对于事务,这一章的开篇词很有意思,表示了虽然分布式事务中的二阶段提交很消耗性能,但是远比不提供事务能力来说好得多。
而事务,作为一个我们的老朋友并不陌生,毕竟在数据系统中,存在着很多隐藏着的问题,比如数据库软件或者硬件的崩溃,或者网络中断问题,以及多个客户端同时写入
对于这类问题,业界公认的是使用事务来简化,将多个读写操作形成一个逻辑单元,对外具有隔离性,对内则是成功提交则全提交,要是失败则回滚。
虽然事务很好,但是也带来了性能损失,有时候就直接不提供事务供使用,从而加快速度
而且对于分布式数据库,事务的实现也有着更加困难的问题。
那么本章作者先讲述了事务面临的各种挑战,并讲述了数据库的不同隔离级别
在事物中,最重要的概念就是ACID,分别代表着原子性(Atomicity),一致性(Consistency),隔离性(Isolation) 和 持久性(Durability)
但是实际上,对于ACID的实现没有一个良好的规范,所以一个系统生成自己符合ACID的时候,并不能得到一个良好的保证,而且后来还提出了BASE理论, 代表 基本可用性(Basically Available),软状态(Soft State) 和 最终一致性(Eventual consistency)。但这实在是太模糊了,这里不给予讨论。
这里作者也是先说了ACID的概念
原子性并不是关于并发的,而是一个客户端产生多个操作,如果成功,那么多个操作都会成功,如果失败,那就中止或者回滚。如果没有原子性,那么就很难知道哪些操作已经生效了,有了原子性,即使出错了也能安全的重试。
一致性则是一个广泛的,没有明确定义的词,比如副本一致性的概念,比如一致性哈希对应的分区
比如CAP中的一致性,在ACID中,作者给出的观点是,这个不变式意味着由应用程序维护的业务一致性,比如一个账户的支出和另一个账户的收入就是要具有一致性地。
隔离性则是面对并发问题的,如果多个客户端进行请求,各自执行事务,那么他们执行的事务应该是相互隔离的,这意味着多个事务提交的时候,应该是互不影响的,这类的实现可以是串行化的,也可以是快照隔离的,比如Oracle或者MySql
最后的持久化,表示的会有一个安全的地方存储数据,保证不会发生数据丢失。
不过无论存在哪里,无论是分布式还是单点式的,都没有完美的持久性,都具有着某些非常小的可能性出现持久性故障
而且在事务中,单对象的操作和多对象也是不同的
一般单节点数据库中,指的事务都是多对象事务,,也就是同时修改多个对象
比如我们在加入一条邮箱的未读时候,往往还会更新一个计数器,那么在修改的时候肯定是同时修改两个,如果是具有原子性和隔离性,那么在更新过程中,如果计数器更新和插入都生效的时候,才可以让用户读到,在常见的数据库中,BEGIN TRANSACTION和COMMIT语句之间的内容,都会被认为是同一事务的一部分。
多对象事务的存储在分布式数据中很少有人实现,主要是比较难以实现,但并非不可实现
而且比如在多节点的数据库中,往往需要维护索引,索引和数据之间的更新就是一个事务,这就是对于事务的需求
那么事物关键的特性,就是为了数据可以安全的重试,但是这个重试也是需要分情况的,比如本身数据就是有错误的,那么也就意味着没有什么重试的价值了。
最后作者也提到了原子操作,也就是某些数据库提供的CAS,这一点在编程语言乃至CPU中都有使用,不过在ACID中,并不是那么绝对,并不能将其完全称为ACID,因为其只是一种对单一对象操作的轻量级事务。事物还是指的是将多个对象的多个操作合并为一个执行单元的机制。
那么其次作者对于ACID中重要的一环,隔离性进行了探讨,因为可能存在并发的隐患,所以需要解决并发的冲突,对于这一个最好的解决方式就是通过事务隔离,最强大的隔离方式就是串行化,但是串行化由于存在性能损失,所以也是引入了其他方式的隔离实现,并实现了不同级别的隔离。
那么接下来一段,作者也是展示不同级别的隔离实现,并分析可能存在的问题。
首先是读已提交
读取的时候只能看到已经提交的数据
写入数据的时候只会覆盖已经写入的数据
如果无法保证读取到事务正在运行中间态的数据的话,被称为读未提交。
那么如何保证避免上面的脏读和脏写呢?
对于脏写,可以考虑给对应的行上加上行锁,row-level lock,如果希望修改哪些行的话,则需要首先获取这个对象的锁。并在读取之后立刻释放这个锁,这就数据在事务过程中不会被其他事务篡改。
那么对于脏读呢?当然可以使用类似写锁的方式,加上读锁,确保数据在具有未提交值得时候不会发生读取。但是由于读取的操作往往多于写入的操作
所以利用读锁来避免脏读也是慢慢被淘汰了,现在主流的使用方式是记录多个版本的值,事务进行的时候,其他读取获取到的是事务开始前的旧值,只有提交之后,才能读取到新的值。
那么讲完了简单的脏读,脏写,读已提交之后,我们可以说下快照隔离和可重复读了。
因为读已提交并不能避免不可重复读问题,也就是我本身处于一个事务中,我在我这个事务中看到了其他人已提交的结果,导致我的操作出错。
这个错误经常发生在,备份整个数据库,我应该看到一个一致性的视图。
为了避免这个问题,应该给一个事务生成一个一致性快照,事务可以看到事务开始之前的数据库提交的所有数据,即使数据随后被另一个事务更改。
而这个一致性隔离是一个很流行的功能,PostgreSQl,MySQL都有支持。
对于这个一致性隔离,本身就是采用了MVCC,多版本并发控制,对于一行,或者一个字段的值,维护多个版本,对于读已提交,则是维护着提交的版本和未提交的版本,对于可重复读,则为每一个事物维护着一个版本。比如下面的
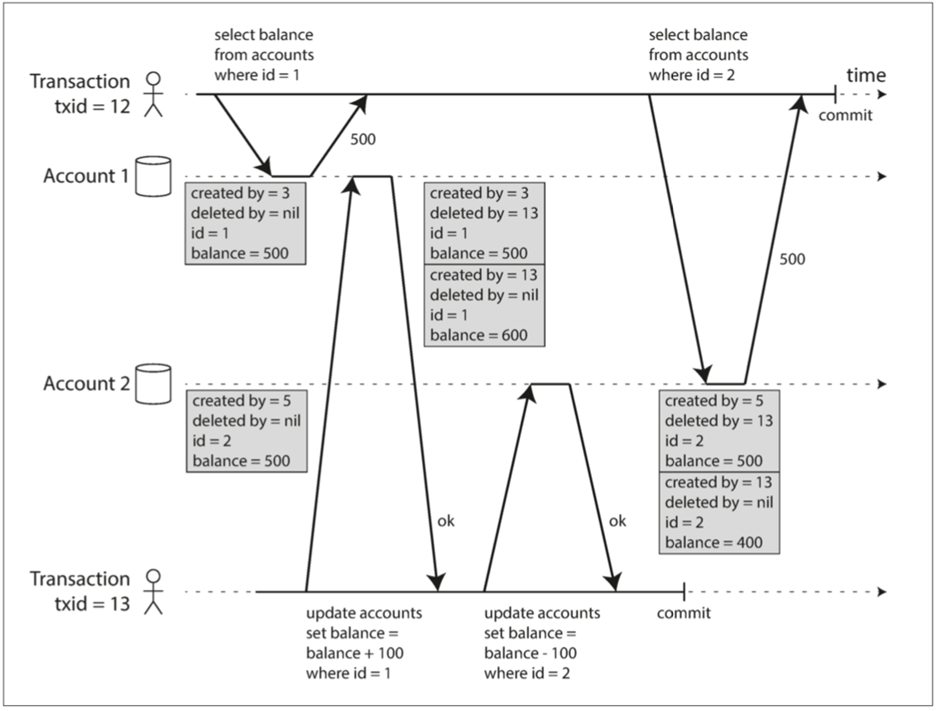
利用一个字段trx_id来表示不同的事物版本,有了这个字段,事务ID可以决定其可以看见哪些对象,看不见哪些对象
每次事务开始的时候,数据库都列出所有的事务清单,所有在这个列表中的事务即使提交了也不可见
中止事务所执行的任何写入都不可见
具有较晚事务ID的写入也是不可见的
对于本事务产生的变更时可见
利用这些规则,从而避免了不可重复读的问题。
那么在这种情况,索引的使用可以是指向所有版本的值,根据版本进行筛选
或者利用Copy on write来进行写时复制
这样的一个快照隔离的机制,在不同的数据库中的叫法是不同的,在Oracle中称为可串行化,在MySQL和Postgre中称为可重复读,不过本质都是一个概念
再有了隔离级别之后,对于数据书写,还有一个问题,就是对于同时写入,是否会造成数据丢失呢?
之前我们给出的解决方案是LWW,Last Write Win
对于事务而言,可能存在着不同的情况
简单来说,如果是更新一个账户余额
这种方式可以使用原子写来解决,简单来说就是CAS,不过需要注意,有些ORM不会利用数据库自带的原子性操作
除此外就是加锁,利用加锁从而做到读取同一个对象的时候,会进行排队等待,直到第一个读取完成。
最后作者讲述了一些极端情况,
比如一个医院要求至少一个医生值班,但是如果他们同时点击下班,可能会导致
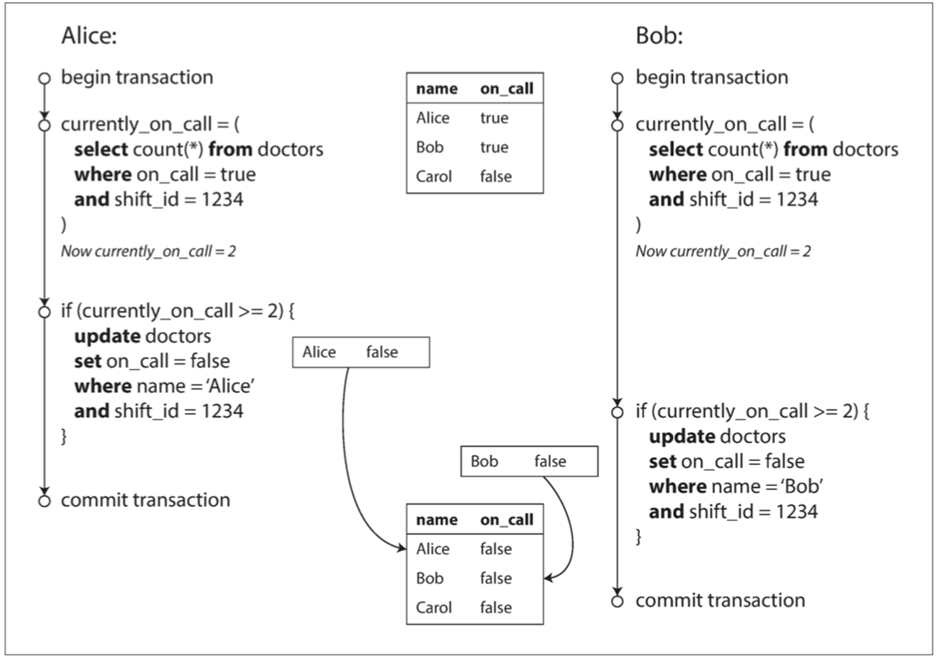
先查询有多少剩余大夫,这里都查到了2,然后都设置自己为下班的状态,导致科室无人值守。
这种异常称为写偏差,因为更新的是两个不同的对象,而约束条件体现在数据库系统之外,而非数据库内部。
对于这种情况,可以考虑加入一个科室级别的对象,从而做到一个科室级别的串行化,比如下面的流程,这样一个科室内部点击下班都会依次运行
| BEGIN TRANSACTION;
SELECT * FROM doctors WHERE on_call = TRUE AND shift_id = 1234 FOR UPDATE; UPDATE doctors SET on_call = FALSE WHERE name = ‘Alice’ AND shift_id = 1234; COMMIT; |
利用FOR UPDATE来告诉数据库锁定返回的所有行用于更新
这还是比较简单的,但是比如一个会议室的预定系统,如何实现呢?
因为需要避免时间冲突问题,所以只能进行串行化的隔离级别了。
比如多人游戏,需要确定一个玩家只能操控属于自己的棋子。
对于这种一个用户的更新会影响到另一个用户的情况,称之为幻读,对于幻读这种问题,可以通过锁定公共行来避免写入偏差,SELECT FOR UPDATE
但是对于会议室这种问题,可能存在一开始查询的时候并没有预定信息,也就无法利用SELECT FOR UPDATE来进行,不过我们是否可以人为的在数据中引入一个锁对象呢?
比如为每一个房间按照10分钟为间隔创建接下来7天的占位行
然后在预定的时候直接select for update对应的房间和时间段的行,获取到锁定之后,检查是否有重叠的从而进行插入。
这种方式被称为物化冲突,将幻读变更为一组具体的锁冲突,不过需要交给实现方明确知道如何进行物化冲突,不然还是推荐使用可串行化。
那么对于可串行化,通常默认是最强的隔离级别,可以避免上面说的所有冲突问题,但是由于字面意思是让事务按照顺序进行单线程执行,性能可能降低,所以很少有人使用,不过伴随着技术的发展,串行化的实现也有着不同方案,这次作者就分别讲解不同的可串行化实现方式。
常见串行化实现方式有
1. 直接串行顺序执行
2. 两阶段锁定 2PL
3. 乐观并发控制技术,也被成为可串行化快照隔离
如果是直接进行串行化执行,那么需要注意,单线程意味着单CPU,单CPU直接执行IO操作太慢了,所以最好能够将所有的数据都放在内存中,其次是事务最好只执行关键的读写操作。
关于这个操作,其实很熟悉,在Redis中就有使用。
那么我们就结合Redis来看作者对于可串行化的讲解,Redis本身主要的执行线程就一个,用于进行主要逻辑使用,同时为了优化执行的速度,Redis引入了一个机制,这个机制是为了减少和客户端的交互,将客户端的部分逻辑下放到服务器端,也就是在客户端发出请求的时候,可以提交一些业务代码,在Redis服务器上执行这些代码,从而加快执行速度,减少交互。
Reids就支持Lua脚本一起提交进行执行。
但是需要注意,数据库服务器往往比客户端上的应用服务器对性能更加敏感,所以对脚本中可能存在的大量时间占用,需要注意
除了Reids这种利用代码来加快速度执行,还有这分区的概念,如果可以进行数据分区,那么串行化如果只在一个分区中执行,那么仍然可以在保证事务隔离的基础上加快速度
不过对于访问多个分区的任何事务,数据库可能需要锁定多个分区,所以对于跨分区事务,往往会比单分区吞吐量低上几个数量级。
那么对于直接使用串行化,我们只需要注意,每个事务都小而快,而且数据需要都在内存中,需要避免分区事务。
那么其次是2阶段锁定
2阶段锁定不同于2阶段提交
2阶段锁定类似读写锁,读取之间不冲突,但是写入和读取之间会冲突
读取加上读锁,写入加上写锁,一个事务获得了锁之后,就会持有锁直到事务结束,这就是二阶段锁定,第一阶段获取锁,第二阶段释放所有锁。同时为了避免死锁问题,数据库会自动检测事务之间的死锁并释放。
对于这个2PL可能带来的性能问题,可以说是不稳定的,因为事务之间会进行等待,所以在某些高百分位处的响应会非常的慢,比如一个大事务可能会获取很多的锁,导致系统整体变慢
其次是搭配2PL,还有着一个谓词锁的概念,也就是需要在一个范围上加锁
锁定符合某些搜索条件的对象,这个谓词锁的实现有索引范围锁。
将谓词锁进行扩大,将这个锁加载索引数据结构之上
比如说预定房间的话,如果索引位于room_id之上,那么就可以将索引加在room_id为123的索引项上
或者如果有这时间的索引,则可以将锁加在时间索引上,比如12点到13点上
如果没有可以挂载的范围锁的索引,就会退化到整个表上的共享锁,这就很影响性能了
关于这个next-key lock的实现,可以参考mysql的可重复读。
最后是乐观并发控制,也就是可串行化快照隔离
因为加锁最终是一个悲观并发控制机制,毕竟是无论是否会出现并发,都会在上面加上锁,保证互斥
但是乐观化也是一种实现方式,对于可能存在的危险也不去阻止,而是在提交的时候去检查是否有什么不好的事务发生了,发生了就进行中止并重试。
当然中止并充实会占用额外的性能消耗,但是乐观的角度来看,不出现问题的可能性比出现的可能性多多了。
那么我们聊聊这个可串行化快照隔离的细节,往往一个事务的执行,是先去查询某些东西,根据这个查询结果去执行后续的操作,那么事务最终能不能提交成功,肯定也是依赖于这个前提
那么前提的变更必然来源于两点,要么是读之前就存在着没有提交的写入
要么就是读之后发生了新的写入。只要存在,就必须要回滚并重试。
那么最后再说下可串行化快照隔离的性能
对于可串行化的最大优点就是一个事务不需要阻塞,使得延迟可以预测,只有当出现冲突的时候,才需要进行回滚,这比两阶段锁定来说,加快了不少速度
其次在分区中,由于只有在提交时刻才会检测,所以并不会影响其他事物读取分区的吞吐量,这比串行化执行吞吐量更大。
最终最影响可串行化性能的问题,就是中止率,对于中止率,最好的方式就是要求读写的事务尽可能的短,避免中止事件的发生。
那么总结下本章
事务的出现是为了统一处理 某些并发问题或者一些软件及硬件问题。
所以我们就介绍了事务最重要的特点,ACID
并顺着ACID,我们讲解了读已提交,快照隔离和可串行化这几个隔离级别
之后又讲解了一下竞争条件的例子,来描述这些隔离级别
脏读 脏写 不可重复度 更新丢失 写偏差 幻读
在最后还说明了串行化的集中实现方案,比如就是字面上的串行执行 两阶段锁定 可串行化快照隔离SSI