上一章作者也说了,往往复制是和分区一同使用的,但上一章只是提了不同的复制架构,以及复制问题,把分区问题往后放在了这一章
复制是将数据在不同的节点之间进行拷贝,提高了可用性,而分区,也被称为分片,是一种将大型数据库分解为小型数据库的方式,提高的是吞吐量,这一点在分布式数据库中很常见
比如Elasticsearch HBase Cassandra Kafka等
那么本次我们按照简单的分区,如何实现分区,分区中的索引。以及分区再平衡和查询方式这样的一个步骤进行讲解
首先是分区的实现
往往一个节点会存储多个分区,每个分区可以是主库,也可以是其他节点上主库的从库
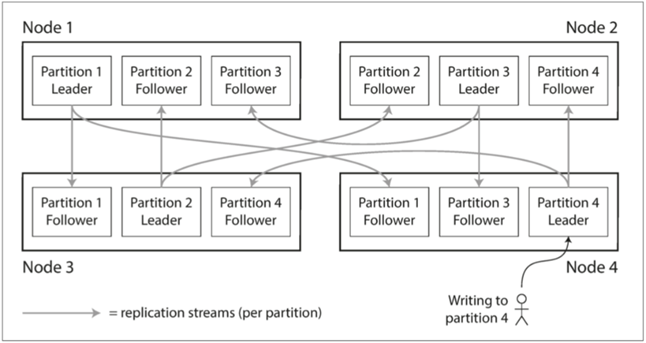
那么这样一个架构下,首先需要考虑的问题,就是数据的分布平衡问题
如果数据分布不公平,那么必然有些分区的数据和查询更多,这种情况称为偏斜,而偏斜的节点就被称为热点
简单点就是随机分配,不过这样会导致无法进行范围性地查询
那么如果是键值型数据库或者文档型,事务性中具有一个主键的话,可以通过键的范围来进行分区
就好比一个字典, a开头在多少页到多少页
不过这种范围分布也无法导致偏斜的问题,也就是会出现热点
后来就是根据散列函数来进行分配,利用散列函数,可以获取一个固定的数字,从而分布在不同的分区上。再配合上面讲述的分区划分来使用,为每一个分区指定一个散列范围,从而确定每一个散列值落在哪个分区上。

不过使用了散列函数进行分区,会导致失去范围查询的能力,于是在Cassarndra中,采用了折中的方式,也就是会选择复合主键中的第一个列作为散列依据,其他的列仍然会在内部存储的SSTables中进行排序,方便进行范围性的扫描
即便使用了hash散列的方式,也不能完全避免热点问题,因为可能存在某一个名人或者某一个热点事件导致的数据写入或者读取的风暴。这种情况由于主键相同,所以哈希策略无法生效。
即使采用诸如主键后面随机增加随机数的方式来避免一个键的大量写入,而是需要对于这些额外增加的后缀进行记录的。而且由于增加了随机的后缀,那么所以在读取的时候,还需要读取所有的子主键进行合并,也并不是最优解。
即便存在着一些瑕疵,但是分区散列的确是分布式数据库在分区时候的首选了
那么有没有什么办法可以在分布式数据库中进行范围查询,或者说给这个加上一个索引呢?
有着和Cassarnda类似的思路,就是在每个分区上维护一个次级索引,比如一个商品按照SKUID进行散列分配,但是搜索的时候往往是按照价格或者颜色进行过滤,这样的话,我们就可以再本地维护一个价格和颜色的次级索引

不过这样的话,每个分区只需要维护自己的次级索引,不关系其他分区的数据
这样的次级索引被称为文档分区索引,或者叫做本地索引
虽然次级索引能够加快查询的速度,但是在搜索的时候,有时还是会进行全局搜索,而且往往搜索会利用多个次级索引。
那么除了这种分区索引,还可以构建一个覆盖所有分区数据的全局索引,当然为了避免这个全局索引过大,不好更新,索引内部可以是进行分区的
比如按照价格,将索引分为0-10,10-50,50-100,100-200等,内部维护了对应的SKUID
这样分区后,虽然写入速度比较慢,但是在查询关键词范围的时候总能加快速度。
之后我们就可以讨论分区再平衡
也就是在节点加入或者节点离开集群的时候进行数据的迁移,
希望在平衡之后,可以让负载在集群中的节点之间公平的共享,并且希望在移动过程中,尽可能的减少移动的数据。
在讲述常见的再平衡策略之前,作者先给出了一个反例,就是避免直接使用hash或者mod的方式进行散列,因为这样涉及迁移的数据量就很大。
其次对于常见的再平衡策略
1. 最常见的是固定数量的分区
也就是每个节点都会被拆分为固定个数的分区,然后将这些分区平均分配给每个节点
这样当一个新节点加入集群的时候,可以让先有的集群节点分别给予一些分区给新节点。
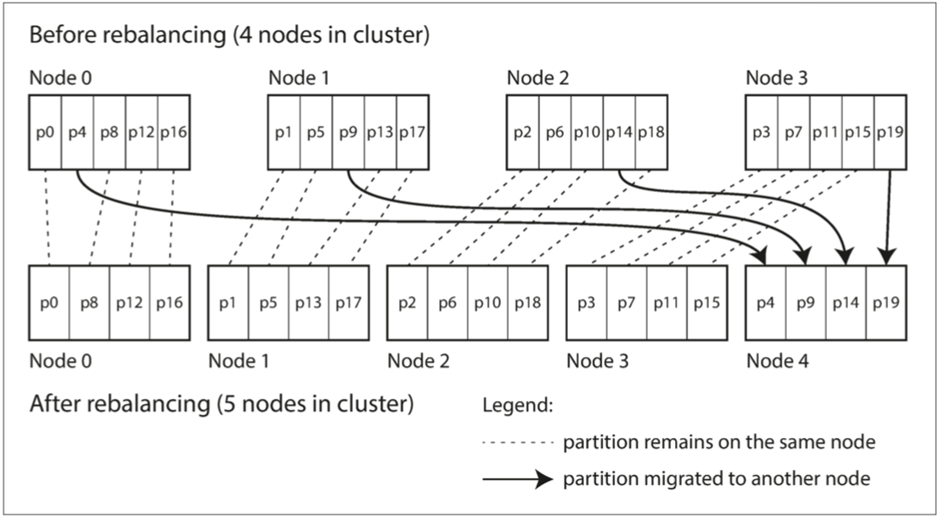
利用固定数量的分区,保证迁移时,迁移的数据大小是固定的
这种架构思想,在ES Riak都有使用。
这种架构下,分区数量在数据库第一次建立时确定,之后不会改变。虽然可以进行分割和合并分区,但是很多数据库都选择不实现分割和合并。这就意味着,合理选择一个分区数就非常重要,非常多的数字意味着多的管理开销,太小意味着迁移数据多。
不过,只要选择大于节点的分区数,那么就可以获取到最佳的性能。
2. 动态分区
对于使用范围分区的数据库,可以考虑在一个分区的数量或者大小达到配置大小的时候,分为两个分区,同理,如果缩小到某一阈值的话,就会合并。
这样,拆分之后,就可以将另一部分转换到另一个节点上,从而维持负载。
动态分区的一个优点就是分区数量会伴随着总数量而增多
但是往往存在着一个问题,就是存在着初始的时候往往只有一个分区,导致负载不均衡的问题
这个问题可以使用预分区的方式进行避免。
3. 节点比例分区
上面说了固定分区,分区大小是和数据集大小成正比的,动态分区,分区数量是和数据集大小成正比。这实际上都和节点数量没有关系
还是有方法使分区数和节点数成正比的,每个节点都固定数量的分区,只是新加入的节点到来的时候,会有老节点将自己的部分数据给新节点上的分区。
保证节点数量和分区数量成正比的。只要避免了分布不平衡问题,这就是一种非常好的解决方式。
最后作者讨论了分区中如何进行请求路由
常见的方案有几种
1. 是客户端访问任意一个节点,节点可以自己处理,也可以转发给有这个数据的节点处理
2. 是客户端发送到一个路由层,或者是代理层,由其负责处理这个请求
3. 客户端知道分区和节点之间的分配,这样其直接连接到适当的节点。
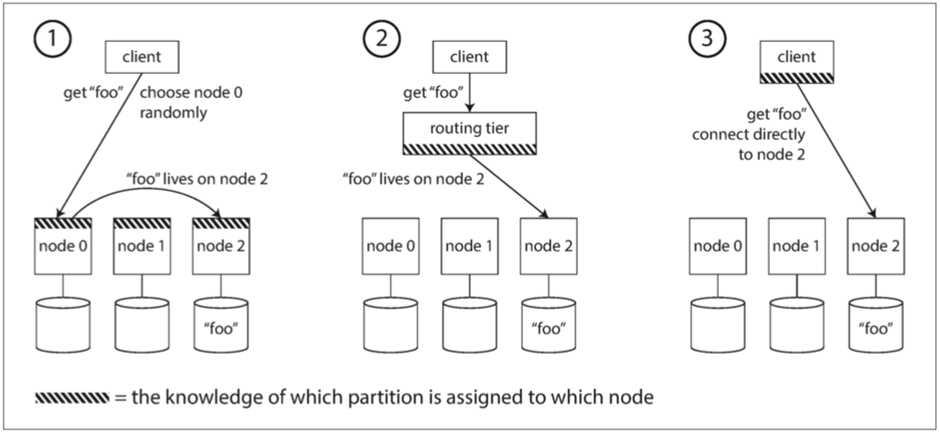
上面无论哪种实现,都有着一个问题,就是如何确定分区和节点之间的关系变化。
很多分布式系统都依赖于一个独立的协调服务,比如ZooKeeper来跟踪集群元数据
每个节点都在ZK中注册自己,交给ZK维护分区到节点的映射
然后参与者可以在ZK中订阅这些信息,无论是客户端还是路由层。这样无论添加还是删除一个节点,都会通知路由层使路由信息保持最新状态。
当然也存在着类似Cassandra的处理方式,利用流言协议来传播集群状态的变化。
那么总结下本章
本章中,我们探讨了将大数据分区的概念,数据量非常大的时候,单个机器上直接复制时不可行的,分区还是有必要的。
那么这一章,首先探讨了关于分区的方式,首先是键范围分区,然后是散列分区,利用散列,似的更均衡的分配负载
并接着讲述分区的区别,讲述了如何利用索引来加速查询,索引也分为了本地索引和全局索引
最后再说了分区再平衡的概念和查询路由的实现。