之前,无论是分布式系统架构中存在的副本切换问题,还是事务的出现,都是在表达一个概念,那就是在系统中故障不可避免
虽然存在着乐观事务,但在实际设计的时候,设计者往往都会将悲观主义无限放大。假设可能存在任何出错的场景。
那么本章我们就讨论一个现代软件可能遇到的问题,首先是讨论分布式和单节点之间的故障区分
其次是网络问题,时钟问题,拜占庭将军问题。
那么对于单节点和多节点的软件
单个计算机上的软件没有根本性地不可靠原因,如果硬件任何一环出现了问题,比如内存,硬盘,那么后果通常是整个系统级别的故障,要么完全失效,要么完全正常,不会出现两者之间的情况
同样一个软件也是,如果没有bug,那么他往往也是固定的。
但是对于一个分布式的软件,情况则完全不同,任何情况都会导致问题的出现,比如部分服务器失效,部分断电等。
由于存在部分失效的可能性,使得分布式系统难以工作的。
为了使得这个分布式系统工作,需要接受部分故障的可能性,并在软件中建立容错机制,也就是组件不可靠,但是要求系统整体可靠。
简单的假设故障很罕见从而保证乐观是不明智的,需要考虑一系列可能的错误,并在测试环境中人为的测试这些情况。
就好比,我们在互联网协议之上引入了TCP协议,从而确保了丢失的数据包将被重新传输,但是这并不能彻底消除网络的不可靠性
那么作者在第二部分就讨论关于网络的不可靠性,这里我们简单的提一嘴。
在一个大型系统中,网络往往是首选的通信方式,因为其不需要特殊的硬件就可以做到
但是网络必然带来了不稳定性,因为在一个互联网上传输带来了太多的不确定性。除了得到特定的响应从而判断请求完成,似乎没有什么好的办法去标记请求完成。
而网络故障又是其中最为常见的故障问题,往往由现实生活中的硬件故障造成的。
而面对网络故障,往往需要做的就是将节点移除服务列表,如果是主库还需要升级从库。当然这些我们之前都有聊过,这里我们将讨论检测网络故障最常见的方式,超时检测,
长时间的超时意味着长时间的等待,如果一个节点已经早早死去,那么设置一个长时间的超时时间意味着用户需要等待很长的一段时间。短超时时间意味着更快检测到异常,但是也会在高负载情况下错误的将节点宣布为失效。 这很有可能造成一个动作被反复执行的问题。
理想状态下,数据包假设有一个最大的延迟为d, 接收方处理的最大时间为r,那么超时时间被设置为2d+r是最理想的,但是大多数系统是不具有这样的保证。
这里坐着还提了一嘴TCP和UDP的区别,TCP利用了窗口协议.做到了流量控制
而UDP没有进行流量控制,而是不断的进行向外发送
TCP适合于发送关键信息,而UDP更加适合于语音会议这种对丢包不敏感的场景。
最后我们讨论了同步网络和异步网络
同步网络常见于一些运营商内部网络,比如打电话,就会建立一个长连接,这个长连接会在路线上占用固定的带宽从而满足通信,因为有固定的贷款,所以延迟也可以确定
但是实际的网络中,我们往往无法满足这个固定带宽的硬件需求。
因为这种同步网络,往往需要分配固定带宽,即使你根本用不到这么多的带宽。
而异步网络是我们常见的网络使用方式,也就是尽可能的压榨带宽上限,一旦有剩余就立刻发包。
但是网络的异常由于对于网络封装比较好,那么对于数据库开发人员,往往需要考虑的就是数据库出现节点下线的情况。
其次是时钟问题
因为应用程序往往依赖于本地机器上的时间,而且在应用程序中往往存在着,统计服务的响应时间,用户请求间隔,文章发布时间,何时发送邮件,缓存过期时间
上面常见的时间问题中,既存在测量持续时间,又存在描述特定时间点的问题
那么我们也就分别看看这两种时间问题的解决方案,不过再次之前,我们需要说明下,在服务器上,时间的概念往往来源于一个实际的硬件设备,也就是石英晶体振荡器,不过这个并不是完全准确的,因为硬件设备可能存在的或快或慢的问题,所以引入了NTP网络时间协议,可以根据一组服务器报告的时间来调整计算器时钟。
讲解了NTP的概念之后,我们可以说明在服务器中时间可能出现的最常见问题
也就是由于存在NTP,所以可能在NTP和本地服务器同步的时候,修改本地服务器时间,从而导致我们通过System.currentTimeMillis()获取到的日历时钟需要和NTP进行同步,这就意味着其可能存在着时间回跳的可能性,但是这样也能保证了日志时间戳的可靠性
如果是希望进行一个单调的持续时间计算,可以通过System.nanoTime进行计算
这个获取的是计算机启动之后的纳秒数,但总归是单调向前的,对于这一个特性,测量经过时间通常很好。
那么我们看些常见的时间故障
常见就是机器上的石英钟不准,导致可能慢个百万分之一,但是日积月累这就是很大了
或者计算机的时钟和NTP的时钟差别太大了,拒绝了同步
以及因为距离NTP过于遥远,导致网络同步出现了延迟
闰秒问题,导致一分钟可能有59或者61秒
由于这些问题,所以在考虑分布式系统的同步时间戳的时候,需要进行考虑
毕竟一个机器的硬件出现了问题往往就直接系统级的崩坏了,而时钟出现问题,往往出现的问题会是悄无声息的
最常见的同步问题,比如分布式中,往往存在着对同一个节点进行修改,但是在实际中A事件比B事件先发生,但是B的时间戳早于A的,导致B的数据反被A覆盖了
这种情况下,也是分布式数据库的常见问题
对于这种具有事务的分布式数据库中,都存在一个事务中心,负责生成全局的事务ID,利用单一的事务中心来进行ID的分配
如果没有这样一个事务中心呢,Goggle的Spanner给出了一个新的解决方式
毕竟时钟可能存在一个置信区间,就是存在的偏差范围,最早的时间戳和最晚的时间戳
如果存在两个区间,利用这两个区间的最早和最晚时间戳,可以确定区间是不是重叠和先后顺序
那么spanner在读写事务的时候,会故意等待置信区间长度的时间,确保不会重叠。
最后就是硬件上,由于CPU的多线程性,可能存在的线程暂停的问题
比如我们的分布式系统,如果是一个一主多从的架构,其中的主线程因为暂停导致没有发出心跳响应,可能导致领导者选举
这种挂起的情况并不少见,比如Java中可能存在的长GC,比如虚拟化环境中的挂起和恢复
比如上下文切换导致的超时
这就导致一个分布式系统中,可能由于各种各样的问题导致某一节点断连,但是世界的其他部分还需要继续运转的。
但是往往很多系统要求必须具有实时响应的能力
就好比,你不希望汽车出故障了,安全气囊因为GC没弹出来吧
这种实时保证需要各级的软件栈的支持,一个实时操作系统RTOS,可以在指定的时间间隔内提供CPU时间的分配,确保各个线程能够得到时间分配,这种就好比上面讲的网络的分配,需要提前预留好,保证及时响应。
本章到了现在,已经可以从网络和时钟两个方面看出来分布式系统的不可靠性,
也正因为不可靠性,导致在系统中无法知道什么是真,什么是假。但是我们可以建立一个模型,并假定在某些情况下,模型会按照预期的方式执行。从而提供一定的保证。
首先就是,可能存在的单节点故障问题,无论这个故障是怎么导致的,可能节点没有问题,只是网络问题,但是外在表现就是节点故障,这种情况下,往往依赖于多数人投票,如果单个节点出现了故障,那么只要多数法定节点可以执行,整个系统仍然是安全的,那么即使这个节点只是短暂的线程暂停,那么他也要服从多数的决定。
那么聚焦到内部,比如到数据之中,往往数据中具有很多着唯一性,比如领导者节点,比如对某一对象的锁,比如主键,那么假设某些人本身拥有着这些唯一性,结果因为网络故障等原因,导致唯一性丧失。那么他在恢复之后的动作就是需要注意的点,如果他不知道自己已经丧失了这个唯一性,仍然把自己当成拥有者来执行,必然会损坏数据。
那么对于这种问题,常见的解决方案可以是让锁或者领导者带有版本
这样假设某一节点之前获取过令牌,但是发生暂停之后再去进行操作,也会因为令牌过期而废弃
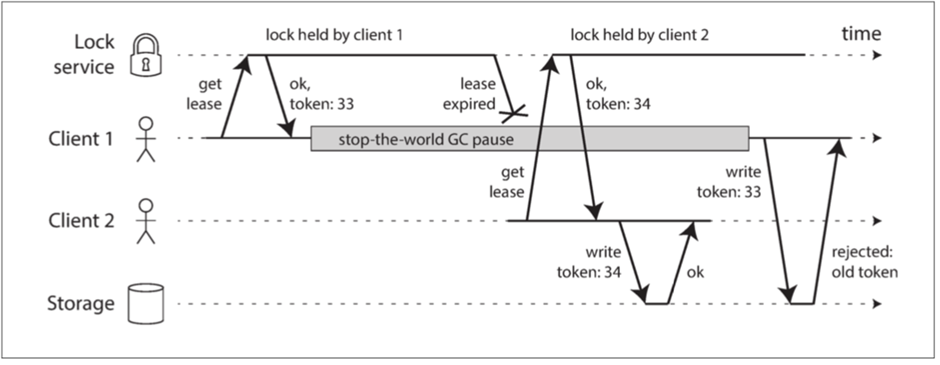
其次,上面我们讨论的问题,都是建立在节点可能出现错误,但是给出的响应总是诚实的,可能很慢,可能从不响应,但只要做出的回应,总归是建立在真实情况之上的。
但如果节点存在说谎的情况呢? 也就是常说的拜占庭将军问题
可能节点因为某些硬件出现错误,或者分布式系统中某一节点已经被攻破。导致得到的响应式错误的,对于拜占庭问题,当然存在一些协议去解决拜占庭问题。
不过这些协议大多数要求大部分节点能够正常工作。而且其中大部分的实现都是成本极其高的
虽然拜占庭问题本身比较难以解决,但是对于可能存在的硬件问题,还是需要进行解决和配置的,比如 对于网络数据包进行校验,检查用户的输入,配置多NTP服务器来同步时间
最后作者给出了分布式系统的常见系统模型,
从时序的角度来说,分别是同步模型,部分同步模型,异步模型
从节点失效的角度来说,也存在着 崩溃-停止故障 崩溃-恢复故障 拜占庭保证(强而有力,对任何故障都有保证)
其次,对于系统的架构,要分为两种不同的属性 安全属性和活性属性
安全要求的不会在正常情况出现的问题,比如唯一性,唯一性保证正常不会出现,二一旦出现了就是问题,而且不可撤销
活性就好比最终一致性,对于一种分布式系统中,是一种被考虑,被容忍的问题,在某一时刻可能不成立,但是最终会成立。
根据上面的说明,那么一个系统中,始终保持安全属性是常见的,这要求即使所有节点崩溃,也不能破坏安全性
而活性属性,则需要注意,思考,以及维持。
最后总结下本章
分别说了网络和时钟的问题
利用这两点,我们证明了分布式系统中的系统不可靠性,也因为此,我们需要建立一个部分失效的容错机制。往往利用的多数法定人的原则。
最终也是说的,分布式系统中的不同模型,和不同的容忍级别。