上一节我们说了Spark SQL这一构建于Spark Core之上的框架,这一次就让我们说下Spark SQL框架中关键的数据类型DataFrame相关的数据处理算子,主要可以分为两类,一类是结构化查询语言也就是sql,另一类则是DataFrame相关的开发算子。
那么我们先说SQL语句,对于任意的DataFrame,我们都可以使用createTempView或者createGlobalTempView 在Spark SQL中创建临时数据表
两者一个是创建的临时表,其生命周期仅限于SparkSession内部,createGlobalTempView创建的临时表,可以在同一个应用程序中跨SparkSession提供访问
我们来展示下如何使用createTempView创建临时表
基本代码如下
|
import org.apache.spark.sql.DataFrame
import spark.implicits._ val seq = Seq((“Alice”, 18), (“Bob”, 14)) val df = seq.toDF(“name”, “age”) df.createTempView(“t1”) val query: String = “select * from t1” // spark为SparkSession实例对象 val result: DataFrame = spark.sql(query) result.show 13 /** 结果打印 +—–+—+ | n ame| age| +—–+—+ | Alice| 18| | Bob| 14| +—–+—+ */ |
首先是创建数据集,然后toDF来创建DataFrame,之后利用createTempView创建一个临时表,之后利用sql查询table,最后show来展示
首先说,DataFrame之间的转换也属于延迟计算,只有出现Action算子的时候,才会及性能执行
当然,Spark SQL还封装了一些属于自己的函数,比如array_distinct,collect_list
可以浏览官网的Functions页面查找完整的函数列表。
之后是DataFrame相关的算子
主要源于了DataFrame相关的双面性,一方面是基于RDD,故RDD支持的算子,DataFrame都支持,另一方面就是属于自己算子,基本列表如下

我们按照上图的顺序进行讲解
首先是和RDD一样的算子
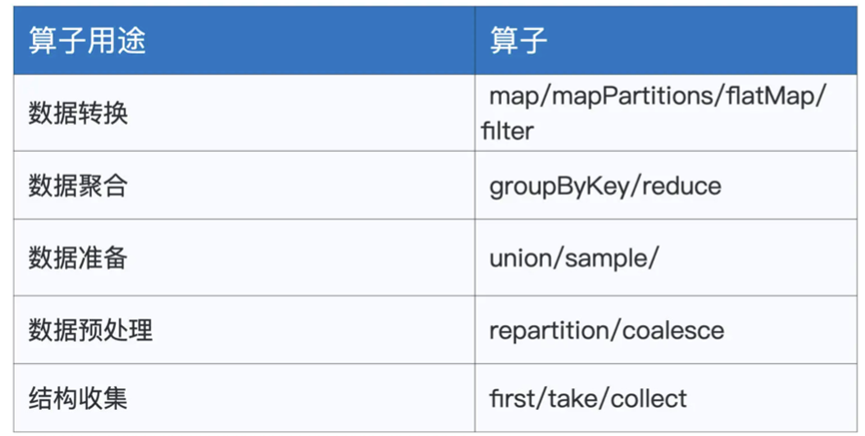
用法还是返回都一样
然后是探索类算子
主要是用于了解算子,比如实际数据,比如数据格式,执行计划,常见的如下
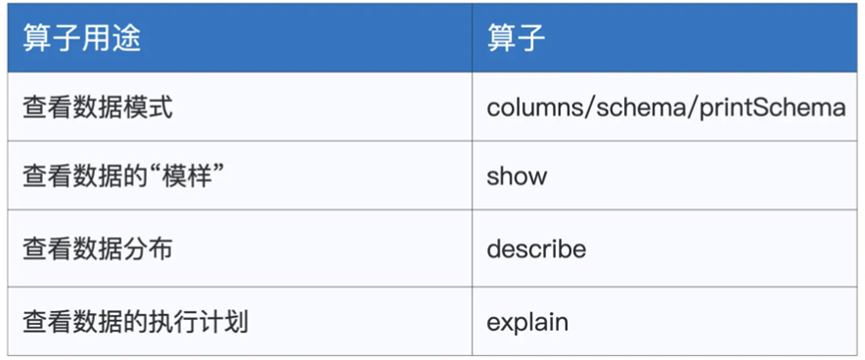
对于数据格式,columns schema printSchema用途类似,都是负责获取数据的格式
比如我们利用printSchema,获取的结果如下
除了数据格式等信息,还可以使用describe来查看列值的分布统计,比如使用df.describe(“age”)来获取对应age列的极值,平均值,方差等信息
以及使用explain函数,来获取Spark SQL给的执行计划
清洗类算子
我们需要对数据进行清洗,比如删除某些列,删除某些行
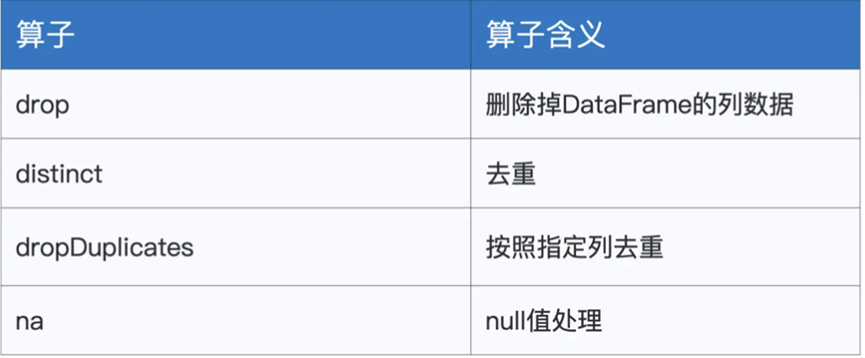
其中drop函数负责将指定的列从DataFrame中进行清除,比如我们想要将上面的数据的gender列清除,直接调用employees.DF.drop(“gender”)即可,并且可以通过声明多个入参来清除多个列
其次是distinct,进行去重,以employeesDF为例,当有多个数据记录的字段值相同的时候,进行去重,dropDuplicates也是进行去重,不过是按照某个字段进行去重,比如按照gender进行去重,最后结果只会有男和女

employees.dropDuplicates(“gender”).show
最后一个算子是na,是选取DataFrame的null数据,na往往配合drop或者fill使用,employees.na.drop用于删除DataFrame中的null数据,employees.na.fill(0)则是全部填充0
接下来是转换类的算子
基本如下
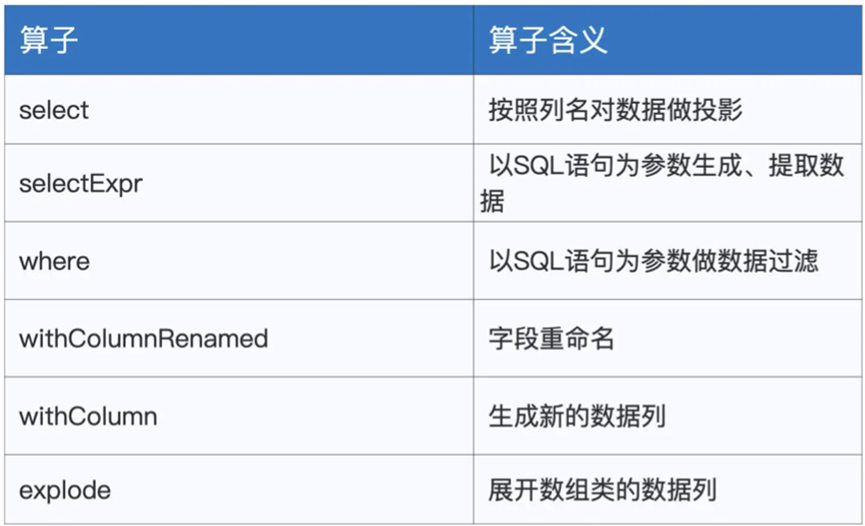
首先是select,选取DataFrame下的部分字段
employeesDF.select(“name”,”gender”).show
其次是selectExpr,支持其中不仅可以选择字段,还可以通过函数的方式生成新的字段
employeesDF.select(“name”,”gender“,”concat(id, ‘_’, name)as id_name“0).show
这样我们通过concat函数来将两个列拼接后形成新的数据列
其次是where和withColumnRenamed这两个算子,
where 配合sql语句对DataFrame进行数据过滤,比如
employeesDF.where(“gender = ‘Male’”)
withColumnRenamed对字段进行重命名
withColumn,则是生成新的数据列,类似selectExpr,其中可以利用sql函数
employeesDF.withColumn(“crypto”,hash($“age”)).show
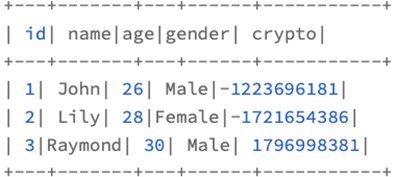
最后一个算子,explode,则是展开数组类型的数据列,生成新的数据记录
比如我们有个数组字段
|
val seq = Seq( (1, “John”, 26, “Male”, Seq(“Sports”, “News”)), 2 (2, “Lily”, 28, “Female”, Seq(“Shopping”, “Reading”)),
(3, “Raymond”, 30, “Male”, Seq(“Sports”, “Reading”)) ) val employeesDF: DataFrame = seq.toDF(“id”, “name”, “age”, “gender”, “interests”) employeesDF.withColumn(“interest”, explode($”interests”)).show |
得到的结果如下

将数据进行了展开
还有就是分析类的算子
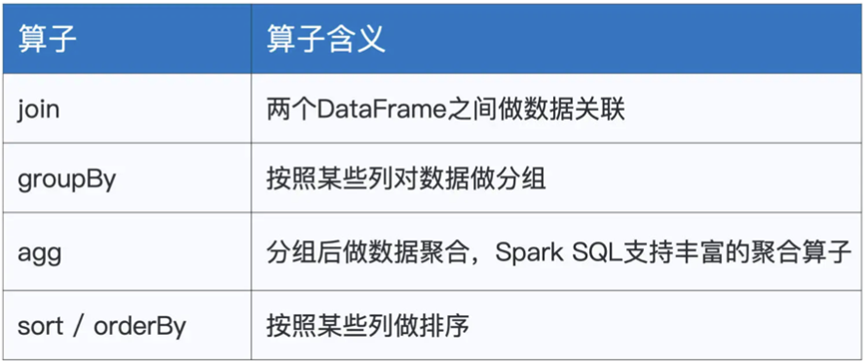
对于join,我们之前演示过,需要我们声明关联键和关联的形式
其次是groupBy,往往配合agg进行使用
比如
Val result = df.groupBy(“gender”).agg(sum(“salary”).as(“sum_salary”))
得到结果
最后是sort或者orderBy两者都是对数据集进行排序,用法和效果是一致的
比如
employeesDF.sort(desc(“sum_salary”,asc(“gender”))).show
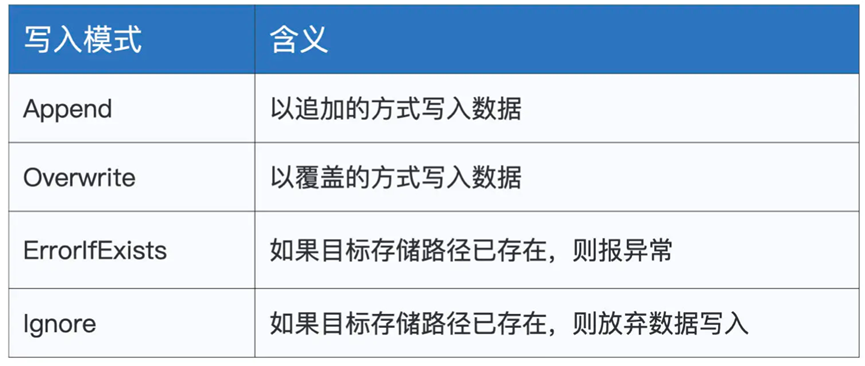
到此,我们除了最后的输出算子都说完了,关于持久化算子,则跟read API类似,都由format定义的文件格式,多个写入选项,以及save路径组成
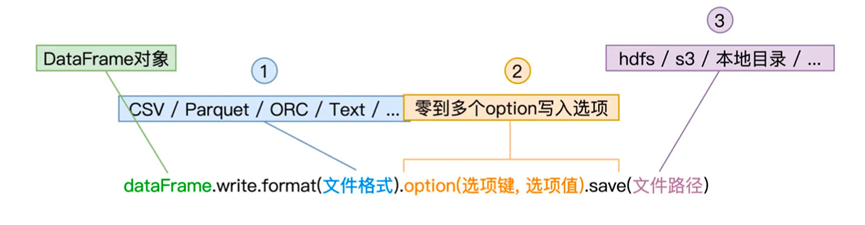
关于不同的option,则可以参考官方文档
比如其中的mode有
总结一下本章,我们讲述DataFrame不同阶段的处理算子
分别是同类算子
探索类算子
清洗类算子
转换类算子
分析类算子
持久化算子