我们说一下消息队列的生产和消费两个核心的流程,在其中大部分的消息队列中,流程是一致的,通过这次学习,我们可以掌握并理解消息队列收发消息的问题
本次是Kafka消费者的源代码,理解kafka的消费实现过程
Kafka的消费模型中的几个特点
Kafka的每个消费者Consumer属于一个消费组ConsumerGroup
消费的时候,CosumerGroup的每个Consumer独占一个或者多个Partition分区
对于每个ConsumerGroup,任意时刻,每个Partition至多有一个Consumer在消费
每个ConsumerGruop都有一个Coordinator协调者负责分配Consumer和Partition的对应关系
每当Partition或者Consumer发生改变的时候,其会重新分配
Consumer利用心跳请求维持的Coordinator的关系,方便出现故障及时触发rebalance
那么我们看一下Kafka相关的文档
https://kafka.apache.org/10/javadoc/?org/apache/kafka/clients/consumer/KafkaConsumer.html
这里给出了Kafka的Consumer最简化消费代码
Properties props = new Properties();
props.put(“bootstrap.servers”, “localhost:9092”);
props.put(“group.id”, “test”);
props.put(“enable.auto.commit”, “true”);
props.put(“auto.commit.interval.ms”, “1000”);
props.put(“key.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”);
props.put(“value.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(“foo”, “bar”));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf(“offset = %d, key = %s, value = %s%n”, record.offset(), record.key(), record.value());
}
上述代码的流程基本为
1.设置必备的配置信息,配置了Broker,Consumer Group的ID,自动提交消费位置,序列化配置
2.创建了一个Consumer的实例
3.设置了两个Topic foo bar
4.循环拉取消息
在上述的整体流程中,主要涉及的流程分为了 订阅 and 拉取消息
那么我们首先看一下订阅的流程如何实现
1.订阅的流程
我们先看下subscribe这个函数
//代码2:
@Override
public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) {
acquireAndEnsureOpen();
try {
maybeThrowInvalidGroupIdException();
if (topics == null)
throw new IllegalArgumentException(“Topic collection to subscribe to cannot be null”);
if (topics.isEmpty()) {
// treat subscribing to empty topic list as the same as unsubscribing
this.unsubscribe();
} else {
for (String topic : topics) {
if (topic == null || topic.trim().isEmpty())
throw new IllegalArgumentException(“Topic collection to subscribe to cannot contain null or empty topic”);
}
throwIfNoAssignorsConfigured();
fetcher.clearBufferedDataForUnassignedTopics(topics);
log.info(“Subscribed to topic(s): {}”, Utils.join(topics, “, “));
if (this.subscriptions.subscribe(new HashSet<>(topics), listener))
//元数据更新
metadata.requestUpdateForNewTopics();
}
} finally {
release();
}
}
上述代码,简化为
1,调用了保证线程安全的方法
2.进行参数校验.去掉空格等操作
3.重新进行订阅了
4.更新了元数据,包括集群的Broker节点等信息
主要是重置了订阅状态,然后更新了topic信息,订阅状态subscriptions维护了订阅的topic和patition的消费信息,
然后metadata中维护了Kafka的一个子集,包含了集群的Broker节点,Topic,Partition信息
上面中,有acquireAndEnsureOpen 和 try-finally release()
保证单线程运行
这也是为Consumer不是线程安全的,避免出现问题
我们增加健壮性的方式
我们看下acquireAndEnsureOpen 这个函数的实现
本质上是调用了acquire函数,而acquire函数代码如下
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException(“KafkaConsumer is not safe for multi-threaded access”);
refcount.incrementAndGet();
}
我们尝试的获取线程,并比较,不相等的时候并尝试将并发线程设置为当前线程id,然后将引用数加一,失败则quick false
然后在最后进行release,释放线程
private void release() {
if (refcount.decrementAndGet() == 0)
currentThread.set(NO_CURRENT_THREAD);
}
release中则是将引用数减一,如果为0了,则设置为可并发模式
然后我们更新元数据中的metadata.setTopic()函数,我们更新了Metadata的Topic之外,还调用metadata.requestUpdate()方法请求更新元数据
在requestUpdate函数中,我们发现,其实没有真正的更新元数据的请求,只是将needUpdate这个标志位设置为了true就结束了,Kafka必须要在第一次拉取消息之前更新一次元数据
public synchronized int requestUpdateForNewTopics() {
// Override the timestamp of last refresh to let immediate update.
this.lastRefreshMs = 0;
this.needPartialUpdate = true;
this.requestVersion++;
return this.updateVersion;
}
上述订阅的流程中,我们没有和网络有任何的交互
更新了订阅状态subscriptions和元数据metadata的相关topic的一些属性,元数据设置为了需要立刻更新,没有真正的发送更新请求
真正的更新则是在poll流程中
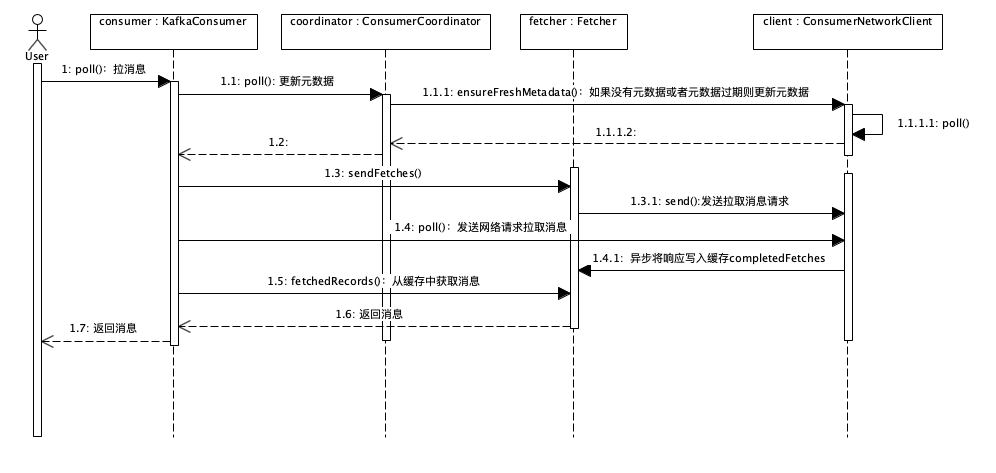
我们看一下源码流程
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException(“Consumer is not subscribed to any topics or assigned any partitions”);
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
// try to update assignment metadata BUT do not need to block on the timer for join group
updateAssignmentMetadataIfNeeded(timer, false);
} else {
/*
updateAssignmentMetadataIfNeeded方法有3个作用:
– discovery coordinator if necessary
– join group if necessary
– refresh metadata and fetch position if necessary
*/
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn(“Still waiting for metadata”);
}
}
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
poll中我们分别调用了
我们指定的事件内不断的进行工作,上来进行元数据的同步,这一步利用了updateAssignmentMetadataIfNeeded() 更新元数据
boolean updateAssignmentMetadataIfNeeded(final Timer timer, final boolean waitForJoinGroup) {
if (coordinator != null && !coordinator.poll(timer, waitForJoinGroup)) {
return false;
}
/*
Set the fetch position to the committed position (if there is one) or reset it using the offset reset policy the user has configured.
*/
return updateFetchPositions(timer);
}
这里的操作,主要是去发现coordinator
加入一个组
刷新metadata
在其中,我们调用了coordinator.poll(),内部代码如下
public boolean poll(Timer timer, boolean waitForJoinGroup) {
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.hasAutoAssignedPartitions()) {
if (protocol == null) {
throw new IllegalStateException(“User configured ” + ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG +
” to empty while trying to subscribe for group protocol to auto assign partitions”);
}
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
pollHeartbeat(timer.currentTimeMs());
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
if (rejoinNeededOrPending()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster’s topics at least once before joining.
if (subscriptions.hasPatternSubscription()) {
// For consumer group that uses pattern-based subscription, after a topic is created,
// any consumer that discovers the topic after metadata refresh can trigger rebalance
// across the entire consumer group. Multiple rebalances can be triggered after one topic
// creation if consumers refresh metadata at vastly different times. We can significantly
// reduce the number of rebalances caused by single topic creation by asking consumer to
// refresh metadata before re-joining the group as long as the refresh backoff time has
// passed.
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
// if not wait for join group, we would just use a timer of 0
if (!ensureActiveGroup(waitForJoinGroup ? timer : time.timer(0L))) {
// since we may use a different timer in the callee, we’d still need
// to update the original timer’s current time after the call
timer.update(time.milliseconds());
return false;
}
}
} else {
// For manually assigned partitions, if there are no ready nodes, await metadata.
// If connections to all nodes fail, wakeups triggered while attempting to send fetch
// requests result in polls returning immediately, causing a tight loop of polls. Without
// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.
// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.
// When group management is used, metadata wait is already performed for this scenario as
// coordinator is unknown, hence this check is not required.
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
然后在updateAssignmentMetadataIfNeeded()函数中,调用了coordinator.poll()方法
poll()方法中调用了client的ensureFreshMetadata()方法,其中还调用了client.poll()方法,实现和Cluster通信,Coordinatro上注册Consumer并拉取和更新元数据
client.poll代码如下
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup) {
// there may be handlers which need to be invoked if we woke up the previous call to poll
firePendingCompletedRequests();
lock.lock();
try {
// Handle async disconnects prior to attempting any sends
handlePendingDisconnects();
// send all the requests we can send now
long pollDelayMs = trySend(timer.currentTimeMs());
// check whether the poll is still needed by the caller. Note that if the expected completion
// condition becomes satisfied after the call to shouldBlock() (because of a fired completion
// handler), the client will be woken up.
if (pendingCompletion.isEmpty() && (pollCondition == null || pollCondition.shouldBlock())) {
// if there are no requests in flight, do not block longer than the retry backoff
long pollTimeout = Math.min(timer.remainingMs(), pollDelayMs);
if (client.inFlightRequestCount() == 0)
pollTimeout = Math.min(pollTimeout, retryBackoffMs);
client.poll(pollTimeout, timer.currentTimeMs());
} else {
client.poll(0, timer.currentTimeMs());
}
timer.update();
// handle any disconnects by failing the active requests. note that disconnects must
// be checked immediately following poll since any subsequent call to client.ready()
// will reset the disconnect status
checkDisconnects(timer.currentTimeMs());
if (!disableWakeup) {
// trigger wakeups after checking for disconnects so that the callbacks will be ready
// to be fired on the next call to poll()
maybeTriggerWakeup();
}
// throw InterruptException if this thread is interrupted
maybeThrowInterruptException();
// try again to send requests since buffer space may have been
// cleared or a connect finished in the poll
trySend(timer.currentTimeMs());
// fail requests that couldn’t be sent if they have expired
failExpiredRequests(timer.currentTimeMs());
// clean unsent requests collection to keep the map from growing indefinitely
unsent.clean();
} finally {
lock.unlock();
}
// called without the lock to avoid deadlock potential if handlers need to acquire locks
firePendingCompletedRequests();
metadata.maybeThrowAnyException();
}
然后ConsumerNetworkClient封装了Consumer和Cluster之间的网络通信
一个彻底的一步实现,所有待发送的Request放在属性unsent,返回的Response放在属性pendingCompletion中,每次调用poll,发送所有的Request,处理所有的Response
这样,我们利用异步设计的优势来很少的线程实现高吞吐量,但劣势也很明显,增加了代码的复杂度,
其实,更新消费位置的方法,也是在updateAssignmentMetadataIfNeeded()函数中,
其中调用了KafkaConsumer.updateFetchPositions(timer)
然后又会调用coordinator.refreshCommittedOffsetsIfNeeded()
然后是拉取消息的pollForFetches()的实现
|
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) { // 省略部分代码 // 如果缓存里面有未读取的消息,直接返回这些消息 final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords(); if (!records.isEmpty()) { return records; } // 构造拉取消息请求,并发送 fetcher.sendFetches(); // 省略部分代码 // 发送网络请求拉取消息,等待直到有消息返回或者超时 client.poll(pollTimer, () -> { return !fetcher.hasCompletedFetches(); }); // 省略部分代码 // 返回拉到的消息 return fetcher.fetchedRecords(); } |
在这串代码中
我们首先看缓存中有未读取的消息,直接返回
构造拉取消息请求,发送
发送网络消息等响应
返回拉取到的信息
实际逻辑在sendFetchs实现类中,根据元数据的信息,构造所有需要的broker的拉消息的Request
public synchronized int sendFetches() {
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget())
.rackId(clientRackId);
log.debug(“Sending {} {} to broker {}”, isolationLevel, data, fetchTarget);
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
// We add the node to the set of nodes with pending fetch requests before adding the
// listener because the future may have been fulfilled on another thread (e.g. during a
// disconnection being handled by the heartbeat thread) which will mean the listener
// will be invoked synchronously.
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
try {
@SuppressWarnings(“unchecked”)
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error(“Unable to find FetchSessionHandler for node {}. Ignoring fetch response.”,
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry : response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat(
“Response for missing full request partition: partition={}; metadata={}”,
new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat(
“Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}”,
new Object[]{partition, data.metadata(), data.toSend(), data.toForget()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponse.PartitionData<Records> partitionData = entry.getValue();
log.debug(“Fetch {} at offset {} for partition {} returned fetch data {}”,
isolationLevel, fetchOffset, partition, partitionData);
Iterator<? extends RecordBatch> batches = partitionData.records().batches().iterator();
short responseVersion = resp.requestHeader().apiVersion();
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion, resp.receivedTimeMs()));
}
}
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
}
return fetchRequestMap.size();
}
最后,fetcher.fetchedRecords()方法,将返回的Response反序列化转换给消息列表,给调用者
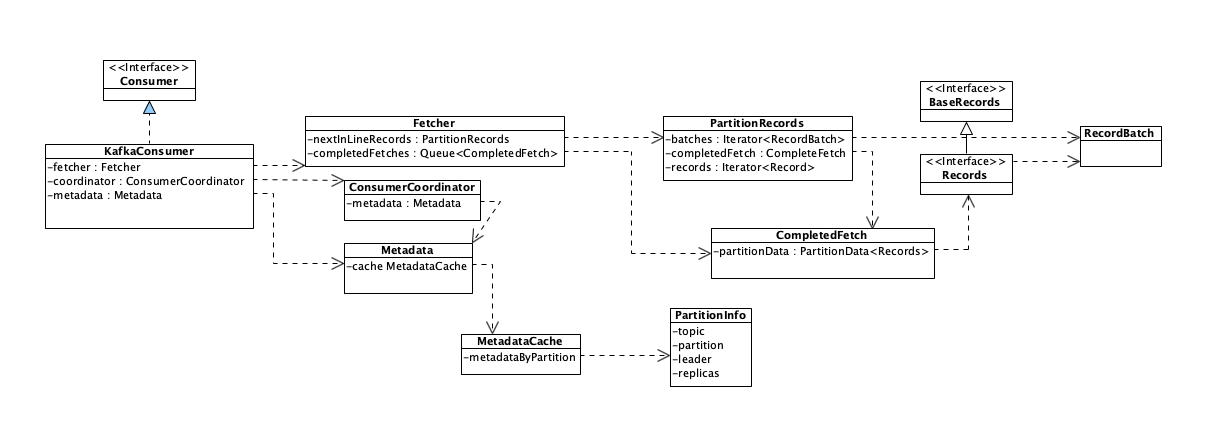
上面流程整体为
构建Request对象,存入发送队列,不会立刻发送,而是等待时机批量发送,然后用回调或者RequestFuture的方法,预先定义好处理响应的逻辑
收到Broker的相应,也是暂时存在队列中,择机处理,这个择机处理的逻辑很复杂,可能是读取相应,或者缓冲区慢了,或者时机到了