我们学习了Spark SQL中的诸多算子,但在这一讲中,我们将聚焦于其中关于join的支持
Join的种类很丰富,从种类来划分基本可以分为内关联,外关联,左关联,右关联
从实现机制的角度,Join可以分为NLJ,SMJ 和 HJ
Nested Loop join, Sort Merge Join,Hash Join
首先我们准备一些数据
|
import spark.implicits._
import org.apache.spark.sql.DataFrame // 创建员工信息表 val seq = Seq((1, “Mike”, 28, “Male”), (2, “Lily”, 30, “Female”), (3, “Raymond”, val employees: DataFrame = seq.toDF(“id”, “name”, “age”, “gender”) // 创建薪资表 val seq2 = Seq((1, 26000), (2, 30000), (4, 25000), (3, 20000)) val salaries:DataFrame = seq2.toDF(“id”, “salary”) |
上面代码中,我们创建了两个DataFrame,一个用于存储员工信息,另一个存储员工薪资
我们可以通过关联条件id进行拼接
这里我们通过这两个表展示不同的关联形式
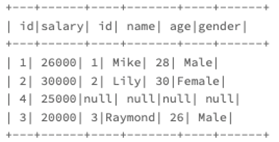
首先是内关联,我们如果想要获取每个人的薪资情况,并且淘汰两个表中的不完整数据,就可以使用内关联,inner
val jointDF: DataFrame = salaries.join(employees, salaries(“id”) === employees(“id”), “inner”)
通过这种方式,我们得到的结果为

可以看出,他分别淘汰了id为4,但没有员工信息的数据和id为5,没有薪资信息的数据
这是因为内关联就是只保存左右表中满足关联条件的数据,由于只有1 2 3 分别有数据,所以结果中也只有 1 2 3
其次是外关联
分别是左外关联,右外关联,全外关联
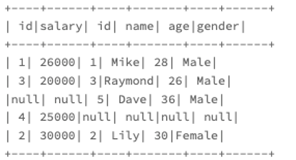
对于左外关联
我们直接看下结果
val jointDF: DataFrame = salaries.join(employees, salaries(“id”) === employees(“id”), “left”)
得到的结果如下
左外关联的结果集,就是左表为基准进行查询,如果匹配不到右表数据,则设为null
同理,右外关联则是正好倒过来
将右表中匹配不到的设置为null
那么全外关联的作用就很明显了
利用full或者outer关键词就可以使用外关联
得到的结果集为
就是即使不匹配上也存在于结果集中,只不过设置为null
那么有了这些外关联之后,我们可以看下关于左半关联,以及左逆关联
Left Semi Join/Left Anti Join
实际上,左半关联的就是保留了,左表中符合关联条件的数据记录,如下所示
val jointDF: DataFrame = salaries.join(employees, salaries(“id”) === employees(“id”), “left_semi”)
得到的数据集如下

左逆关联则是指保留不符合关联关系的数据
最后是从关联机制上进行讲述,一开始我们也说了有三种实现机制,分别是NLJ,SMJ以及HJ
我们以内关联为例,我们还是拿上面的数据进行讲解

首先是NLJ,Nested Loop Join,我们通常会将join涉及的两个表称为驱动表和被驱动表
实际的实现就是,两层for循环,在外层循环驱动表数据,内层则去判断被驱动表是否有匹配数据
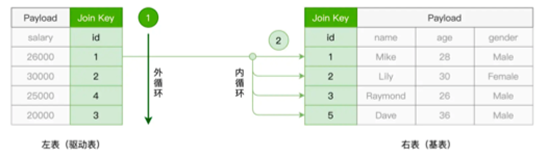
这样的一个NLJ的负责度就是O(M*N)
其次是SMJ, Sort Merge Join
进行线排序,再归并。给定参与关联的两个表,SMJ则先把他们进行排序,然后使用独立的游标,然后将两个排好序的表做归并关联

具体流程为,分别在两个表上有一个下标
然后进行匹配,如果两个id值相同,进行拼接,并移动两表的下标
如果id不同,则移动id小的表的下标
基于这个概念,当某个表的下标到了尽头,就完成关联了
这样的复杂度是O(M+N),虽然很低,但是依赖于两个表事先排好序,这一点的要求就很高
最后是Hash Join
利用一个Hash字段进行拼接
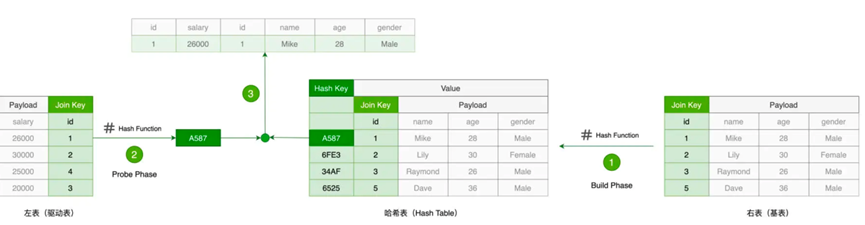
HJ的计算阶段分为了Build和Probe,Build阶段在被驱动表上构建Hash字段,然后在Probe阶段,则在驱动表上遍历,计算Hash值,然后去被驱动表上查询,当一致的时候则进行比对实际值,实际值一致则拼接后输出
那么到此为止,我们说了三种Join的实现机制,我们接下来说下,如何利用这些机制进行数据关联
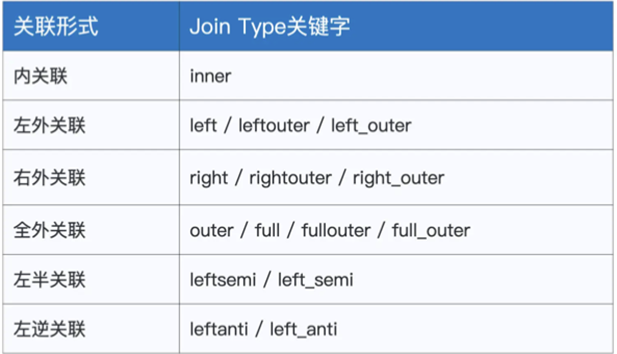
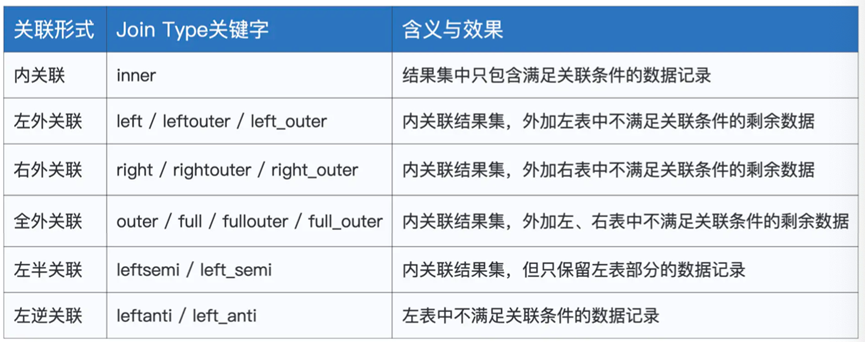
不过到此我们先总结下,我们说下Spark SQL中支持的Join算子,不同算子关联形式不同,总结如下表
其次又说明了Join的三种实现机制,分别是Nested Loop Join,Sort Merge Join和Hash Join
