这一章,作者讲述了在传递过程中,不同的数据编码的区别,在早期,作者提出关于数据的兼容性的考虑。
传统数据库,如果是关系型的数据库,那么往往是具有写模式的,这样在修改数据格式的时候需要进行诸如Alter的修改,其次是NoSQL中常见的读模式,更加灵活,写入的时候不会强制一个模式。
但抛开写模式还是读模式之外,对于一个存在迭代的项目中,都需要考虑双向兼容性
向后的兼容性,即新代码可以读取旧数据
向前的兼容性,即旧代码可以读取新的数据
一般来说正常开发都会考虑向后兼容,但是向前兼容比较棘手,那么这章的主线就是讲述不同的编码格式如何应对向前兼容。
首先是为何存在编码格式,对于数据来说,往往在内存中的存储格式和在磁盘或者网络中展示的格式是不一样的,为了从内存转换到字节系列,称为编码,反过来称为解码。
虽然很多语言,比如Java,GO都提供了自己的编解码格式,但是往往这类编解码方式是和语言强绑定的,所以很难和其他系统进行兼容。
其次效率低下,比如Java内置的序列化性能就及其底下。为此发展出了独立于语言外的编解码格式
常见的有JSON和XML,除此外还有些二进制的编解码方式,以及不常见的CSV(因为没有模式,类似Excel)
首先我们看看JSON和XML,两者都具有可读性,而且上手使用简单
但是也存在一些微妙的问题,比如数值,对于XML和CSV,无法区分数字和字符串,JSON则是无法区分整数和浮点数
其次是JSON等不支持二进制数据,导致数据没法很好的缩小。但抛开这些小问题,仍然是一个开箱即用的优秀格式。因为是读模式,本来就支持读模式。
之后还有些通用的二进制编码可以使用。
为什么出现了二进制的编码格式,这是因为JSON和XML虽然易读,但是毕竟还是文本格式,相比较二进制来说还是太占空间,一旦数据达到TB级别,数据选型就很重要
这就出现了二进制的编码格式
首先是MessagePack,是JSON提供的二进制编码格式
其是按照顺序进行二进制化,比如下面的图
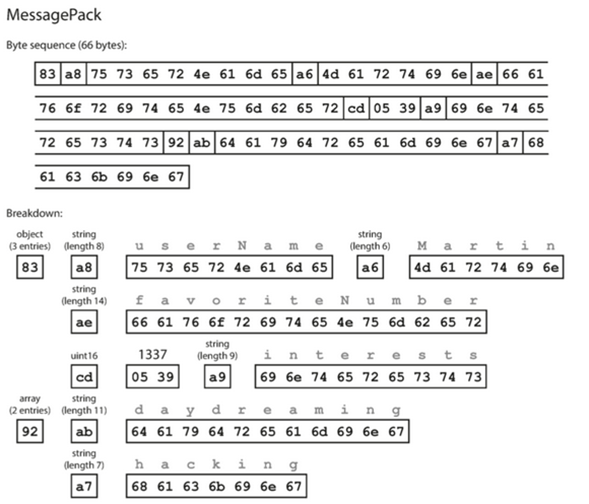
这个实现是通过声明类型,加上键的长度,加上键的名称,加上值的长度,加上值来进行的二进制化。
这种能够减少不少的内存消耗
类似的还有Thrift和Protocol Buffers,都是类似格式的二进制编码,两者格式如下
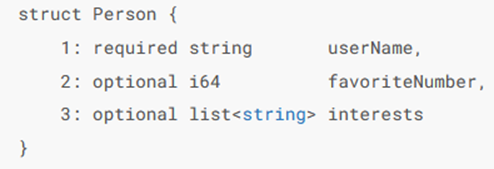
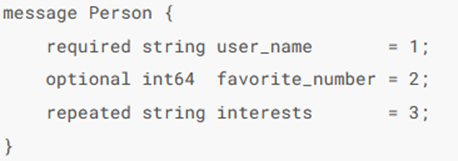
这里的重点在于,每一个字段前面都有一个整数标识,这样在存储的时候只需要存储对应的字段数字就可以了,就跟别名一样,在存储值的时候,只需要存储值的类型,值对应的键别名,实际的值
那么二进制如何支持向前向后兼容的呢?
上面两者的二进制编码中都包含着标签号码,这个标签号码的作用很大,用于存储实际的值,这就意味着标签号码不能修改,利用这个标签号码,我们可以进行向前向后兼容,如果是新的代码可以读取旧的数据,如果是旧的代码,那么因为标签号码不会变,那么也还可以继续读取。而删除一个字段,也必须要保证这个标签不会被再次利用。
但需要注意,因为是读模式,所以变更数据类型是具有风险的,比如一个32位整数,转换为64位证书会存在填零的问题,如果是64位转32位,则存在一个截断的问题。
而且对于数组,对于Protobuf,则是存在一个标记是不是重复字段,如果后期加上重复标记
那么老代码会存在只读取列表最后一个元素的问题。
之后说了一种Hadoop中的二进制实现方式
一个常见的对象使用Avro 编写格式如下

转换为二进制的话,则是和上面的二进制方式不一样,没有任何标记字段和数据类型
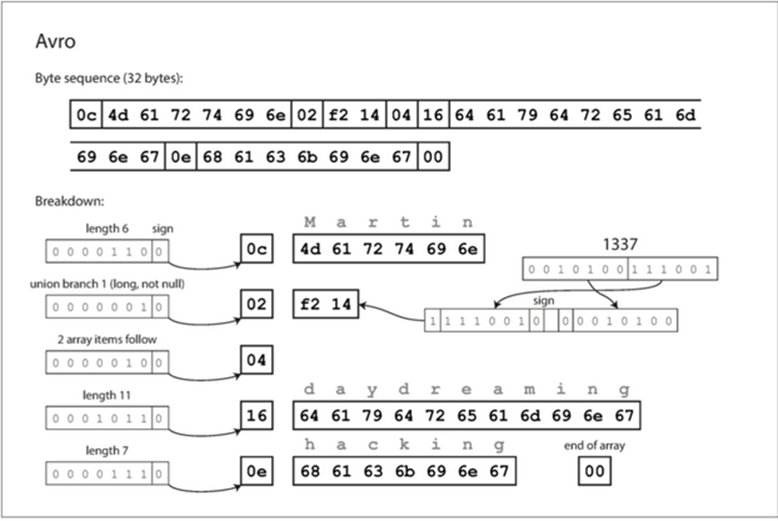
那么Avro如何进行的读取和写入的呢?Avro分为了Reader和Writer模式
Writer模式用于编码数据,Reader模式用于解码数据
Avro库会并排查看Writer模式和Reader,利用两者来解决差异。
因为会在读取数据的时候查看Writer模式,那么对于Reader不存在的字段,直接忽略,如果Writer中不存在的字段,就利用Reader中的默认值填充。
利用读取端同时用于Writer和Reader模式,Avro来做到了向前向后兼容
为了保证兼容性,只能考虑能添加或删除具有默认值的字段,假如添加了一个有默认值的字段,那么新的Reader无法读取老的Writer的数据,毕竟无法去给这个没有数值的字段赋值的
如果要删除一个没有默认值得字段,旧Reader无法读取新的Writer写入的数据
上面我们看出来了,因为解码端可以同时拿到Reader和Writer模式,所以Avro中的数据压缩是最狠的,但是Reader如何知道Writer模式的呢? 如果是每次发送都携带着Writer, 对于某些小数据场景,是很得不偿失的。
那么常见的场景就有
很多大文件,这样发送一次发文件,就可以只包含一次Writer模式,或者将Writer模式保存在数据库中并利用版本号来进行保存。
那么对比不同的数据编解码格式,JSON和XML支持更加详细的验证规则
其他二进制的模式,则是存储轻便, 除此外还有些专门的二进制编码,比如上面说的avro,比如jdbc链接。
再说了在数据发送端和接收端的编解码方式之后,我们还需要说数据在不同系统之间传输的方式
比如数据库中的数据流
写入数据库需要对数据进行编码,读取的时候需要进行解码
但是数据库的访问客户端版本并不能确认,有的版本新,有的版本旧
这就最好要求数据库对模式具有兼容性,比如加入一个字段,像是关系型数据库中添加一个带有默认值的行,在读取老数据的时候,就会默认填充控制,但是如果删除了某一个行,那么老代码读取就会出现错误,所以常见的还是添加字段,而非删除字段,为了保证向前向后的兼容性
然后对于最为常见的网络传输
这一点可以有Web客户端向服务器发出请求,也可以是服务器作为客户端向另一个服务器发出请求。
服务类似数据库,但是限制了客户端的提交,必须要按照一个特定的业务逻辑进行调用,来获取预定的输入和输出。
比如使用Web进行调用,常见的有REST和SOAP
REST是一种设计哲学,强调的是使用简单的数据格式,使用URL来标记资源,使用HTTP本身功能进行业务处理,比如认证等,也是现在的主流处理方式,根据REST原则设计的API成为RESTful
SOAP是用于制作网络API请求的基于XML的协议,虽然使用在HTTP上,但是除了基础的HTTP功能,其他基本不使用。SOAP Web服务的API使用成为WSDL的XML语言来进行描述,但是WSDL不是为了人类可读设计的,是依赖于工具支持。由于这种复杂性,所以在很多小公司中不流行。
Web服务通常都是利用网络进行的API请求,大多基于了RPC远程过程调用的思想,通过试图向着远程网络服务发出请求,来模拟在同一个的进程中调用函数的方式。但只要稍微的想上那么一想,就知道这是不可能的,毕竟本地函数调用具有可预测性的,而网络不具有预测性,而且需要考虑网络出现异常的情况下的重试机制。重试就要考虑幂等问题。而且还有着客户端和服务端之间的语言不一样的问题,不兼容性。
虽然有着这样那样的问题,但是RPC还是具有很高的吸引性,实现有Thrift自带的PRC,或者gRPC的Protocol Buffers实现。
但是RPC往往还是直接对内使用,比如一个数据中心,或者一个多节点服务中使用,而对于公共API,还是REST风格的更普遍。
对于可演化性,RPC的实现主要可以从兼容性属性来看,兼容性属性可以从使用的编码方式中继承:
Thrift,grpc等实现利用了原本编码格式的向前向后兼容性
SOAP,因为是利用XML模式指定的,这里直接略过
RESTful API最常见的利用JSON进行响应,所以增加新的字段没有问题
而且在服务的外部,存在不同的版本逻辑的话,则可以利用HTTP的请求头或者URL路径来进行控制。
最后我们说下消息代理,最常见的实现就是消息队列这样的中间件
这种消息代理的特点有,可以进行解耦,自动进行重复消费等
常见的实现由Kafka RabbitMQ等,在这类消息代理中,不会对消息本身进行任何的修改,也就是不具有任何特定的数据模型,而可以使用任意的字节序列方式。这就将向前向后的兼容性交给了编码格式。
作者最后也提了一嘴Actor,但说的比较少,这里我们也就直接略过了。
总结一下本章,我们主要说了,数据为了在不同服务器之间进行传递,具有了编码和解码的功能。
通过讲述向前向后的兼容性,从JSON到二进制进行了一次疏通。
比如JSON,XML都具有较好的向前向后的兼容性,但是有些小问题,比如数据类型比较模糊
像是二进制格式编码后较小,而且具有向前向后的兼容性,但是在数据柯渡之前需要进行解码
最后简单说了数据流的几种模式
对于数据库来说,虽然在某一节点对外表示为一个单一模式,但是也提供了向前的兼容性
RPC和REST API,则是利用了JSON等编码格式进行了兼容性支持
最后是异步消息传递,节点之间通过发送消息进行通信,消息本身不改变,还是依托在消息编码格式上。