基础数学课13-朴素贝叶斯和文本分类
上一章我们讲了,如果需要建立一个完整的贝叶斯流程
需要进行样本采集,数据处理,数据预测
而引入到文本分类,则是需要采集样本,预处理自然语言,训练模型,进行预测
和基本的贝叶斯不同的是,在文本分类中,需要增加一个预处理自然语言的流程。
在自然语言的处理流程中,首先我们需要了解如何将文本中的文字和特征关联起来,最为简单的方式是通过找关键词的方式获取,也就是词袋模型。
忽略文本中的词语出现的顺序,只查看其的出现次数。从而将其和特征挂上钩。
那么我们就需要看如何从文本中提取关键词了,这就需要考虑分词方式,而分词需要考虑不同语言的特征,比如中文,我们在书写的时候没有直接的分界,往往以句子为单位。而英文,则是以空格为分界。
除此外,常见的分词模型有着,基于字符串匹配的模型,和基于统计和机器学习的模型。基于字符串匹配的模型一般就是最大正向匹配和逆向最大匹配的长词优化等。
基于机器学习的,基于人工标注的此行,来对中文建模,从而统计各种分词的概率。一般有隐马尔科夫模型和条件随机场模型。
在获取词干的同时,我们还可以使用归一化等操作进行辅助,比如将单复数的形式进行转换,转换为统一的形式。
对于停用词,比如a an 你,个 这个样的单词可以进行忽略。
还有就是同义词的转换,比如番茄等于西红柿,但需要注意一些特点,比如某些词相同但是具有歧义,这需要设定特定的操作。
在之后,我们就可以将单词作为属性,配合文章分类,获取到文章数量。
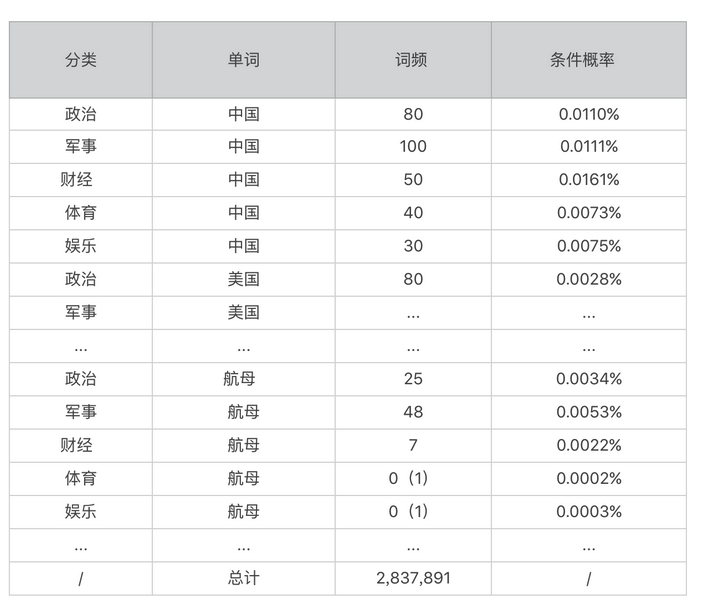
在这里面,我们同样需要处理为0的值,处理为一个极小的值
之后我们就可以计算中国,航母在不同分类中的概率。

从而进行计算。
如果我们包含的不同单词数量超过两个,就需要进行更多的计算
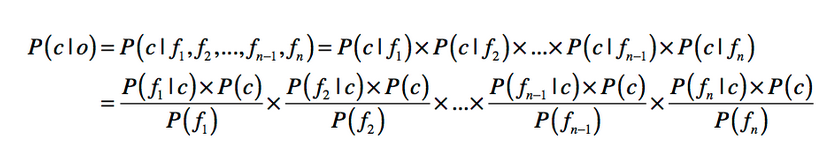
在此过程中,如果单词非常的多,会导致连续乘积,最后会趋近于0无法识别。
为此我们可以使用log来进行数学变化。