上一章跟随者作者的思路,去查看了不同的数据存储模型,关系模型,文档模型,图模型
那么这一次我们更为上层的来看数据库,并探讨数据库存储数据的方式,和查找的方式
也就是从数据库内部存储和检索的角度出发,来探讨什么场景适合什么样的数据库
那么在开始之后,作者首先展示了日志的概念,说明了为了快速的增加保存数据,日志往往是一个仅仅追加数据的文件。
其次是为了增快在日志中查找数据的速度,引入了新的数据结构 索引,索引是一个需要额外维护的结构,这意味着虽然增快了查找速度,但是索引也需要拖慢写入速度,并且占用了额外的存储空间。
那么说明了日志和索引之后,假设有一个简单化的数据库,其存储结构是一个文档,索引是一个散列表(字典)一样的数据结构。
比如JSON,每个键都录入到上面的字典索引中,值就是在日志中的偏移量,从而做到读取的时候直接seek指针位置去读取。
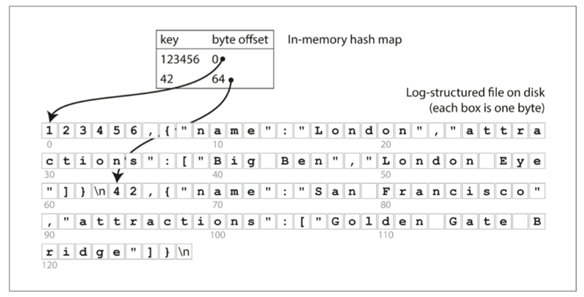
但是这样维护的字典索引,因为需要经常更新,所以往往需要加载到内存中。而如果不做限制内存迟早撑爆, 硬盘同样也是,所以为了减少加载数量,将日志分为了特定大小的段 segment 当一个段大小达到一定的数量的时候,生成新的段,并且还提供了对之前段的压缩和合并功能,比如Kafka,作为消息系统,就是这么做的。

对于散列表加上多段日志的组合,需要注意一些问题
比如日志的格式需要特定,比如采用二进制的方式进行存储
删除某一键的及其相关联的值,可以在其中追加一个新的删除记录,当合并的时候,就会读到这个要删除的键值进行丢弃
其次为了索引方便重启后的恢复,索引也需要进行相关的落盘存储。
那么看了散列表,其实会发现有一个非常重大的问题,就是对于范围查询的支持不够好。
后来于是发展出了SSTable, LSM树
如果我们要求在每一个日志段内,键的顺序是一定的,因为有序,所以键还会顺带进行去重,加上之前所说的日志段生成方式,一个日志段内的所有数据都晚于前一个日志段的数据.
这样的一个格式就被称为 排序字符串表 Sorted String Table,也就是SSTables。
那么SSTable也可以进行数据的去重合并
而且搜索的时候,可以利用有序这个概念,快速查询某一段的范围
那么这样的SSTables就是RocksDB和LevelDB使用到的技术
其做到了新数据写入的时候,先写到一个内存表,当内存表大于了某个阈值之后,就写到磁盘中,磁盘中的数据会不定期的合并和压缩。收到读取请求的时候,会在内存表中查找,命中不到则不断的在磁盘中寻找。这种索引结构被称为LSM树。
最后,关于这样的LSM,作者还解答了两个可能出现的问题,一种是对于文档查询,因为内存只保存当前键的信息,对于存储在硬盘中的键信息,还需要去读取硬盘,这时候,引入了额外的布隆过滤器。
其次是SSTables的合并压缩的顺序,分别存在size-tiered和leveled compaction
size-tiered是将新的和小的SSTables相继合并到较大和较老的SSTables,对于leveled compaction则是会不断拆分到较小的SSTables,并不断下移到老的层级。
上面说了NoSQL中广泛使用的一种存储方式,对于关系型数据库,最常见的日志结构索引还是B树
B树会把数据库分解为固定大小的块或者页面,一次读取写入一个块,结构如下
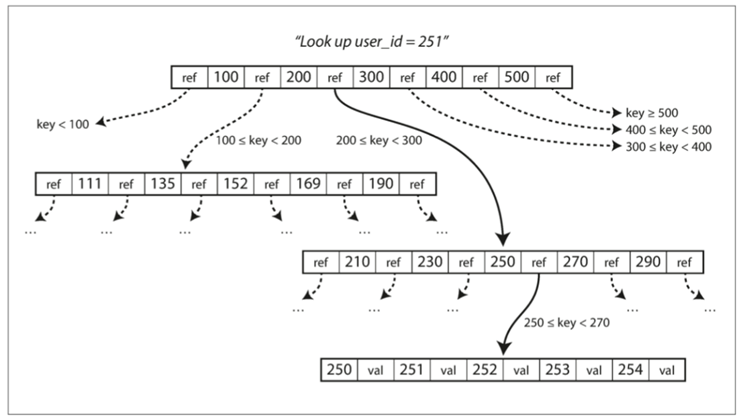
那么在这个B树种搜索一个键的时候,就是不断的查找子页面,直到命中了某一子页面
同时添加一个新的键的时候,可能会导致一个子页面已经满了,从而分为两个半满页面
而且在这样的一个数据结构中,为了增强可靠性,还引入了新的额外存储结构, WAL 预写式日志,一个仅追加的文件,利用这个日志文件,来避免异常崩溃后的数据丢失。
除此外,有些新的设计来去优化B树,比如
一些数据库使用了写时复制的概念,修改的页面在确认修改完成后,会替换原本树上的指针
或者在这个树上存储一个前缀来增大每一个页面上存储的键数量,从而减少层级,但是这种的存储方式也增加了在每一个页面上的搜索数量(后来才发现,原来原文想要描述的是B+树)。
以及将页面尽可能的在硬盘中相邻,方便查询时候,尽可能的减少硬盘指针的移动
或者在每个叶子页面上增加左边和右边兄弟页面的指针,方便范围扫描时的查找。
之后作者比较了B树和LSM数的区别
LSM树的优点在于写入速度非常快,避免了B树的二次写入,故吞吐量更大,而且借助不定期的压缩,往往存储更加的紧凑,文件更小
但是LSM也存在两个问题,一个是写入和压缩的比例,一个数据库在早期没有数据的时候,可以全量写入,但是在数据库变大的时候,如果压缩跟不上写入,会导致磁盘空间不断膨胀,其二读取速度会变慢,因为需要检查更多的段文件。而B树由于键在存储结构上的唯一性,导致始终如一。
而且由于LSM中存在多个段文件,所以不能像B树结构一样,做到良好的事务隔离。
最后讲述了下聚集索引和非聚集索引,聚集索引就是将索引的数据直接存储在索引中,非聚集索引则可以通过存储一个引用来指向实际数据。
以及多列索引
多列索引就是将多列的值组成一个键来进行存储,方便通过列值得前缀进行匹配。比如提供了一个姓名,名字的多列索引,查询姓名加上名字是可以查询到数据的,但是单查询名字是不太可行的,因为必须要要带有前缀才能查询。
在之后,现在对于数据存储的方式,伴随着RAM的成本降低,开始出现了将数据完全写到的内存的数据库类型,比如Memcached,其将数据完全放入内存,并将更改日志写入到硬盘中。
需要注意一旦,内存的优势并不是不需要从硬盘读取,因为传统数据库也会利用内存进行加速,内存数据库的优势在于使用了独特的内存数据结构,并且避免了转换为硬盘数据结构的开销。
本章下一个重点是对比了分析性数据库和事务性数据库,本质上看就是数据仓库和传统型数据库的对比。
这里的事务性数据库,并不是代指ACID,而是指的传统业务中,用户操作会涉及数据库的少量数据,这些数据会伴随着用户操作进行修改。因为是交互式的,所以被称为在线事务处理
而数据仓库也是比较常见,将大量历史数据放入一个数据库中,通过分析师书写相关的分析查询扫描大量数据,统计出最终结果,这种被称为在线分析处理
关于在线事务处理 OLTP 和在线分析处理 OLAP,之间的差距可以体现在
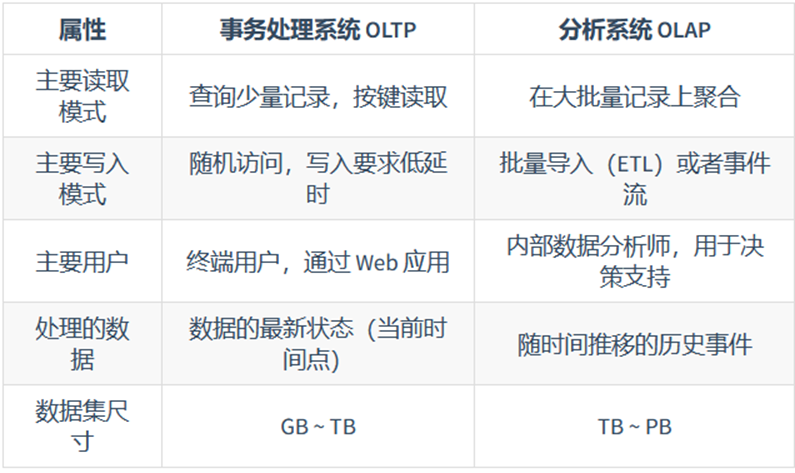
早期对于两者,使用了相同的数据库,
但是不断的进化过程中,对于OLTP,还是不断地设计特定的数据库系统。
并且通过从传统数据库中提取数据,转换格式,加载到数据仓库中,这一个过程,我们称为抽取-转换-加载ETL过程。
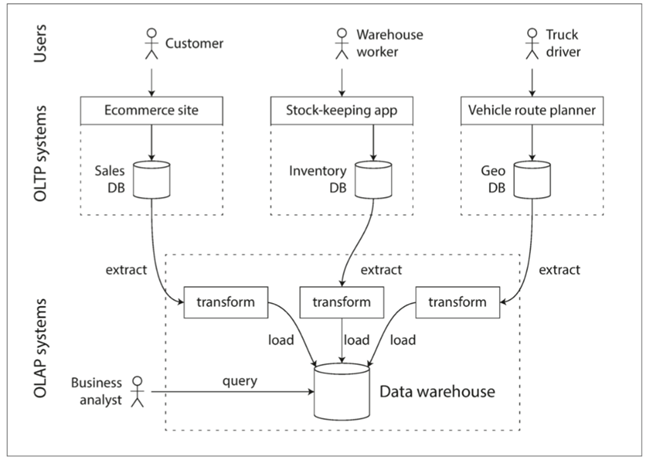
即使后来分家了,两者还是都采用SQL进行分析查询只不过OTLP会针对数据的分析查询进行了特别优化,常见有Hive Spark Persto数据库。
而在分析性数据库中,应用的数据模型,还是常见的星型模式,就是在数据库仓库中,以某些特定的事实表为中心,这个事实表可以是产品购买表,可以是用户的浏览表。围绕着这个事实表,配合不同的维度表来进行展示。
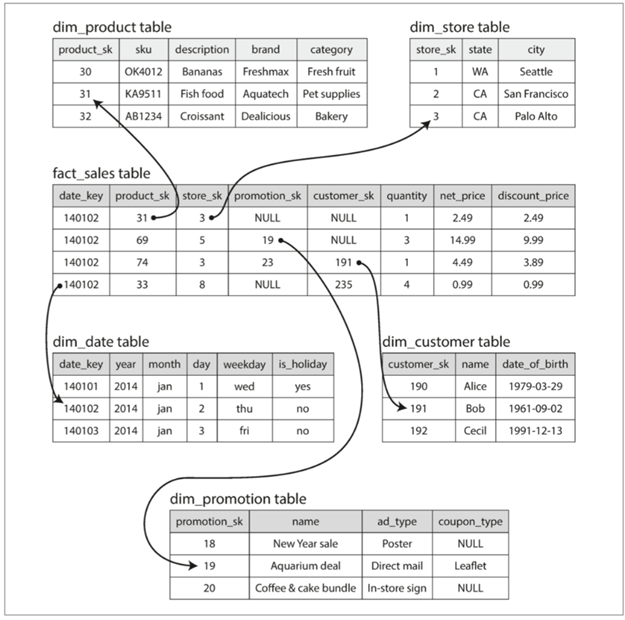
这样的一个模式被称为星型模式,除此外我们还说他的变体雪花模式,维度被进一步的分解为了子维度,雪花模式比起星型模式更加的规范,但是星型模式仍然是首选,毕竟分析师使用起来更加简单。
在本章的最后,作者讲述了在数据分析方向上常见的一种存储格式,
列式存储,因为在数据分析方向上,一个事件表中常用的行并不多,往往一次查询只会访问其中几个列
那么在存在大量文件扫描的情况下,以列存储的方式似乎很适合这个场景
如果是将每一列的值存储在一起,那么是否在查询的时候,只需要读取并解析查询中使用的列就可以了

但需要注意,列式存储布局需要每个列文件中都包含相同顺序的行,即按照一个固定的顺序进行排列。
在此之上还可以使用列压缩功能,不过个人觉着这并不是这个思想的重点,也就不展开了。
仍然沿着排序的思路进行走,因为列式存储需要按照一个固定的顺序统一,简单点可以是新数据追加到列文件的最后,但由于往往一个列文件是无法存得住所有的数据的,所以拆分文件是必然的,伴随着文件数量的增加,如果想要去搜索某个范围,那速度将变得极为缓慢
那么不如使用几个特定的列来进行排序,如果查询经常以日期为目标,那么可以将date_key,对于date_key相同的行,可以利用第二排序行进行排序,比如第二是商品id, 这样就可以使用特定的日期,特定的商品进行查询
同样的一种优化方式,就是将一份数据以不同的排序顺序存储多次,这样就在查询的时候,选择最适合的查询版本,其次是当某一硬盘发生故障的时候,不会丢失数据。
那么有了多级排序之后,如何去讲数据加载到数据仓库中呢?
其实还是可以延续之前的LSM树的概念,将写操作写入一个内存存储,先在内存中排序,然后写入磁盘,在写入磁盘的时候,和磁盘的文件进行合并。
最后作者说明了,在数据库中,存在着一个特殊的对象,即为视图,也就是对于常见的计算逻辑,比如Count SUM AVG MIN MAX都可以提前进行聚合,方便后面的查询
那么这样的计算逻辑,就是视图,当数据库有新数据写入得时候,就会自动完成更新,不过这样成本很高。
所以很不常用。
总结一下本章,我们了解了数据库如何处理存储和检索的
从散列表开始,讲述了SSTables的原理,这是很多NoSql的底层实现。
其次是讲述了事务性数据库和分析性数据库的区别,强调了在分析型数据库中,B树的存储方式和LSM存储的方式
最后讲述了列存储的方式,将LSM和列存储结合来看,加快在数据分析中的查询速度。
借助本章,我们可以了解并更好的在使用过程中抉择不同工具。