的次数,然后使用alias来将聚合后的数据命名为multiplier
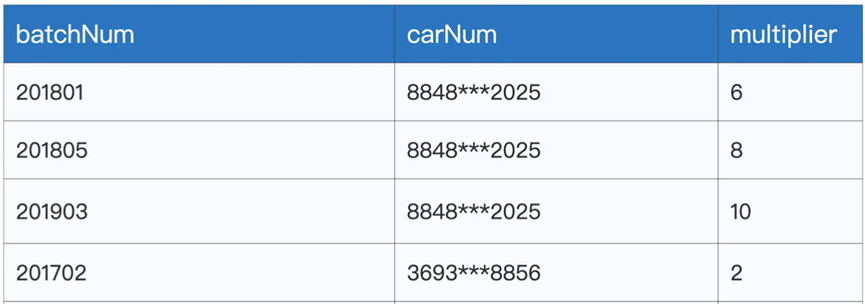
不过这样我们获得数据,有着不同倍率下的数据,对于同一个号码,我们只需要保留一个最大的倍率,这样我们就需要对上面的数据进行聚合,获取最大的multiplier
| val uniqueMultipliers: DataFrame = multipliers.groupBy(“carNum”)..agg(max(“multiplier”).alias(“multiplier”)) |
这里我们groupBy carNum,然后还用agg和max算子来保留倍率最大值
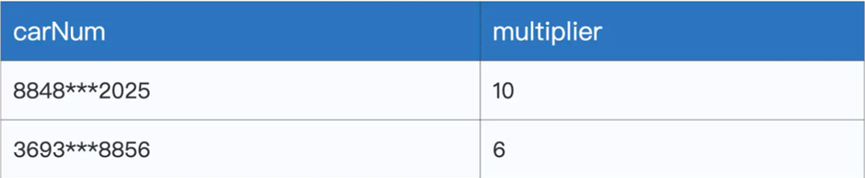
最后我们统计不同倍率下中签的人数
|
val result: DataFrame = uniqueMultipliers.groupBy(“multiplier”) .agg(count(lit(1)).alias(“cnt”))
.orderBy(“multiplier”) |
这里我们那multiplier进行了聚合,然后统计了不同倍率下的人数
获取到了最后的数据集
那么总结一下,我们学习了Spark SQL,通过一个简单的示例,讲解了如何读取,以及上面存在的转换算子。